如何进行批量SQL优化,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
有时在工作中,我们需要将大量的数据持久化到数据库中,如果数据量很大的话直接插入的执行速度非常慢,并且由于插入操作也没有太多能够进行sql优化的地方,所以只能从程序代码的角度进行优化。所以本文将尝试使用几种不同方式对插入操作进行优化,看看如何能够最大程度的缩短SQL执行时间。
以插入1000条数据为例,首先进行数据准备,用于插入数据库测试:
private List<Order> prepareData(){
List<Order> orderList=new ArrayList<>();
for (int i = 1; i <= 1000; i++) {
Order order=new Order();
order.setId(Long.valueOf(i));
order.setOrderNumber("A");
order.setMoney(100D);
order.setTenantId(1L);
orderList.add(order);
}
return orderList;
}首先测试直接插入1000条数据:
public void noBatch() {
List<Order> orderList = prepareData();
long startTime = System.currentTimeMillis();
for (Order order : orderList) {
orderMapper.insert(order);
}
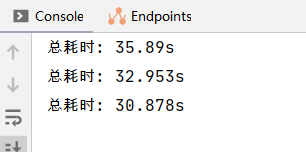
System.out.println("总耗时: " + (System.currentTimeMillis() - startTime) / 1000.0 + "s");
}执行时间如下:
接下来,使用mybatis-plus的批量查询,我们自己的Service接口需要继承IService接口:
public interface SqlService extends IService<Order> {
}在实现类SqlServiceImpl中直接调用saveBatch方法:
public void plusBatch() {
List<Order> orderList = prepareData();
long startTime = System.currentTimeMillis();
saveBatch(orderList);
System.out.println("总耗时: " + (System.currentTimeMillis() - startTime) / 1000.0 + "s");
}执行代码,查看运行时间:

可以发现,使用mybatis-plus的批量插入并没有比循环单条插入显著缩短时间,所以来查看一下saveBatch方法的源码:
@Transactional(rollbackFor = Exception.class)
@Override
public boolean saveBatch(Collection<T> entityList, int batchSize) {
String sqlStatement = sqlStatement(SqlMethod.INSERT_ONE);
return executeBatch(entityList, batchSize, (sqlSession, entity) -> sqlSession.insert(sqlStatement, entity));
}其中调用了executeBatch方法:
protected <E> boolean executeBatch(Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) {
Assert.isFalse(batchSize < 1, "batchSize must not be less than one");
return !CollectionUtils.isEmpty(list) && executeBatch(sqlSession -> {
int size = list.size();
int i = 1;
for (E element : list) {
consumer.accept(sqlSession, element);
if ((i % batchSize == 0) || i == size) {
sqlSession.flushStatements();
}
i++;
}
});
}在for循环中,consumer的accept执行的是sqlSession的insert操作,这一阶段都是对sql的拼接,只有到最后当for循环执行完成后,才会将数据批量刷新到数据库中。也就是说,之前我们向数据库服务器发起了1000次请求,但是使用批量插入,只需要发起一次请求就可以了。如果抛出异常,则会进行回滚,不会向数据库中写入数据。但是虽然减少了数据库请求的次数,对于缩短执行时间并没有显著的提升。
Stream是JAVA8中用于处理集合的关键抽象概念,可以进行复杂的查找、过滤、数据映射等操作。而并行流Parallel Stream,可以将整个数据内容分成多个数据块,并使用多个线程分别处理每个数据块的流。在大量数据的插入操作中,不存在数据的依赖的耦合关系,因此可以进行拆分使用并行流进行插入。测试插入的代码如下:
public void stream(){
List<Order> orderList = prepareData();
long startTime = System.currentTimeMillis();
orderList.parallelStream().forEach(order->orderMapper.insert(order));
