在数据库应用开发中,我们经常需要面对复杂的SQL式计算,固定分组就是其中一种。固定分组的分组依据不在待分组的数据中,而是来自于外部,比如另一张表、外部参数、条件列表等。对于特定类型的固定分组,用SQL实现还算简单(比如:分组依据来自另一张表,且对分组次序没有要求),但对于比较通用、灵活的要求,实现起来就困难了。
而对于SPL来说,完全可以轻松解决固定分组中的各类难题,下面就用几个例子来说明。
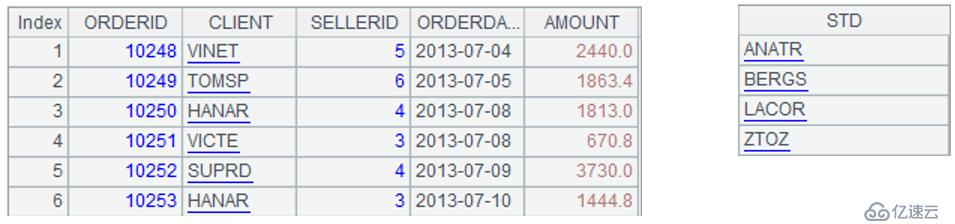
表sales存储着订单记录,其中CLIENT列是客户名,AMOUNT列是订单金额。表sales的部分数据如下:
| OrderID | Client | SellerId | OrderDate | Amount |
| 10248 | VINET | 5 | 2013/7/4 | 2440 |
| 10249 | TOMSP | 6 | 2013/7/5 | 1863.4 |
| 10250 | HANAR | 4 | 2013/7/8 | 1813 |
| 10251 | VICTE | 3 | 2013/7/8 | 670.8 |
| 10252 | SUPRD | 4 | 2013/7/9 | 3730 |
| 10253 | HANAR | 3 | 2013/7/10 | 1444.8 |
| 10254 | CHOPS | 5 | 2013/7/11 | 625.2 |
| 10255 | RICSU | 9 | 2013/7/12 | 2490.5 |
| 10256 | WELLI | 3 | 2013/7/15 | 517.8 |
要求将sales按照“潜力客户列表”进行分组,并对各组的AMOUNT列汇总求和。这里的“潜力客户”就是一种固定分组,可能来自于外部不同的条件设定:
案例一:潜力客户列表来自于另外一张表potential的Std字段,只有四条记录,依次为:ANATR、BERGS、LACOR、ZTOZ,并且客户ZTOZ不在sales表中。在输出结果时,要求按照上述记录顺序来分组汇总。
如果我们对分组的顺序没有要求,那么SQL可以较简单地实现本案例:
select potential.std as client, sum(sales.amount) as amount from potential left join client on potential.std=sales.client group by potential.std。
但如果像本案例中要求的那样,按照特定的顺序来分组,那么用SQL实现的话就必须制造一个用于排序的字段,最后还要用子查询去掉这个字段。而用SPL实现则会简单很多,代码如下:
| A | |
| 1 | =sales=db.query ("select * from sales") |
| 2 | =potential=db.query("select * from potential") |
| 3 | =sales.align@a(potential:STD,CLIENT) |
| 4 | =A3.new(potential(#).STD:CLIENT,~.sum(AMOUNT):AMOUNT) |
A1、B1:从数据库检索数据,分别命名为sales和potential,如下所示:
