这篇文章主要介绍了kettle如何连接HDP3组件Hive3.1.0存取数据,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
kettle报错研究过程
由于没有使用过kettle,一开始、下载了最新版的kettle7.0,经过各种百度,下载hive配置和jar包,但是总是连接不上hive,报各种错误,不一一举例了,直到报错:No suitable driver found for jdbc:hive2。
log4j:ERROR No output stream or file set for the appender named [pdi-execution-appender].九月 29, 2020 4:16:05 下午 org.apache.cxf.endpoint.ServerImpl initDestination信息: Setting the server‘s publish address to be /i18n2020/10/18 16:16:05 - dept.0 - Error occurred while trying to connect to the database2020/10/18 16:16:05 - dept.0 -2020/10/18 16:16:05 - dept.0 - Error connecting to database: (using class org.apache.hive.jdbc.HiveDriver)2020/10/18 16:16:05 - dept.0 - No suitable driver found for jdbc:hive2://worker1.hadoop.ljs:10000/lujisen首先说下我这里hadoop用的是比较新的HDP3.1.4,各个组件版本分别是Hadoop3.1.1.3.1、Hive3.1.0,各种百度和看官网一直解决不了这个问题。折腾很久才发现,原来是版本不匹配,因为kettle连接hadoop集群,分为连接CDH还是HDP,从目录\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations 就可以看出,每个版本的kettle只能连接该目录下指定的集群版本,因为 pentaho-hadoop-shims*.jar 这个文件的是用来匹配kettle和集群版本的,不能随意搭配。因为官网上的shims版本是有限的。
kettle下载
这里我是下载了次新稳定版本8.3,我看这个版本有对应hdp3.0的shims包,
下载地址:https://fr.osdn.net/projects/sfnet_pentaho/releases#
4.kettle配置
1.下载解压后,只有一个 data-integration 目录,开始配置连接hive,你所下载的kettle支持的所有版本的hadoop都会在他的插件子目录中有对应的文件夹和shims包,如下图所示:
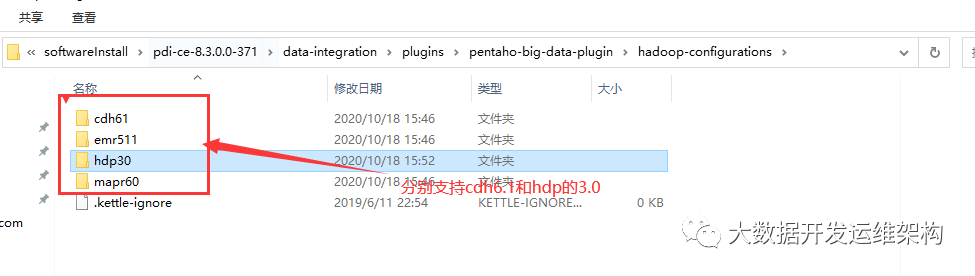
2.找到对应版本的文件夹hdp30,替换集群的xml配置文件:
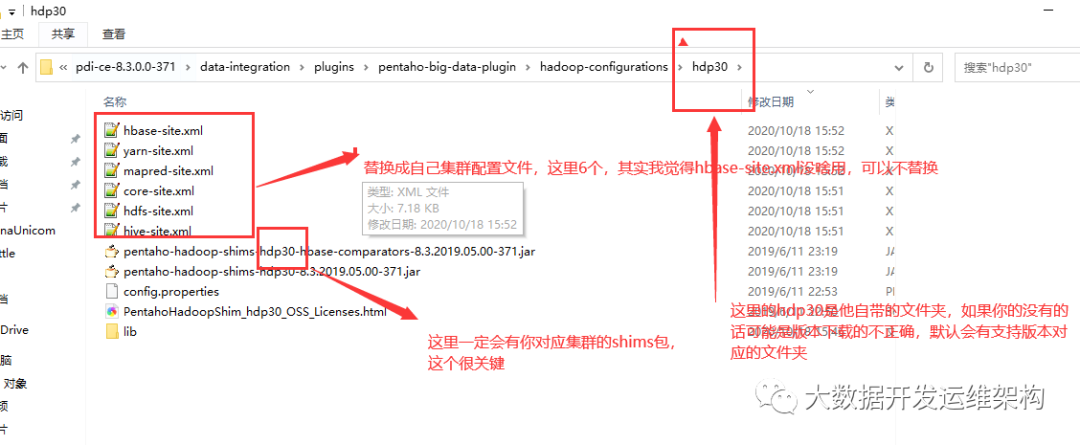
3. 修改data-integration\plugins\pentaho-big-data-plugin 目录下的 plugin.properties 文件中的配置项,指定要使用的集群配置是哪个,这里我要启用的是hdp30,入下图所示:
