这篇文章主要介绍“通过重写hashCode()方法将偏向锁性能提高4倍的方法步骤”,在日常操作中,相信很多人在通过重写hashCode()方法将偏向锁性能提高4倍的方法步骤问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”通过重写hashCode()方法将偏向锁性能提高4倍的方法步骤”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
上周在工作中我提交了对一个类的微小改动,实现了toString()方法,让日志更容易理解。令我吃惊的是,这个变动导致类的单元测试覆盖率下降了5%。我知道所有的新代码都被现有测试所覆盖。那么是哪错了呢?在比较覆盖率报告的时候,一个眼尖的同事注意到hashCode()在变更前被测试覆盖,而变更后却没有。这就说得通了:默认toString()方法调用了hashCode()方法。
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}在重写toString()之后,自定义hashCode()不再被调用。我遗漏了一项测试。
每个人都了解toString()方法,但是……
默认hashCode()方法的所返回的值叫做标识散列码(identity hash code)。从现在开始,我将使用这个术语来区分它与重写hashCode()方法返回的散列码。注:即使类重写了hashCode(),你仍然可以通过System.identityHashCode(o)来获得对象o的标识散列码。
使用内存地址的整型表示作为标识散列码是常识,也是J2SE文档所暗示的:
……通常是通过将对象的内部地址转换为整数来实现的,但这种实现技术并非Java编程语言所要求。
尽管如此,看起来还是有问题的,因为方法约定要求:
在Java应用程序执行期间,在同一对象上多次调用hashCode()方法时,hashCode()方法必须返回同一个值,无论调用的时机如何。
考虑到JVM会重新定位对象(例如在由晋升或压缩导致的GC周期中)。在计算对象的标识散列码之后,我们必须能以某种方式重新得到这个值,即使发生了对象重定位。
一种可能性是在第一次调用hashCode()时获取对象的当前内存位置,然后和对象一起保存,比如保存到对象头。这样即使对象被移动到不同的位置,它仍然留有最初的标识散列码。这种方法的一个隐患是:它无法阻止两个不同对象具有相同的标识散列码。但Java规范允许这种情况发生。
最好的确认方法是查看源代码。不幸的是,默认的java.lang.Object::hashCode()是一个本地方法。Listing 2: Object::hashCode是本地方法
public native int hashCode();要注意的是,标识散列码的实现依赖于JVM。因为我只讨论OpenJDK源代码,所以我提到JVM时,总是指OpenJDK这一特定实现。代码链接指向代码仓库的Hotspot子目录。我认为这份代码中的大部分也适用于Oracle JVM,当然在个别地方可能(实际上)是不同的(稍后会详细介绍)。
OpenJDK定义了hashCode()入口点,在源代码src/share/vm/prims/jvm.h和src/share/vm/prims/jvm.cpp中:
508 JVM_ENTRY(jint, JVM_IHashCode(JNIEnv* env, jobject handle))
509 JVMWrapper("JVM_IHashCode");
510 // as implemented in the classic virtual machine; return 0 if object is NULL511 return handle == NULL ? 0 : ObjectSynchronizer::FastHashCode (THREAD, JNIHandles::resolve_non_null(handle)) ;
512 JVM_ENDidentity_hash_value_for也调用了ObjectSynchronizer::FastHashCode(),前者被其他一些地方(如System.identityHashCode())调用。
708 intptr_t ObjectSynchronizer::identity_hash_value_for(Handle obj) {
709 return FastHashCode (Thread::current(), obj()) ;
710 }有人可能简单的认为ObjectSynchronizer::FastHashCode()的做法类似:
if (obj.hash() == 0) {
obj.set_hash(generate_new_hash());
}return obj.hash();但实际上它是包含上百行代码、看起来复杂得多的函数。不过我们可以发现一些“如果没有则生成”(if-not-exists-generate)代码,比如:
685 mark = monitor->header();
...
687 hash = mark->hash();
688 if (hash == 0) {
689 hash = get_next_hash(Self, obj);
...
701 }
...
