在使用 Jasper 报表工具制作报表时,常常会遇到数据来自多个数据源的情况,通常的做法是使用主子报表或者使用javabean作为数据源。使用主子报表通常会增加报表设计的复杂度,而使用javabean做数据源,则需要一个javabean类来支持,并且为了在设计报表时能够看到数据,还要为ireport提供一个静态方法,该方法用于返回上面定义javabean的一个结果集。
显然,上面这两种办法都不太方便,本文将提供一种更加简便的方法,那就是通过集算器来解决ireport中的多数据源问题,并进一步提高ireport的性能。我们将以JasperReport5.6.0 开发环境为例进行介绍。
报表项目中,常常会出现报表源数据来自不同数据库的情况,例如同一应用系统的数据库负载太大,不得已分成多个数据库,就像是最常见的销售系统数据分成当前库和历史库,一部分数据存于数据库一部分数据存于文件等。
在多数据源的数据库类型方面,报表工具可能连接同样类型的数据库,比如都是mysql或者 oracle;也可能是不同的类型,如txt、csv或者Excel等。
我们的例子中,报表数据一部分来自mysql数据库,一部分来自文本文件。
其中,mysql数据库的employee表存储EID为1-100000的数据,内容如下:
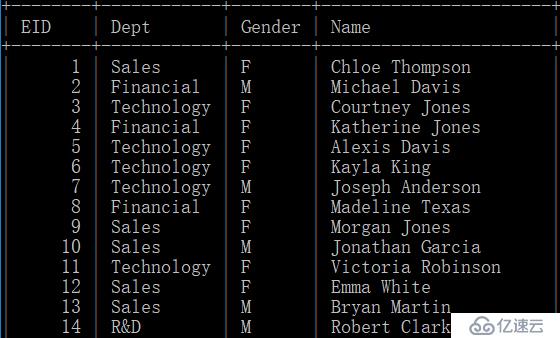
而data.txt文件中存储EID为100001-101000的数据,内容如下:
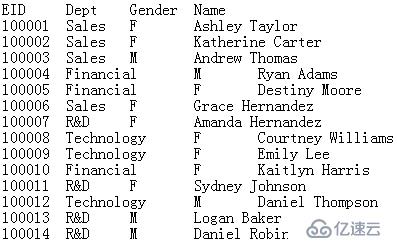
我们的任务是在ireport中制作一张报表,查看employee表和emp.txt文件合并后的所有数据。这一需求通过集算器协助 ireport可以轻松实现。集算器使用我们称之为结构化处理语言(Structured Process Language,简称SPL),具体的SPL代码如下:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from employee") |
| 3 | =file("F:\\files\\emp.txt").import@t() |
| 4 | =[A2,A3].conj() |
| 5 | return A4 |
A1:创建数据源连接,连接mysql数据源。
A2:在mysql数据源中查询employee表中的数据,并返回查询结果。
A3:读取文件emp.txt的内容。
A4:合并A2和A3数据。

A4:将A4合并后的结果返回给报表。
为了在报表中呈现计算结果,我们需要将以上 SPL 代码存为文件 employee.dfx,然后就可以利用集算器对外提供的 JDBC 接口调用这个脚本了。
在报表工具中通过建立 JDBC 数据源引入集算器脚本的方法和调用存储过程一样,在 Jasper 的 SQL 设计器中可以用call employee()来调用。具体步骤在《JasperReport 调用 SPL 脚本》一文中有详细的描述。
然后,我们可以在ireport 中设计一个最简单的报表employee.jrxml,模板如下:
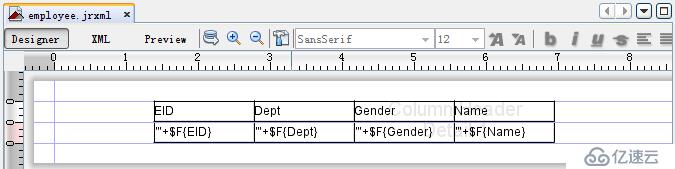
预览后可以直接看到报表结果了:
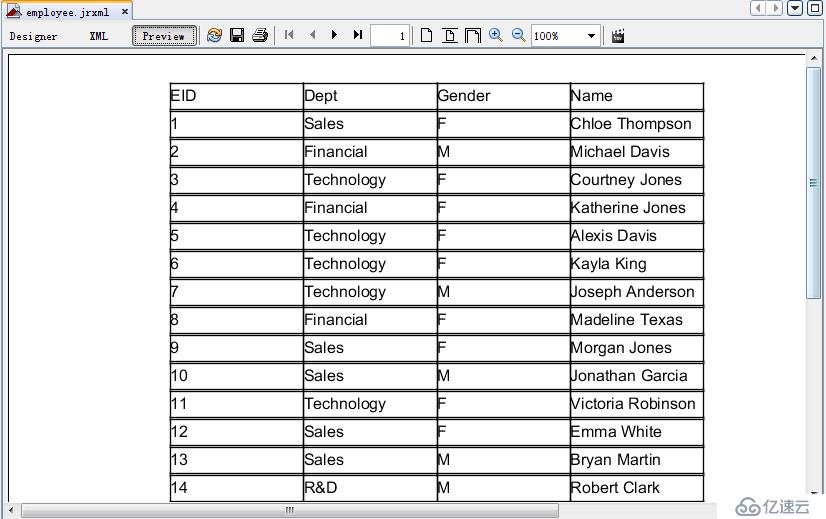
显然,这个过程相比传统的主子报表或者javabean方法要简单不少,更重要的是,计算逻辑非常清晰,集成方式也几乎没有任何学习成本。
在解决了基本的功能需求后,我们还可以进一步将焦点关注到性能方面。报表项目中,常常需要将多个表连接查询,在这些被连接的表中,可能会包含海量的数据。例如:将雇员表和订单表通过共有字段员工编号连接起来,以便查看某些订单的销售人员的信息。显然,订单表会随着时间的推移不断增长,最终带来严重的系统负担。
