这篇文章主要讲解了“如何使用KafkaAPI-ProducerAPI”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“如何使用KafkaAPI-ProducerAPI”吧!
Kafka 的 Producer 发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程,以及一个线程共享变量——RecordAccumulator。main 线程将消息发送给 RecordAccumulator, Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka broker。
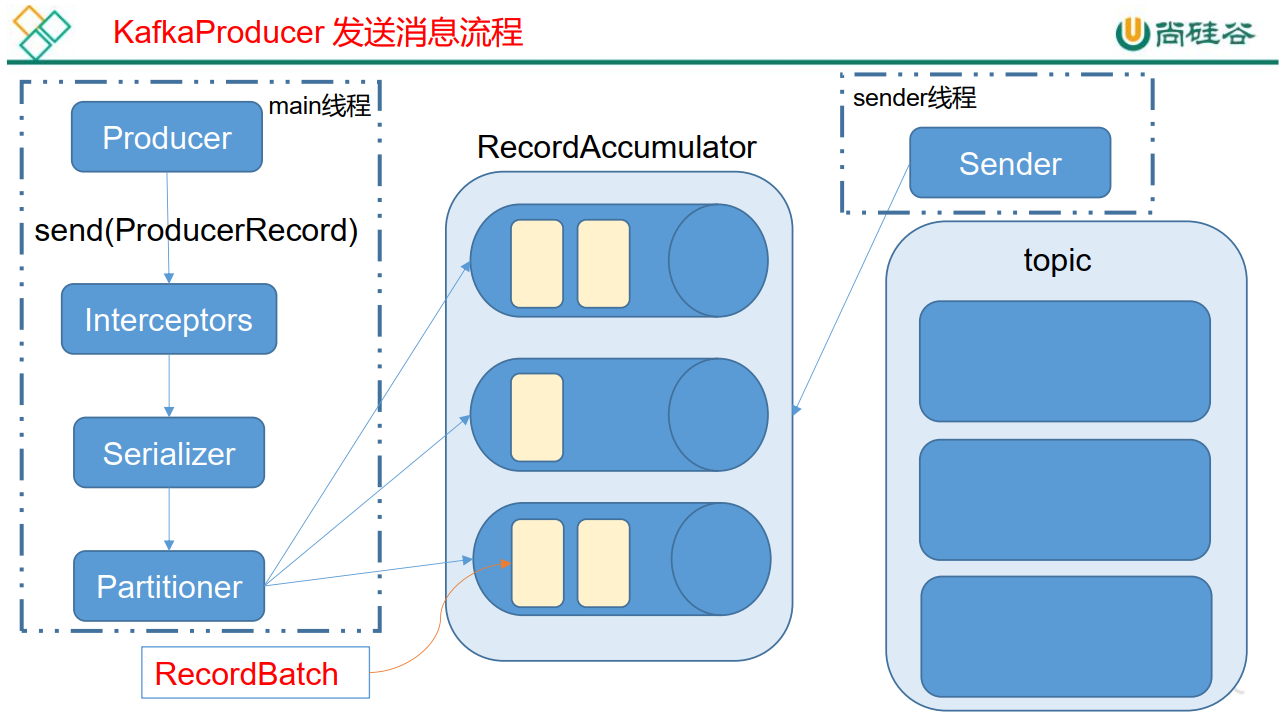
相关参数:
batch.size: 只有数据积累到 batch.size 之后, sender 才会发送数据。
linger.ms: 如果数据迟迟未达到 batch.size, sender 等待 linger.time 之后就会发送数据。
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.7.0</version>
</dependency>需要用到的类:
KafkaProducer:需要创建一个生产者对象,用来发送数据
ProducerConfig:获取所需的一系列配置参数
ProducerRecord:每条数据都要封装成一个 ProducerRecord 对象
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class MyProducer {
public static void main(String[] args) {
//生产者配置信息可以从ProducerConfig中取Key
//1.创建kafka生产者的配置信息
Properties properties=new Properties();
//2.指定连接的kafka集群
//properties.put("bootstrap.servers","192.168.1.106:9091");
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.1.106:9091");
//3.ACK应答级别
//properties.put("acks","all");
properties.put(ProducerConfig.ACKS_CONFIG,"all");
//4.重试次数
//properties.put("retries",3);
properties.put(ProducerConfig.RETRIES_CONFIG,3);
//5.批次大小 16k
//properties.put("batch.size",16384);
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);
//6.等待时间
//properties.put("linger.ms",1);
properties.put(ProducerConfig.LINGER_MS_CONFIG,1);
//7.RecordAccumulator 缓冲区大小 32M
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);
//properties.put("buffer.memory",33554432);
//8.Key,Value 的序列化类
//properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//9.创建生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
//10.发送数据
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("first","atguigu--"+i);
producer.send(producerRecord);
}
//11.关闭资源
producer.close();
}
} 回调函数会在 producer 收到 ack 时调用,为异步调用, 该方法有两个参数,分别是RecordMetadata 和 Exception,如果 Exception 为 null,说明消息发送成功,如果Exception 不为 null,说明消息发送失败。
注意:消息发送失败会自动重试,不需要我们在回调函数中手动重试。
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class CallBackProducer {
public static void main(String[] args) {
//生产者配置信息可以从ProducerConfig中取Key
Properties properties=new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.1.106:9091,192.168.1.106:9092,192.168.1.106:9093");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//创建生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