703 return hash;这似乎证实了我们的假设。现在让我们暂时忽略管程(monitor),只要知道它可以提供对象头。对象头保存在变量mark中。mark是指向markOop实例的指针,markOop表示位于对象头中低地址的标记字(mark word)。因此hashCode()的算法是:尝试得到标记字中记录的散列码。如果没有,用get_next_hash()生成一个,保存然后返回。
如我们所见,散列码由get_next_hash()生成。这个函数提供了6种计算方法,根据全局配置hashCode选择使用哪一个。
使用随机数。
基于对象的内存地址计算。
硬编码为1(用于测试)。
从一个序列生成。
使用对象的内存地址,转换为int类型。
使用线程状态和xorshift结合。
默认方法是哪一个?OpenJDK 8使用了方法5,依据是global.hpp:
1127 product(intx, hashCode, 5, \
1128 "(Unstable) select hashCode generation algorithm") \OpenJDK 9使用相同的默认值。查看以前的版本,OpenJDK 7和6都使用了第一个方法:随机数。
所以,除非我找错了源代码,否则OpenJDK中默认hashCode()方法的实现,和对象内存地址无关,至少从OpenJDK 6开始就是这样。
让我们回顾几个之前没有考虑的地方。首先ObjectSynchronizer::FastHashCode()似乎过于复杂,使用了超过100行代码来执行我们认为是平凡的“得到或生成”(get-or-generate)操作。第二,管程是什么,它为什么拥有对象头?
查看标记词的结构是一个取得进展的好的起点。在OpenJDK中,它是这样的:
30 // The markOop describes the header of an object.31 //32 // Note that the mark is not a real oop but just a word.33 // It is placed in the oop hierarchy for historical reasons.34 //35 // Bit-format of an object header (most significant first, big endian layout below):36 //37 // 32 bits:38 // --------39 // hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)40 // JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)41 // size:32 ------------------------------------------>| (CMS free block)42 // PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)43 //44 // 64 bits:45 // --------46 // unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)47 // JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)48 // PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)49 // size:64 ----------------------------------------------------->| (CMS free block)50 //51 // unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)52 // JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)53 // narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)54 // unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)在32位机器和64位机器上,标记字的格式略有不同。后者有两个变体,取决于是否启用了压缩对象指针(Compressed Object Pointer)。Oracle JVM和OpenJDK 8都是默认启用的。
因此对象头可能与一个内存块或一个实际的对象关联,存在多种状态。在最简单的情况下(“普通对象”),标识散列码直接存储在对象头的低地址中。
但在其他状态下,对象头包含一个指向JavaThread或PromotedObject的指针。更复杂的是:如果我们把唯一散列码放到一个“普通对象”中,它会被移走吗?移动到哪?如果对象是有偏向的(biased),我们可以从哪里获得或设置标识散列码?什么又是有偏向的对象(biased object)呢?
让我们试着回答这些问题。
偏向对象看起来是偏向锁的结果。这是从HotSpot 6起默认启用的一个特性,试图减少锁定对象的成本。锁定操作是昂贵的,它的实现通常依赖于原子CPU指令(CAS),以便安全地处理来自不同线程的锁定和解锁请求。根据观察,在大多数应用程序中,大多数对象只被一个线程锁定,因此为原子操作付出的成本常常被浪费了。为了避免这种情况,带有偏向锁的JVM允许线程将对象设置为“偏向于”自己。如果一个对象是有偏向的,线程可以锁定和解锁对象,而无需原子指令。只要没有线程争用同一个对象,我们就会得到性能提升。
对象头中的偏向锁位(biased_lock bit)表示对象是否偏向于JavaThread*所指向的线程。锁定位(lock bit)表示该对象是否被锁定。
正是因为OpenJDK的偏向锁实现需要在标记字中写入一个指针,它需要重新定位真正的标记字(其中包含标识散列码)。
这可以解释FasttHashCode中额外的复杂性。对象头不仅包含标识散列码,也包含锁定状态(比如指向锁持有者线程的指针)。因此我们需要考虑所有情况,并找到标识散列码存储的位置。
让我们来读读FasttHashCode。我们发现的第一件事是:
601 intptr_t ObjectSynchronizer::FastHashCode (Thread * Self, oop obj) {
602 if (UseBiasedLocking) {
610 if (obj->mark()->has_bias_pattern()) {
...
617 BiasedLocking::revoke_and_rebias(hobj, false, JavaThread::current());
...
