这篇文章主要介绍“Python爬虫基础库有哪些”,在日常操作中,相信很多人在Python爬虫基础库有哪些问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Python爬虫基础库有哪些”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
爬虫有三大基础库Requests、BeautifulSoup和Lxml,这三大库对于初学者使用频率最高,现在大家一起来看看这基础三大库的使用。
1、Requests库
Requests库的作用就是请求网站获取网页数据。
Code:res=requests.get(url)
返回:
返回200说明请求成功
返回404、400说明请求失败
Code:res=request.get(url,headers=headers)
添加请求头信息伪装为浏览器,可以更好的请求数据信息
Code:res.text
详细的网页信息文本
2、BeautifulSoup库
BeautifulSoup库用来将Requests提取的网页进行解析,得到结构化的数据
Soup=BeautifulSoup(res.text,’html.parser’)
详细数据提取:
infos=soup.select(‘路径’)
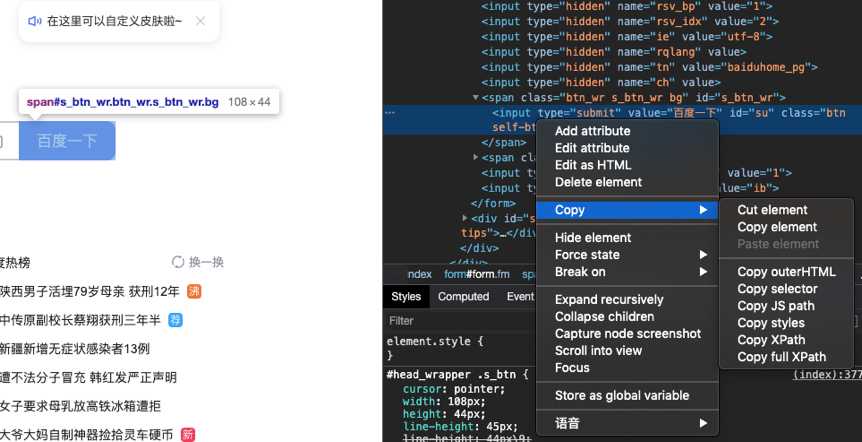
路径提取方法:在固定数据位置右键-copy-copy selector
3、Lxml库
Lxml为XML解析库,可以修正HTML代码,形成结构化的HTML结构

Code:
From lxml import etree
Html=etree.HTML(text)
Infos=Html.xpath(‘路径’)
路径提取方法:在固定数据位置右键-Copy-Copy Xpath
实践案例:
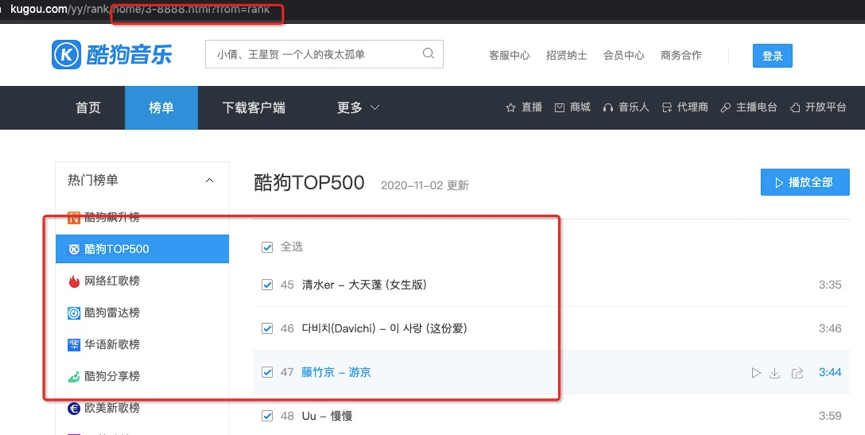
1、爬取酷狗榜单TOP500音乐信息

2、网页无翻页,如何寻找URL,发现第一页URL为:
https://www.kugou.com/yy/rank/home/1-8888.html?from=rank
尝试把1换成2,可以得到新的网页,依次类推,得到迭代的网页URL
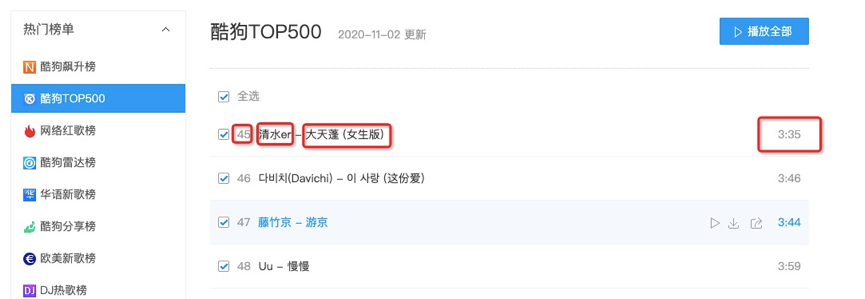
3、爬取信息为歌曲名字、歌手等
4、详细代码如下:
import requestsfrom bs4 import BeautifulSoupimport timeheaders={"User-Agent": "xxxx"}def get_info(url): print(url) #通过请求头和链接,得到网页页面整体信息 web_data=requests.get(url,headers=headers) #print(web_data.text) #对返回的结果进行解析 soup=BeautifulSoup(web_data.text,'lxml') #找到具体的相同的数据的内容位置和内容 ranks = soup.select('span.pc_temp_num') titles = soup.select('div.pc_temp_songlist > ul > li > a') times = soup.select('span.pc_temp_tips_r > span') #提取具体的文字内容 for rank, title, time in zip(ranks, titles, times): data = { 'rank': rank.get_text().strip(), 'singer': title.get_text().split('-')[0], 'song': title.get_text().split('-')[1], 'time': time.get_text().strip() } print(data)if __name__=='__main__': urls = ['https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank'.format(i) for i in range(1, 2)] for url in urls: get_info(url) time.sleep(1)到此,关于“Python爬虫基础库有哪些”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4607696/blog/4705785



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