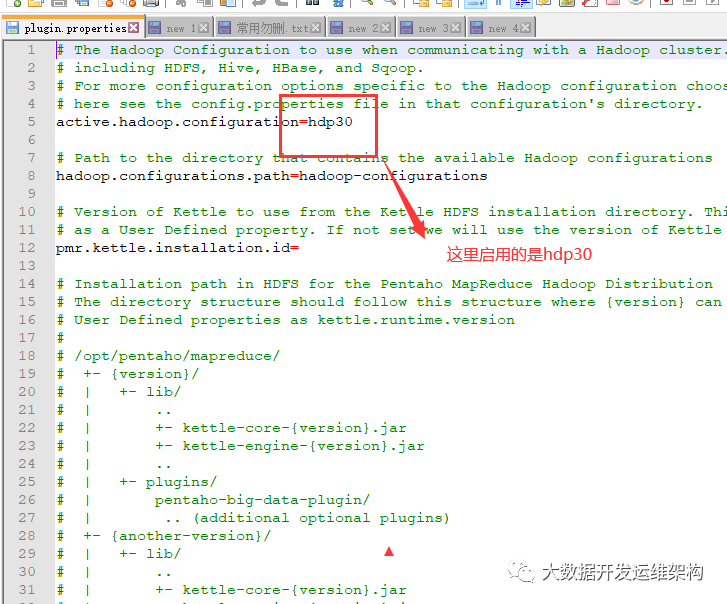
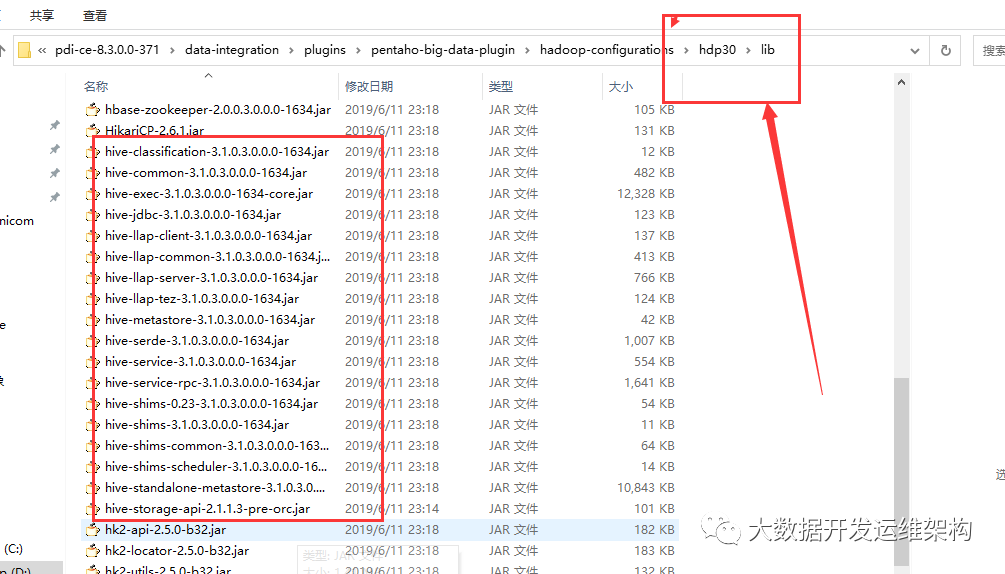
4.拷贝连接hive所需的jar包, 从集群Hive的lib目录下拷贝所有hive开头的jar,其实有些包不需要,这里我就不再挑选了直接拷贝到了hdp30/lib下,如果报错你还可以在解压的根目录data-integration/lib下也放置一份,如下图所示:
5. 放上依赖jar后,需要重启,重启之前,最好是清理下data-integration、system/karaf的cache和data(如有)目录,清理缓存:

6.重启,测试成功。
1-6步是没有启用kerberos情况下,kettle连接hive,如果集群启用了kerbeos,执行完上面的6步骤之后,还需要执行以下几步:
这里需要注意的,访问应用服务环境 hive 的主体 principal 统一为 hive/master.hadoo.ljs@HADOOP.COM,而不是用户自己的principal ,用户自己的 principal 仅作为客户端机器获取认证票据。
7. 创建文件 kettle.login,写入如下内容并保存
# :Windows 放置在 C:/ProgramData/MIT/Kerberos5/kettle.login
# :Linux 放置在 /etc/kettle.login
com.sun.security.jgss.initiate{ com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true useTicketCache=false keyTab="C:/ProgramData/MIT/Kerberos5/testuser.keytab" principal="testuser/master.hadoop.ljs@HADOOP.COM" doNotPrompt=true debug=true debugNative=true;};注意:
这上面的keytab和pricipal用哪个用户登录就换成哪个用户的票据和认证文件,注意,注意,注意
8.修改 Kettle 启动脚本
# 修改 Kettle 启动脚本## 2.1 window 系统修改 data-integration\Spoon.bat# 对大概 98 行左右的 OPT 变量修改为如下:# 主要添加了如下四个参数(注意每个参数用引号引起,空格分开,如果想开启动的信息,在启动脚本最后一行加上 pause):# "-Djava.security.auth.login.config=C:/ProgramData/MIT/Kerberos5/kettle.login"# "-Djava.security.krb5.realm=HADOOP.COM" 自己集群realm名称# "-Djava.security.krb5.kdc=192.168.33.9" 自己kdcserver地址# "-Djavax.security.auth.useSubjectCredsOnly=false"set