619 assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");
620 }
621 }等等,它只是撤销了现有的偏向性,并禁用了对象上的偏向锁(false意味着不要尝试重置偏向性)。看接下来的几行,这确实是一个不变量:
637 // object should remain ineligible for biased locking638 assert (!mark->has_bias_pattern(), "invariant") ;如果我没看错,这意味着简单地请求对象的标识散列码将禁用偏向锁,这将强制要求锁定对象必须使用昂贵的原子指令,即使只有一个线程。
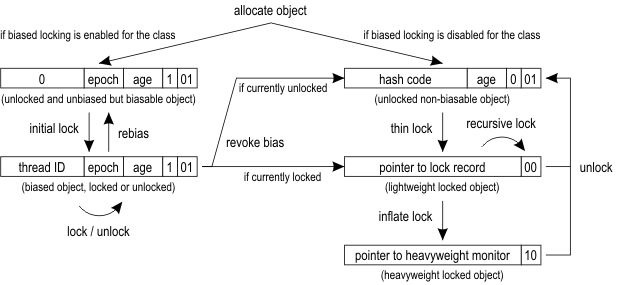
要回答这个问题,我们必须了解标记字(包含标识散列码)可能存在的位置,这取决于对象的锁的状态。下面这张来自于HotSpot Wiki的图展示了转换过程: 我的(不可靠)推理如下。
对于图顶部的4种状态,OpenJDK将能够使用“轻”锁表示。在最简单的情况下(没有锁),这意味着将标识散列码和其他数据直接放在对象的标记字中:
46 // unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)在更复杂的情况下,它需要这个空间来保存指向“锁对象”的指针。因此,标记字将被“替换”,放到其他地方。
既然只有一个线程尝试锁定对象,指针实际上会指向线程堆栈中的某个内存位置。这么做有两个优点:访问速度快(没有争用或内存访问协调),并且能够让线程确定它拥有锁(因为内存位置指向自己的堆栈)。
但这并非在所有情况下都有效。如果存在对象争用(例如许多线程都会执行到的同步语句),我们将需要一个更复杂的结构,不仅可以保存对象头副本,也保存一组等待者。如果线程执行object.wait(),就会出现对等待者列表的类似需求。
这个更丰富的数据结构就是ObjectMonitor,在图中称为“重量级”管程。对象头不再指向“被替换的标记字”,而是指向一个实际的对象(管程)。这时访问标识散列码需要“扩张管程(inflate the monitor)”:跟踪指针得到对象,读取或修改包含被替换标记字的域。这个操作更加昂贵,而且需要协调。
FasttHashCode确实有工作要做。
L640到L680处理查找对象头并检查缓存的标识散列码。我相信存在一个快速路径来探测不需要扩张管程的情况。
从L682开始需要咬紧牙关:
682 // Inflate the monitor to set hash code683 monitor = ObjectSynchronizer::inflate(Self, obj);
684 // Load displaced header and check it has hash code685 mark = monitor->header();
...
687 hash = mark->hash();此时,如果标识散列码存在(hash != 0),JVM可以直接返回。否则需要从get_next_hash()中得到散列码,并安全地存储在ObjectMonitor保存的对象头中。
这似乎提供了一个合理的解释,为什么在不覆盖默认实现的对象上调用hashCode()导致对象不符合偏向锁的条件:
为了在重定位后保持对象的标识散列码不变,需要将标识散列码存储在对象头中。
请求标识散列码的线程未必关心对象是否锁定,但上它们实际上共享了锁机制使用的数据结构。这种机制是一个复杂怪兽,它不仅自身要发生变化,还要移动(替换)对象头。
偏向锁能够在不使用原子操作的情况下进行锁定和解锁操作。偏向锁是高效的,如果只有一个线程锁定对象。我们可以将锁状态记录到标记字中。我不能100%肯定,但是我认为既然其他线程可能会读取标识散列码,即使只有一个线程需要锁定,标记字也会发生争用,并需要原子操作来保证准确。这否定了偏向锁的全部意义。
默认的hashCode()实现(标识哈希码)和对象的内存地址无关,至少在OpenJDK中是这样的。在OpenJDK 6和7中,它是一个随机生成的数字。在OpenJDK 8和9中,它是一个基于线程状态的数字。这里有一个测试得出了相同的结论。
证明“依赖于实现”的警告并非虚谈:Azul Zing确实从对象的内存地址生成标识散列码。
在HotSpot中,标识散列码只生成一次,然后缓存在对象头的标记字中。
Zing使用了不同的方案来保证散列码在对象重定位后的一致的。他们在对象重定向时才保存标识散列码的值。这个时候散列码被保存在pre-header中。
在HotSpot中,调用默认值hashCode()或System.identityHashCode()将使对象的锁失去偏向性。
这意味着如果你对没有争用的对象进行同步(synchronized),最好重写默认的hashCode()实现,否则将错过JVM优化。
在HotSpot中,可以禁用单个对象的偏向锁。
这是非常有用的。我曾见过应用程序在争用的生产者-消费者队列中使用过多的偏向锁,这带来的麻烦比好处多,所以我们完全禁用了这个特性。实际上,我们可以通过在特定对象或类上调用System.identityHashCode()来实现这一点。
我发现HotSpot没有标志选择默认的hashCode生成器,所以试验其他生成器可能需要编译源代码。
说实话我没仔细看。Michael Rasmussen善意地指出-XX:hashCode=2可以用来更改默认值。谢谢!
