好程序员大数据学习路线分享函数+map映射+元祖,大数据各个平台上的语言实现
hadoop 由java实现,2003年至今,三大块:数据处理,数据存储,数据计算
存储: hbase --> 数据成表
处理: hive --> 数据仓库的工具
计算: mapreduce --> 入门级
hive java实现
flink 流失处理 scala实现 --> 计算引擎
kafka 数据缓存 scala实现
spark scala实现 \ python
DL 4j scala实现
sklearning python实现
akka scala实现 --> 通信
scala发展历程
scala作者:
马丁,函数编程的爱好者,一直在jvm平台上工作
scala的魅力
scala针对spark集群里的spark -shell 进行脚本编程
scala针对IDEA的maven,进行spark的app开发
大数据开发编程思想
1.加载数据集,(基于本地数据,win \ hdfs \ Array)
2.分割数据集,(聚合操作)
3.选择apache框架(处理-Hive,存储-HBSE,计算-mapreduce,)
4.调试,测试代码
5.调优,代码,app,数据倾斜,troubleshooting故障排除
6.上线
val 和 var
val被final修饰,不可以修改变量值
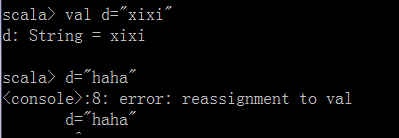
var可以修改

java和scala共用jvm,但是思想不一样
scala 数据类型:
scala中,一切类的基类为 Any
第一种:
AnyRef,是Any的子类,是所有的引用类型的基类,所有的继承都来自AnyRef
第二种:
AnyVal,是Any的子类,Byte\Char\Short\int\Long\Float\Double(无包装类)-->七种数据类型,Unit(无返回值类型)\Boolean
条件表达式
object test { def main(args: Array[String]): Unit = { val x = 1 //判断x的值,将结果赋给y val y = if (x > 0) 1 else -1 println(y) //1 println("------------------------------------------") //支持混合类型表达式 val z = if (x > 1) 1 else "error" println(z) //error println("------------------------------------------") //如果缺失else,相当于if(x>2) 1 else () val m = if (x > 2) 1 println(m) //() println("-----------------------------------------------") //在scala里每个表达式里都有值,scala中有个unit类,写作(),相当于java里的void val n = if (x > 2) 1 else () println(n) //() println("----------------------------------------------") //if,else if val k = if (x < 0) 0 else if (x >= 1) 1 else -1 println(k) //1 } } |
块表达式
* 在scala中"{}"中包含一系列的列表达式就形成了块表达式
* 下面就是一个块表达式
* 用lazy关键字来修饰,该代码局就是在调用才运行
object Block { def main(args: Array[String]): Unit = {
val x = 0 val result = { if (x < 0) { -1 } else if (x >= 1) { 1 } else { "error" } } println(result) //result的值就是整块的表达式的结果 } } |
printf打印和foreach的使用
arr.toBuffer -> 变常数组
scala> val arr = Array(1,2,3,4) arr: Array[Int] = Array(1, 2, 3, 4) scala> print(arr.toString) [I@108fa66 scala> print(arr.toBuffer) ArrayBuffer(1, 2, 3, 4) |
printf 用法 --> 相当于格式化
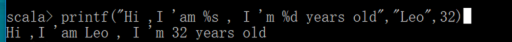
%s 表示字符串
%d 表示数字
object game { def main(args: Array[String]): Unit = { //readline()允许我们从控制台读取用户输入的数据,类似于java中的System.in和Scanner val name = readLine("Welcome to Game House,please tell me your name:\n") print("Thanks,then please tell me your age:\n") val age = readInt() //初始化 if(age > 18){ printf("Hi,%s,you are %d years old,so you are legal to come here",name,age) } else{ printf("Sorry,%s,you are only %d years old,you are illegal to come here",name,age) } } } |
for循环的三种方式+filter
scala> val arr = Array(2,3,4,6) arr: Array[Int] = Array(2, 3, 4, 6) scala> for(i <- arr){ | if(i%2 == 0){ | println(i) | } | } 2 4 6 scala> for(i <- 0 until arr.length){ | if(arr(i)%2 == 0){ | print(arr(i))}} 246 scala> for(i <- 0 to arr.length-1){ | if(arr(i)%2 == 0){ | print(arr(i)+" ")}} 2 4 6 scala> println(arr.filter(_%2==0).toBuffer) //filter内部调用for循环,进行过滤 ArrayBuffer(2, 4, 6) |
三种for循环中,to包含最后一位,until不包含
高级for循环 -> 嵌套
scala> for(i <- 1 to 3; j <- 1 to 3 if i != j ) | print((10 * i + j)+ " ") 12 13 21 23 31 32 |
关键字yield -> 生成新集合
scala> val value = for(i <- 1 to 10) yield i * 10 value: scala.collection.immutable.IndexedSeq[Int] = Vector(10, 20, 30, 40, 50, 6 0, 70, 80, 90, 100) |
foreach的引用