OPT=%OPT% %PENTAHO_DI_JAVA_OPTIONS% "-Dhttps.protocols=TLSv1,TLSv1.1,TLSv1.2" "-Djava.library.path=%LIBSPATH%" "-Djava.security.auth.login.config=C:/ProgramData/MIT/Kerberos5/kettle.login" "-Djava.security.krb5.realm=HADOOP.COM" "-Djava.security.krb5.kdc=192.168.0.201" "-Djavax.security.auth.useSubjectCredsOnly=false" "-DKETTLE_HOME=%KETTLE_HOME%" "-DKETTLE_REPOSITORY=%KETTLE_REPOSITORY%" "-DKETTLE_USER=%KETTLE_USER%" "-DKETTLE_PASSWORD=%KETTLE_PASSWORD%" "-DKETTLE_PLUGIN_PACKAGES=%KETTLE_PLUGIN_PACKAGES%" "-DKETTLE_LOG_SIZE_LIMIT=%KETTLE_LOG_SIZE_LIMIT%" "-DKETTLE_JNDI_ROOT=%KETTLE_JNDI_ROOT%"## Linux 系统修改 data-integration/spoon.sh## 大概在 205 行,同 Windows 系统类似,添加四个参数OPT="$OPT $PENTAHO_DI_JAVA_OPTIONS -Dhttps.protocols=TLSv1,TLSv1.1,TLSv1.2 -Djava.library.path=$LIBPATH -Djava.security.auth.login.config=/etc/kettle.login -Djava.security.krb5.realm=HADOOP.COM -Djava.security.krb5.kdc=192.168.0.101 -Djavax.security.auth.useSubjectCredsOnly=false -DKETTLE_HOME=$KETTLE_HOME -DKETTLE_REPOSITORY=$KETTLE_REPOSITORY -DKETTLE_USER=$KETTLE_USER -DKETTLE_PASSWORD=$KETTLE_PASSWORD -DKETTLE_PLUGIN_PACKAGES=$KETTLE_PLUGIN_PACKAGES -DKETTLE_LOG_SIZE_LIMIT=$KETTLE_LOG_SIZE_LIMIT -DKETTLE_JNDI_ROOT=$KETTLE_JNDI_ROOT"9.连接hive
连接名称:lujisen连接类型:Hadoop Hive 2主机名称:hiveserver2 服务地址,例如:192.168.0.101数据库名称:lujisen;principal=hive/master.hadoop.ljs@HADOOP.COM端口号:10000用户名:hive密码:
注意:
上面第四行中principal后面跟的一定是hive管理员的票据,不是某个登录用户的票据,一定注意,注意,注意
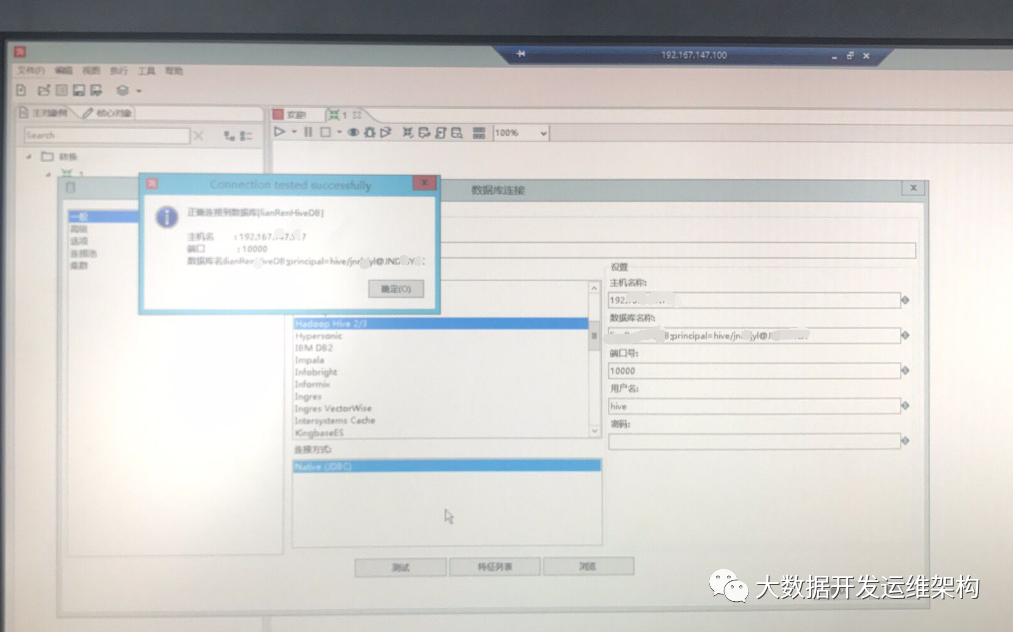
10.连接成功,如下图所示:
感谢你能够认真阅读完这篇文章,希望小编分享的“kettle如何连接HDP3组件Hive3.1.0存取数据”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/2380815/blog/4681452



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



