本篇内容主要讲解“Python怎么爬取软科世界大学学术排名”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Python怎么爬取软科世界大学学术排名”吧!
Python 3.8
Spyder
#爬取软科世界大学学术排名
import requests
from bs4 import BeautifulSoup
if __name__ == "__main__":
destinationPath = "html信息.txt"
allUniv = []
# headers={'User-Agent':'Mozilla/5.0'}
url= 'https://www.shanghairanking.cn/rankings/arwu/2020'
try:
r = requests.get(url=url, timeout=30)
r.raise_for_status()
r.encoding = 'utf-8'
html = r.text
except:
html = ""
# fd = open(destinationPath,"w+") # 注意这里会报错:UnicodeEncodeError: 'gbk' codec can't encode character '\xa9' in position 0: illegal multibyte sequence
fd = open(destinationPath,"w+",encoding='utf-8')
fd.writelines(html)
fd.close()
# print(html) # 注意在vscode下这里打印不全,故将结果保存在文件中
soup = BeautifulSoup(html, "html.parser")
# fillUnivList(soup)
# printUnivList(10)
print("{0:{5}<10}{1:{5}^10}{2:{5}^12}{3:{5}^10}{4:{5}^10}".format("排名","学校名称","国家","排名","总分",(chr(12288))))
data = soup.find_all('tr')
for tr in data: # 每一行,对应每一个学校
ltd = tr.find_all('td')
if len(ltd)==0:
continue
singleUniv = []
# UniName = tr.find('a')
# singleUniv = [UniName.string]
for td in ltd:
if td.find("a"):
UniName = td.find("a").string
singleUniv.append(UniName)
elif td.string.strip():
singleUniv.append(td.string.strip())
allUniv.append(singleUniv)
# print(singleUniv)
# num = len(allUniv)
num = 30
for i in range(num):
u=allUniv[i]
print("{0:<10}{1:{5}^20}{2:{5}<10}{3:{5}^4}{4:^33}".format(u[0],u[1],u[2],u[3],u[4],(chr(12288))))#排版原因,实为一行
print("{0:{5}<10}{1:{5}^10}{2:{5}^12}{3:{5}^10}{4:{5}^10}".format("排名","学校名称","国家","排名","总分",(chr(12288))))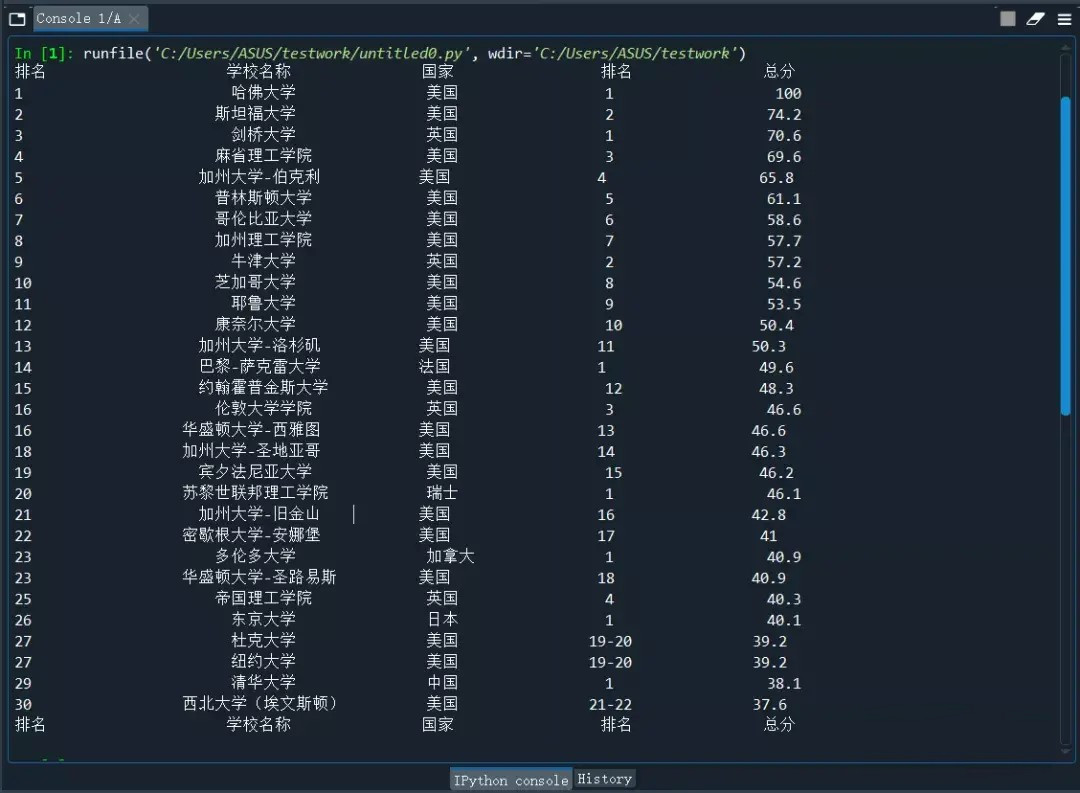
到此,相信大家对“Python怎么爬取软科世界大学学术排名”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