A3:=sales.align@a(potential:STD,CLIENT)
这句代码使用了函数align,它将sales的Client字段按照potentail的Std字段顺序对位分为四个组,如下:
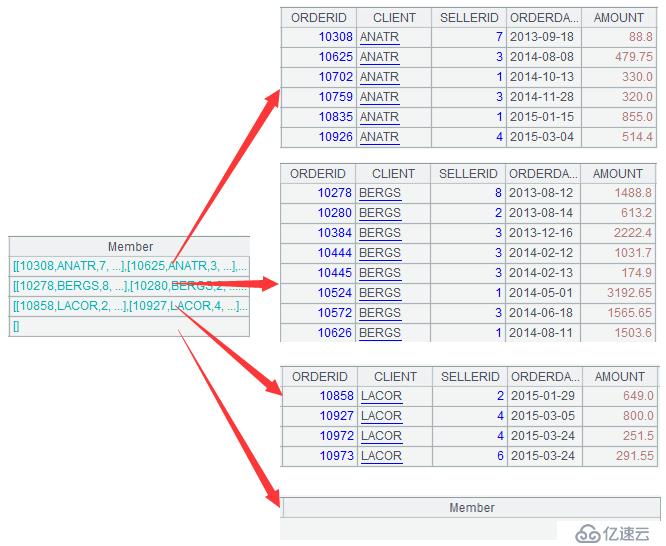
可以看到,前三个组是sales中已有的数据,而第四个组不在sales中,因此是空值。另外,函数align的参数选项@a表示取出分组中的所有数据,如果不用这个函数选项,则只取每组的第一条。
A4:=A3.new(potential(#).STD:CLIENT,~.sum(AMOUNT):AMOUNT)
这句代码用函数new产生新的序表,成员一个是potential.STD,即potential的Std字段;另一个是~.sum(AMOUNT),即对A3中每组数据的Amount字段的求和结果。最终结果如下:
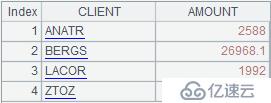
案例二:潜力客户列表是固定值,但客户的数量较多。
如果客户的数量较少,用SQL时可以用union语句将所有的客户拼成一个假表,如果客户数量较多,这么做就可不取了,必须新建一张表持久保存数据才行。而用SPL实现却可以省去建表的麻烦,代码如下:
| A | |
| 1 | =sales=db.query ("select * from sales") |
| 2 | =potential=["ALFKI","BSBEV","FAMIA","GALED","HUNGC","KOENE","LACOR","NORTS","QUICK","SANTG","THEBI","VINET","WOLZA"] |
| 3 | =sales.align@a(potential,CLIENT) |
| 4 | =A3.new(potential(#):CLIENT,~.sum(AMOUNT):AMOUNT) |
上述代码中,A2是个字符串组成的序列,并命名为potential。A3、A4可以像案例一那样对potential访问,直接引用其成员。
案例三:潜力客户列表是外部参数,形如:"BSBEV","FAMIA","GALED"。
外部参数经常变化,在SQL中用union来制造假表就更不方便了,只能创建一个临时表,将参数解析后一条条插入临时表,再进行后续的计算。而用SPL实现则不必建立临时表,具体实现过程如下:
首先定义一个参数clients,如下:
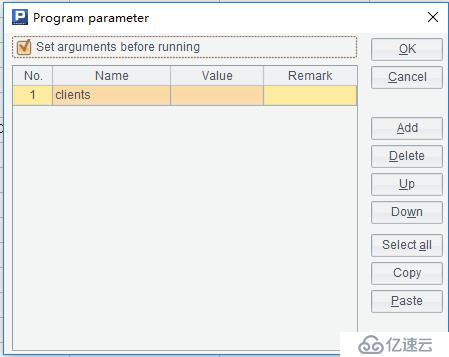
然后修改脚本文件,如下:
| A | |
| 1 | =sales=db.query ("select * from sales") |
| 2 | =potential=clients.array() |
| 3 | =sales.align@a(potential,CLIENT) |
| 4 | =A3.new(potential(#):CLIENT,~.sum(AMOUNT):AMOUNT) |
运行脚本,并输入的参数值,假设参数值为"BSBEV","FAMIA","GALED",如下:
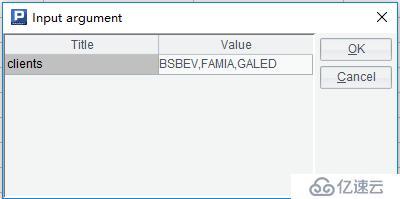
分组依据输入不同,最终计算结果也不一样。上面输入对应的结果如下:
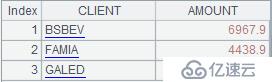