map方法返回的是一个新的Array,会占用资源,foreach则直接输出结果,不返回数组
scala> arr res19: Array[Int] = Array(2, 3, 4, 6) scala> arr.map(x => print(x)) 2346res20: Array[Unit] = Array((), (), (), ()) scala> arr.foreach(print) 2346 scala> val r = print(2) 2r: Unit = () |
函数和方法
----------------------------------定义方法---------------------------------

没有返回类型不打印结果,除非在方法中print,或者加入默认Unit类型
scala> def test(x:Int,y:Int):Int = {x * y} test: (x: Int, y: Int)Int scala> test(3,4) res22: Int = 12 scala> def test1(x:Int,y:Int){x * y} test1: (x: Int, y: Int)Unit scala> test1(2,3) //不出结果,没有返回值类型 scala> def test3(x:Int,y:Int)={x * y} //如果加上=号,系统会自定判断数据类型 test3: (x: Int, y: Int)Int scala> test3(2,3) res8: Int = 6 scala> def test2(x:Int,y:Int){ | println(x * y)} test2: (x: Int, y: Int)Unit scala> test2(2,3) 6 //没有返回值,是print出来的 |
对于递归方法,必须指定返回类型
object digui { def main(args: Array[String]): Unit = { println(fab(3)) } def fab(n:Int):Int = { if (n <= 1) 1 else fab(n - 1) + fab(n - 2) } } |
-----------------------------------定义函数-----------------------------------

函数的返回值类型不能不写,可以写"()"
scala> val fun1 = (x:Int,y:Int) => x * y fun1: (Int, Int) => Int = <function2> scala> fun1(2,3) res9: Int = 6 scala> val fun2 = () =>10 fun2: () => Int = <function0> scala> fun2() res10: Int = 10 scala> fun2 res11: () => Int = <function0> |
调用函数:map提供数组
object func { def main(args: Array[String]): Unit = { val arr = Array(2,3,4,5,6,7) // val fun = (x:Int) => x*20 // val res = arr.map(fun) //第一种 // val res = arr.map((x:Int) => x*20) //第二种 val res = arr.map(_ *20) //第三种 println(res.toBuffer) //输出结果为 ArrayBuffer(40, 60, 80, 100, 120, 140) } } |
---------------------------方法与函数的区别-----------------------
在函数式编程语言中,函数是“头等公民”,它可以像任何其他数据类型一样被传递和操作
案例:首先定义一个方法,在定义一个函数,然后将函数传递给方法里面
object hanshu { //定义一个方法 def t1(f:(Int,Int) => Int) : Int = { f(2,3) } //定义函数 val f1=(x:Int,y:Int) => x * y val f2=(m:Int,n:Int) => m + n def main(args: Array[String]): Unit = { //调用函数方法 println(t1(f1)) //6 println(t1(f2)) //5 } } |
Array数组
数组常用算法
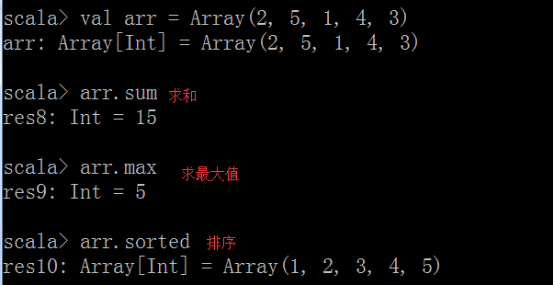
可变字符串导包 : import scala.collection.mutable.ArrayBuffer
定义集合时 : Array()不可变,ArrayBuffer()可变
导包后的字符串 (可变)

增加数据
scala> val arr2=new ArrayBuffer[Int](1) arr2: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer() scala> arr2 += 2 res24: arr2.type = ArrayBuffer(2) scala> arr2 += (3,4,5) res25: arr2.type = ArrayBuffer(2, 3, 4, 5) scala> arr2 ++= ArrayBuffer(1) res27: arr2.type = ArrayBuffer(2, 3, 4, 5, 1) |
从指定位置增加数据
scala> arr2.insert(0,20,21) scala> arr2 res29: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(20, 21, 2, 3, 4,5,1) |
删除元素
scala> arr2.remove(2,3) //第几个元素开始,到第几个元素结束 scala> arr2 res33: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(20, 21, 5, 1) |
反转
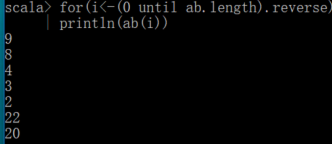
Map映射
首先导包 : import scala.collection.mutable.Map
定义map集合的两种方法
scala> val age = Map("jack"-> 20,"Leo"-> 21) //箭头创建 age: scala.collection.immutable.Map[String,Int] = Map(jack -> 20, Leo -> 21) scala> val age = Map(("jack"->20),("Leo"->30)) //元祖创建 age: scala.collection.immutable.Map[String,Int] = Map(jack -> 20, Leo -> 30) |
查看map集
scala> age("Leo") res0: Int = 30 scala> age res1: scala.collection.immutable.Map[String,Int] = Map(jack -> 20, Leo -> 30) |
修改map集指定参数