/*创建topic
/opt/kafka/kafka03/bin/kafka-topics.sh --create --zookeeper 192.168.1.106:2181,192.168.1.106:2182,192.168.1.106:2183 --replication-factor 3 --partitions 2 --topic aaa
* */
//发送数据
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("bbb","d","bbb-atguigu++"+i);
producer.send(producerRecord, (recordMetadata, e) -> {
if (e==null){
System.out.println("aaa "+recordMetadata.partition()+ "--"+recordMetadata.offset());
}else {
e.printStackTrace();
}
});
}
//11.关闭资源
producer.close();
}
}同步发送的意思就是,一条消息发送之后,会阻塞当前线程, 直至返回 ack。由于 send 方法返回的是一个 Future 对象,根据 Futrue 对象的特点,我们也可以实现同步发送的效果,只需在调用 Future 对象的 get 方发即可、
//10.发送数据
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("first","atguigu--"+i);
producer.send(producerRecord).get();
}默认分区策略源码:
org.apache.kafka.clients.producer.internals.DefaultPartitioner
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
import java.util.Map;
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
/*自定义分区规则*/
List<PartitionInfo> partitionInfos = cluster.availablePartitionsForTopic(topic);
Integer integer =partitionInfos.size();
return key.toString().hashCode()%integer;
/*指定分区*/
/* return 1;*/
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}//配置方法
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.zhl.kafkademo.partitioner.MyPartitioner");完整代码:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class PartitionProducer {
public static void main(String[] args) {
//生产者配置信息可以从ProducerConfig中取Key
Properties properties=new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.1.106:9091,192.168.1.106:9092,192.168.1.106:9093");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//配置分区器的全类名 partitioner.class
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.zhl.kafkademo.partitioner.MyPartitioner");
//创建生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
//发送数据
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("bbb","d","bbb-atguigu++"+i);
producer.send(producerRecord, (recordMetadata, e) -> {
if (e==null){
System.out.println(recordMetadata.topic()+"--"+ recordMetadata.partition()+ "--"+recordMetadata.offset());
}else {
e.printStackTrace();
}
});
}
//11.关闭资源
producer.close();
}
}感谢各位的阅读,以上就是“如何使用KafkaAPI-ProducerAPI”的内容了,经过本文的学习后,相信大家对如何使用KafkaAPI-ProducerAPI这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/1020373/blog/5021166



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