案例四:固定分组的分组依据可以是数值,也可以是条件,比如:将订单金额按照1000、2000、4000划分为四个区间,每个区间一组订单,统计各组订单的总额。
如果条件是已知,那就可以将这些条件写死在SQL里,如果条件是动态的外部参数,则需要用JAVA等高级语言拼凑SQL,过程非常复杂。而由于SPL支持动态表达式,因此可以轻松实现本案例,代码如下:
| A | |
| 1 | =sales=db.query ("select * from sales") |
| 2 | =byFac=["?<=1000" ,"?>1000 && ?<=2000","?>2000 && ?<=4000","?>4000"] |
| 3 | =sales.enum(byFac,AMOUNT) |
| 4 | =A18.new(byFac(#):byFac,~.sum(AMOUNT):AMOUNT) |
上述代码中,变量byFac是本案例的分组依据,包含四个条件。byFac也可以是外部参数,或者来自于数据库中的视图或表。A4中的最终结果如下:
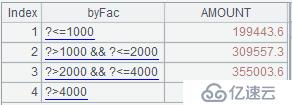
案例五:
上述条件分组中,条件恰好都没有发生重叠,但实际情况中发生重叠的情况也很常见,比如将订单金额按照如下规则分组:
1000至4000:常规订单r14
2000以下:非重点订单r2
3000以上:重点订单r3
这时,r2和r3都会和r14发生条件重叠。条件发生重叠时,我们有时希望数据不重叠,即先取出符合r14的数据,再从剩下的数据中筛选出r2,以此类推。
SPL的函数enum支持数据重叠的条件分组,如下:
| A | |
| 1 | =sales=db.query ("select * from sales") |
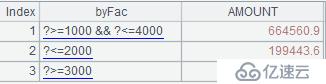
| 2 | =byFac=["?>=1000 && ?<=4000" ,"?<=2000","?>=3000"] |
| 3 | =sales.enum(byFac,AMOUNT) |
| 4 | =A3.new(byFac(#):byFac,~.sum(AMOUNT):AMOUNT) |
A3中的分组结果如下:
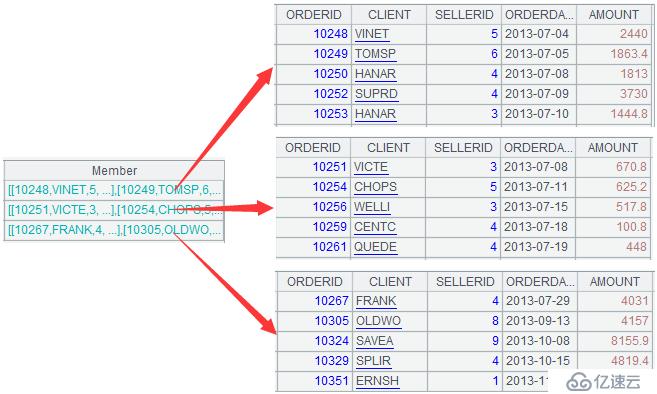
A4计算结果如下:
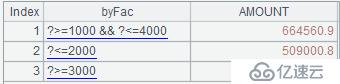
而有时,我们希望分组结果中包含重叠数据,即先从sales中取出符合r14的数据,再从完整的sales中取出符合r2的数据,以此类推。此时,只需要在函数enum中使用函数选项@r,即将A3中的代码改为:=sales.enum@r(byFac,AMOUNT),此时分组结果如下:

如图中红框所标注的,第二组数据中出现了满足1000~4000条件的数据。最后的计算结果如下:
对于计算结果,除了导出数据,SPL还可以以被调用的方式向报表工具或java程序提供数据,调用方法和普通数据库相似,使用它提供的JDBC接口即可向java主程序返回ResultSet形式的计算结果,具体方法可参考相关文档。【Java如何调用SPL脚本】
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