scala> age("Leo")->20 res3: (Int, Int) = (30,20) |
增加map集参数
scala> age += ("Mike"->18,"Heb"->23) res9: age.type = Map(jack -> 20, Mike -> 18, Heb -> 23, Leo -> 21) |
删除map集参数
scala> age - "Mike" res10: scala.collection.mutable.Map[String,Int] = Map(jack -> 20, Heb -> 23, Leo -> 21) |
循环遍历 (LinkedHashMap \ SortedMap)
scala> for((key,value) <- age) println(key+ " "+value) jack 20 Mike 18 Heb 23 Leo 21 scala> for(key <- age.keySet) println(key) jack Mike Heb Leo scala> for(value <- age.values) println(value) 20 18 23 21 |
---------------------元祖------------------------
小括号括起来的多种类型的值就叫元祖(tuple)
创建元祖
scala> val tuple = ("zhangsan",10,2.3,true) tuple: (String, Int, Double, Boolean) = (zhangsan,10,2.3,true) scala> val tuple,(a,b,c) = ("zhangsan",2,true) tuple: (String, Int, Boolean) = (zhangsan,2,true) a: String = zhangsan b: Int = 2 c: Boolean = true |
获取元祖: 元祖从1开始,数组从下标0开始取
scala> tuple._1 res14: String = zhangsan scala> tuple._3 res15: Boolean = true |
将数组转成map映射
scala> val arr = Array(("xixi",2),("haha",1),("heihei",3)) arr: Array[(String, Int)] = Array((xixi,2), (haha,1), (heihei,3)) scala> arr.toMap res16: scala.collection.immutable.Map[String,Int] = Map(xixi -> 2, haha -> 1, he ihei -> 3) |
拉链操作 : zip命令将多个值绑在一起
注意:如果两个数组的元素个数不一致,拉链操作后生成的数组的长度为较小的那个数组的元素个数
scala> val arr2 = Array(2,3,4) arr2: Array[Int] = Array(2, 3, 4) scala> arr zip arr2 res17: Array[((String, Int), Int)] = Array(((xixi,2),2), ((haha,1),3), ((heihei, 3),4)) |
映射是kv对偶的集合,对偶是元祖的最简单形式,称对偶元祖
scala支持的元祖长度最大为22(个元素)
----------------------集合----------------------
scala的集合有三个类:序列sep,集合set,映射Map
在scala中集合有可变mutable和不可变immutable(默认)两种类型
---------------------------序列--------------------------
- 不可变的序列 import scala.collection.immutable._
- 在Scala中列表要么为空(Nil表示空列表)要么是一个head元素加上一个tail列表。
- :: 表示右结合,列表从右开始向左结合
- 定义List时,List()不可变,ListBuffer()可变
package com.qf.collect object ImmutListDemo { def main(args: Array[String]) { //创建一个不可变的集合 val lst1 = List(1,2,3) //将0插入到lst1的前面生成一个新的List val lst2 = 0 :: lst1 val lst3 = lst1.::(0) val lst4 = 0 +: lst1 val lst5 = lst1.+:(0) //将一个元素添加到lst1的后面产生一个新的集合 val lst6 = lst1 :+ 3 //将2个list合并成一个新的List val lst0 = List(4,5,6) val lst7 = lst1 ++ lst0 //将lst0插入到lst1后面生成一个新的集合 val lst8 = lst1 ++: lst0 //将lst0插入到lst1前面生成一个新的集合 val lst9 = lst1.:::(lst0) println(lst9) } } |
----------------------------Set------------------------
不可变的
object ImmutableSet extends App{ val set1 = new HashSet[Int]() //将元素和set合并并生成一个新的set,原有的set不变 val set2 = set1 + 4 println(set2) //Set(4) //set中元素不能重复,自动去重 // val set3 = set2 ++ Set(5,6,7) //Set(5,6,7,4) val set3 = Set(2,3) ++ set2 println(set3) //Set(2,3,4) } |
可变的 set是无序的不可重复的
scala> import scala.collection.mutable._ import scala.collection.mutable._ scala> val set1 = HashSet(2,3,4) set1: scala.collection.mutable.HashSet[Int] = Set(2, 3, 4) scala> set1 += 1 res0: set1.type = Set(1, 2, 3, 4) scala> set1.add(4) res1: Boolean = false scala> set1.add(6) res2: Boolean = true scala> set1 res3: scala.collection.mutable.HashSet[Int] = Set(1, 2, 6, 3, 4) scala> set1 ++= HashSet(2,7) res4: set1.type = Set(1, 2, 6, 3, 7, 4) scala> set1 -= 1 res5: set1.type = Set(2, 6, 3, 7, 4) scala> set1.remove(2) res6: Boolean = true |
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



