本篇内容主要讲解“大端字节序和小端字节序有什么区别”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“大端字节序和小端字节序有什么区别”吧!
字节序
首先,字节序由CPU的架构决定,与操作系统无关,与编译器亦无关。
所谓字节序,就是字节在内存中的排列顺序。
字节序分为以下两种:
大端字节序:高位字节在前,低位字节在后,与人类读写数值的方法相同。 小端字节序:低位字节在前,高位字节在后。
字节序为什么会有大端和小端之分
数据在内存中一般都是以字节为单位存储的,但是有些数据类型大于1个字节,譬如short占用2个字节,int占用4个字节,同时处理器的总线宽度一般是32位后者64位,即一次读写操作,可以同时读写4个字节或者64字节的数据。
这些超过1个字节的数据,就存在字节在内存中如何排序的问题,根据排序方式的不同,就产生了大端模式和小端模式之分。
如何区分大端和小端
内存中地址一般都是从低到高来访问的(栈内存相反),如下图:

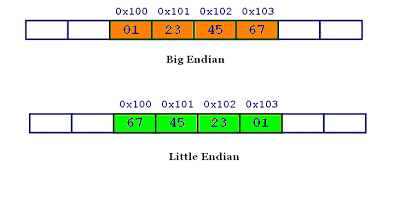
假设有一个十六进制数:0x1234,使用两个字节来存储,则0x12是高位字节(高数据位),0x34是低位字节(低数据位)。
如果低位字节0x34存储在内存的高地址,即为大端字节序。即计算机先存储0x12,再存储0x34,内存中排列为0x1234。符合人类的阅读习惯。
如果低位字节0x34存储在内存的低地址,即为小端字节序。即计算机先存储0x34,再存储0x12,内存中排列为0x3412。
同理,0x1234567的大端字节序和小端字节序的写法如下图:
如何通过编程来判断当前字节序
原理:就是读取某个short变量或者其他类型变脸的第一个字节的数据,第一个字节(低地址,也是起始地址)的数据存储的是高位字节数据则为大端,反之,如果第一个字节的数据存储的低位自己的数据则为小端。
代码如下,编译运行后即可判断当前字节序。
#include <stdio.h>
int main()
{
short byteOrder = 0x1234;
char cOrder = (char)&byteOrder; // short存储在内存中的地一个字节(低地址)的值,赋值给char
if (cOrder == 0x12)
{
printf("Big-Endian\n");
}
else
{
printf("Little-Endian\n");
}
return 0;
}字节序与CPU架构
大端模式的cpu:PowerPC(默认大端),IBM,SUN。
小端模式的cpu:x86,DEC。
arm既可以工作在大端模式,也可以工作在小端模式。
cpu架构的分类
目前市面上的CPU指令集分类主要分有两大阵营,
一个是intel、AMD为首的复杂指令集CPU,
另一个是以IBM、ARM为首的精简指令集CPU。
两个不同品牌的CPU,其产品的架构也不相同。
例如,Intel、AMD的CPU是X86架构的,而IBM公司的CPU是PowerPC架构,ARM公司是ARM架构。
x86架构的CPU是小端字节序,PowerPC架构的CPU是大端(默认大端),ARM架构的CPU是小端(默认小端)。
网络字节序
网络字节序,统一使用大端字节序。
到此,相信大家对“大端字节序和小端字节序有什么区别”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/1585028/blog/5026517



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