System.out.println("总耗时: " + (System.currentTimeMillis() - startTime) / 1000.0 + "s");
}还是先对上面的代码进行测试:
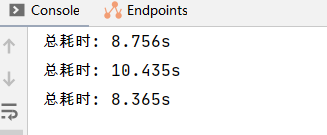
可以发现速度比之前快了很多,这是因为并行流底层使用了Fork/Join框架,具体来说使用了“分而治之”的思想,对任务进行了拆分,使用不同线程进行执行,最后汇总(对Fork/Join不熟悉的同学可以回顾一下请求合并与分而治之这篇文章,里面介绍了它的基础使用)。并行流在底层使用了ForkJoinPool线程池,从ForkJoinPool的默认构造函数中看出,它拥有的默认线程数量等于计算机的逻辑处理器数量:
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false);
}也就是说,如果我们服务器是逻辑8核的话,那么就会有8个线程来同时执行插入操作,大大缩短了执行的时间。并且ForkJoinPool线程池为了提高任务的并行度和吞吐量,采用了任务窃取机制,能够进一步的缩短执行的时间。
在并行流中,创建的ForkJoinPool的线程数量是固定的,那么通过手动修改线程池中线程的数量,能否进一步的提高执行效率呢?一般而言,在线程池中,设置线程数量等于处理器数量就可以了,因为如果创建过多线程,线程频繁切换上下文也会额外消耗时间,反而会增加执行的总体时间。但是对于批量SQL的插入操作,没有复杂的业务处理逻辑,仅仅是需要频繁的与数据库进行交互,属于I/O密集型操作。而对于I/O密集型操作,程序中存在大量I/O等待占据时间,导致CPU使用率较低。所以我们尝试增加线程数量,来看一下能否进一步缩短执行时间呢?
定义插入任务,因为不需要返回,直接继承RecursiveAction父类。size是每个队列中包含的任务数量,在构造方法中传入,如果一个队列中的任务数量大于它那么就继续进行拆分,直到任务数量足够小:
public class BatchInsertTask<E> extends RecursiveAction {
private List<E> list;
private BaseMapper<E> mapper;
private int size;
public BatchInsertTask(List<E> list, BaseMapper<E> mapper, int size) {
this.list = list;
this.mapper = mapper;
this.size = size;
}
@Override
protected void compute() {
if (list.size() <= size) {
list.stream().forEach(item -> mapper.insert(item));
} else {
int middle = list.size() / 2;
List<E> left = list.subList(0, middle);
List<E> right = list.subList(middle, list.size());
BatchInsertTask<E> leftTask = new BatchInsertTask<>(left, mapper, size);
BatchInsertTask<E> rightTask = new BatchInsertTask<>(right, mapper, size);
invokeAll(leftTask, rightTask);
}
}
}使用ForkJoinPool运行上面定义的任务,线程池中的线程数取CPU线程的2倍,将执行的SQL条数均分到每个线程的执行队列中:
public class BatchSqlUtil {
public static <E> void runSave(List<E> list, BaseMapper<E> mapper) {
int processors = getProcessors();
ForkJoinPool forkJoinPool = new ForkJoinPool(processors);
int size = (int) Math.ceil((double)list.size() / processors);
BatchInsertTask<E> task = new BatchInsertTask<E>(list, mapper, size);
forkJoinPool.invoke(task);
}
private static int getProcessors() {
int processors = Runtime.getRuntime().availableProcessors();
return processors<<=1;
}
}启动测试代码:
public void batch() {
List<Order> orderList = prepareData();
long startTime = System.currentTimeMillis();
BatchSqlUtil.runSave(orderList,orderMapper);
System.out.println("总耗时: " + (System.currentTimeMillis() - startTime) / 1000.0 + "s");
}查看运行时间:
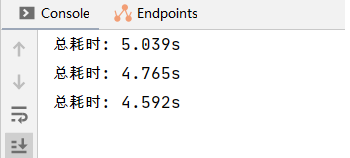
可以看到,通过增加ForkJoinPool中的线程,可以进一步的缩短批量插入的时间。
关于如何进行批量SQL优化问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4964433/blog/5010537



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



