这篇文章主要介绍“python模拟朴素贝叶斯程序举例分析”,在日常操作中,相信很多人在python模拟朴素贝叶斯程序举例分析问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”python模拟朴素贝叶斯程序举例分析”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
朴素贝叶斯思想:运用了条件概率公式P(Y,X) = P(Y)P(X|Y)。由样本分别求得P(Y)和P(X|Y),进而估计出在X条件下Y的概率。不同Y对应的概率的最大值就是我们想要的X的分类。换句话说,我们想要知道X的分类,那么通过样本求出不同类别(即不同Y)时的P(Y)和P(X|Y),然后计算X发生条件下,可能类别Y的概率,最大的概率就是我们预测的概率。
注意,通常X对应很多分量,X=(X1,X2,······)。这时候贝叶斯估计假设:用于分类的特征在类确定的条件下是条件独立的。所以上面的P(X|Y)计算公式为:
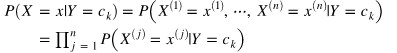
朴素贝叶斯代码的实现
import numpy as np
import pandas as pd
import math
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
class NaiveBayes:
def __init__(self):
self.model = None
# 数学期望
@staticmethod
def mean(X):
return sum(X) / float(len(X))
# 标准差
def stdev(self, X):
avg = self.mean(X)
return math.sqrt(sum([pow(x - avg, 2) for x in X]) / float(len(X)))
# 概率密度函数
def gaussian_probability(self, x, mean, stdev):
exponent = math.exp(-(math.pow(x - mean, 2) /
(2 * math.pow(stdev, 2))))
return (1 / (math.sqrt(2 * math.pi) * stdev)) * exponent
# 分类别求出数学期望和标准差
def summarize(self, train_data):
a = list(zip(*train_data))
summaries = [(self.mean(i), self.stdev(i)) for i in zip(*train_data)]
# *train_data将train_data拆分成n个一维数组
# 再将这个一维数组压缩在一起。
# 注意:这里压缩的时候,一共压缩成了四个一维数组,
# 即每个原数组的第一维进行压缩,每个原数组的第二维进行压缩······
# 然后分别对四个一维数组进行求均值和标准差,即对四个特征求响应的数字特征
return summaries
# 处理X_train,y_train
def fit(self, X, y):
labels = list(set(y)) # set将y删除掉重复的,list将set结果转成列表。这里labels=[0.0, 1.0]
data = {label: [] for label in labels} # 转成字典。输出{0.0: [], 1.0: []}
for f, label in zip(X, y):
data[label].append(f) # 将上面的字典添加属于这个类的值。即类型是label的f
self.model = {
label: self.summarize(value) for label, value in data.items()
# 从上述字典中,一个label及其对应的属于这个label的数据,进行数字特征的计算
# 结果格式: {0:[(均值, 标准差), (均值, 标准差), (均值, 标准差), (均值, 标准差)],
# 1: [(均值, 标准差), (均值, 标准差), (均值, 标准差), (均值, 标准差)]}
# 0后边的四项分别对应:label是0的样品的四个特征的均值和标准差
}
return 'gaussianNB train done!'
# 计算概率
def calculate_probabilities(self, input_data):
probabilities = {}
for label, value in self.model.items():
probabilities[label] = 1
for i in range(len(value)):
mean, stdev = value[i]
probabilities[label] *= self.gaussian_probability(
input_data[i], mean, stdev)
return probabilities
# 类别
def predict(self, X_test):
label = sorted(
self.calculate_probabilities(X_test).items(),
key=lambda x: x[-1])[-1][0]
return label
def score(self, X_test, y_test):
right = 0
for X, y in zip(X_test, y_test):
label = self.predict(X)
if label == y:
right += 1
if right / float(len(X_test))==1.0:
return "perfect!"
else:
return right / float(len(X_test))
def create_data():
iris = load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100, :])
return data[:, :-1], data[:, -1], df
X, y, DF = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
model = NaiveBayes()
model.fit(X_train, y_train)
print(model.score(X_test, y_test))结果比较理想
直接运用sklearn中现有的包进行模拟
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import BernoulliNB, MultinomialNB # 伯努利模型和多项式模型
# data
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = [
'sepal length', 'sepal width', 'petal length', 'petal width', 'label'
]
data = np.array(df.iloc[:100, :])
return data[:, :-1], data[:, -1]
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = GaussianNB()
clf.fit(X_train, y_train)
print("GaussianNB:")
print(clf.score(X_test, y_test))
print(clf.predict([[4.4, 3.2, 1.3, 0.2]]))
clf2 = BernoulliNB()
clf2.fit(X_train, y_train)
print("\nBernoulliNB:")
print(clf2.score(X_test, y_test))
print(clf2.predict([[4.4, 3.2, 1.3, 0.2]]))
clf3 = MultinomialNB()
clf3.fit(X_train, y_train)
print("\nMultinomialNB:")
print(clf3.score(X_test, y_test))
print(clf3.predict([[4.4, 3.2, 1.3, 0.2]]))输出结果
GaussianNB: 1.0 [0.] BernoulliNB: 0.4666666666666667 [1.] MultinomialNB: 1.0 [0.]
可以看到,高斯模型和多项式模型较好的进行了预测,但是伯努利模型预测结果较差。
原因:数据不符合伯努利分布。
到此,关于“python模拟朴素贝叶斯程序举例分析”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