下面例子中的报表数据一部分来自mysql数据库的employee表,一部分来自mysql数据库的sales表。
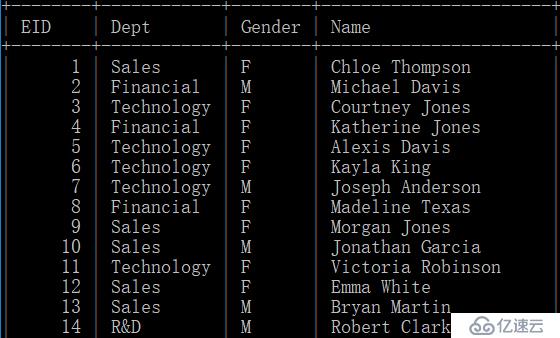
其中,employee表存储EID为1-3000000的雇员数据,内容如下:
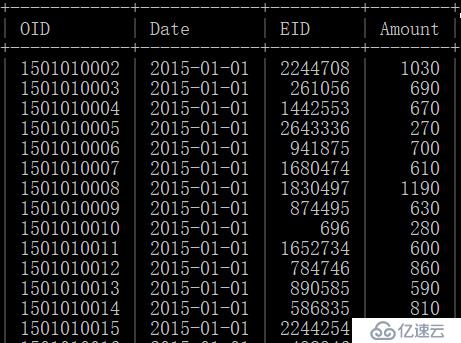
而订单数据sales表则存储了76万条数据,而且持续增加。其中的数据内容样例如下:
为了实现连接查询,我们在ireport 中设计一个最简单的报表mysql_join.jrxml,模板如下:
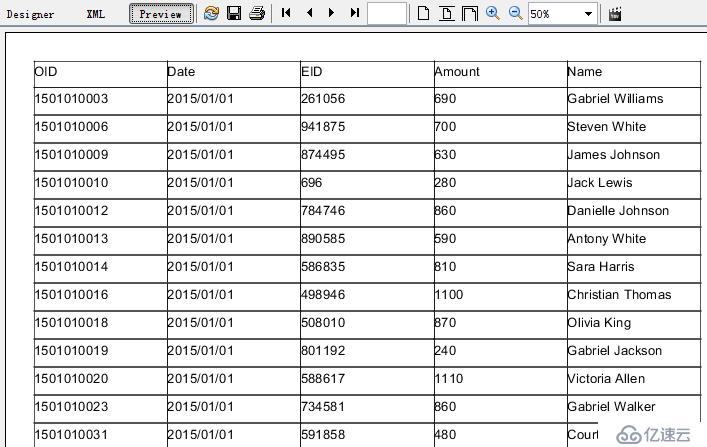
首先我们看一下传统做法的表现。我们需要查询早于2015-04-01,由EID小于1000001的雇员产生的销售数据,SQL 语句如下:
select sales.OID,sales.Date,sales.EID,sales.Amount,employee.Name from sales join employee on sales.EID=employee.EID where sales.Date<'2015-04-01'and employee.EID<1000001select sales.OID,sales.Date,sales.EID,sales.Amount,employee.Name from sales join employee on sales.EID=employee.EID where sales.Date<'2015-04-01'and employee.EID<1000001
点击预览,在我们的测试环境下,101s后展现计算结果:
接下来,我们看看用集算器jdbc的运行效果。将上边的报表另存为esproc_join.jrxml。
然后编写如下的SPL代码:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.cursor("select * from sales where Date<'2015-04-01'") |
| 3 | =A1.query("select EID,Name from employee where EID<1000001").keys(EID) |
| 4 | =A2.join@i(EID,A3:EID,Name) |
| 5 | return A4.fetch() |
A1:创建数据源连接,连接mysql数据源。
A2:查询sales表中Date早于2015-04-01的数据,将结果返回成游标。
A3:查询employee表中EID小于1000001的EID列和Name列的数据。

A4:游标A2与序表A3外键式连接。
A5:将游标的结果返回给报表。
接下来和前一个例子一样,将以上 SPL 代码存为文件esproc_join.dfx,并在数据源中定义SQL:
call esproc_join()call esproc_join()
现在,我们点击预览,在同样的测试环境下,14s后就得到了完全相同的计算结果。
可见,使用集算器在简化了ireport访问多数据源的同时,还可以大大提高ireport的性能。本文中的例子只是集算器中一些简单的应用。事实上,基于集算器的灵活性,使用集算器提高性能的办法有很多,包括并行取数、可控缓存、控制SQL执行路径、减少隐藏格、引入数据计算层等等。更多更高级的使用快来乾学院看看吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