我编写了一个简单的JMH工具来验证这些结论。
基准测试所做的事情类似:
object.hashCode();while(true) {synchronized(object) {
counter++;
}
}第一种配置(withIdHash)在使用标识散列码的对象上同步,我们预计调用hashCode()将导致偏向锁被禁用。第二种配置(withoutIdHash)实现了自定义散列码,因此不会禁用偏向锁。每个配置先用一个线程运行,然后用两个线程(带有后缀“Contended”)。
顺便说一下,我们必须启用-XX:BiasedLockingStartupDelay=0,否则JVM将等待4s时间才触发优化,这将影响测试效果。
第一次执行:
Benchmark Mode Cnt Score Error Units BiasedLockingBenchmark.withIdHash thrpt 100 35168,021 ± 230,252 ops/ms BiasedLockingBenchmark.withoutIdHash thrpt 100 173742,468 ± 4364,491 ops/ms BiasedLockingBenchmark.withIdHashContended thrpt 100 22478,109 ± 1650,649 ops/ms BiasedLockingBenchmark.withoutIdHashContended thrpt 100 20061,973 ± 786,021 ops/ms
我们可以看到,使用自定义散列码使锁定和解锁循环比使用标识散列码(禁用偏向锁)快4倍。当两个线程争用锁时,偏置锁将被禁用,因此两种散列方法之间没有显著差异。
第二次运行,禁用所有配置中的偏向锁(-XX:-UseBiasedLocking)。
Benchmark Mode Cnt Score Error Units BiasedLockingBenchmark.withIdHash thrpt 100 37374,774 ± 204,795 ops/ms BiasedLockingBenchmark.withoutIdHash thrpt 100 36961,826 ± 214,083 ops/ms BiasedLockingBenchmark.withIdHashContended thrpt 100 18349,906 ± 1246,372 ops/ms BiasedLockingBenchmark.withoutIdHashContended thrpt 100 18262,290 ± 1371,588 ops/ms
散列方法不再有任何影响,withoutIdHash也失去了它的优势。
(所有的基准测试都运行在一台 2.7 GHz Intel Core i5电脑上。)
这些猜想以及我对JVM源代码的理解,来自于对关于布局、偏向锁等不同资料的拼凑。主要的资料有:
https://blogs.oracle.com/dave/entry/biased_locking_in_hotspot
http://fuseyism.com/openjdk/cvmi/java2vm.xhtml
http://www.dcs.gla.ac.uk/~jsinger/pdfs/sicsa_openjdk/OpenJDKArchitecture.pdf
https://www.infoq.com/articles/Introduction-to-HotSpot
http://blog.takipi.com/5-things-you-didnt-know-about-synchronization-in-java-and-scala/#comment-1006598967
http://www.azulsystems.com/blog/cliff/2010-01-09-biased-locking
https://dzone.com/articles/why-should-you-care-about-equals-and-hashcode
https://wiki.openjdk.java.net/display/HotSpot/Synchronization
https://mechanical-sympathy.blogspot.com.es/2011/11/biased-locking-osr-and-benchmarking-fun.html
package com.github.srvaroa.jmh;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
import java.util.concurrent.TimeUnit;
@State(Scope.Benchmark)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@Warmup(iterations = 4)
@Fork(value = 5, jvmArgsAppend = {"-XX:-UseBiasedLocking", "-XX:BiasedLockingStartupDelay=0"})
public class BiasedLockingBenchmark {
int unsafeCounter = 0;
Object withIdHash;
Object withoutIdHash;
@Setup
public void setup() {
withIdHash = new Object();
withoutIdHash = new Object() {
@Override
public int hashCode() {
return 1;
}
};
withIdHash.hashCode();
withoutIdHash.hashCode();
}
@Benchmark
public void withIdHash(Blackhole bh) {
synchronized(withIdHash) {
bh.consume(unsafeCounter++);
}
}
@Benchmark
public void withoutIdHash(Blackhole bh) {
synchronized(withoutIdHash) {
bh.consume(unsafeCounter++);
}
}
@Benchmark
@Threads(2)
public void withoutIdHashContended(Blackhole bh) {
synchronized(withoutIdHash) {
bh.consume(unsafeCounter++);
}
}
@Benchmark
@Threads(2)
public void withIdHashContended(Blackhole bh) {
synchronized(withIdHash) {
bh.consume(unsafeCounter++);
}
}
}到此,关于“通过重写hashCode()方法将偏向锁性能提高4倍的方法步骤”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/131191/blog/5034519



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



