本篇文章给大家分享的是有关Python中怎么实现一个时间序列,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
时间序列 在时间上是顺序的一系列数据点索引(或列出的或绘制)的。最常见的是,时间序列是在连续的等间隔时间点上获取的序列。因此,它是一系列离散时间数据。时间序列的示例包括海潮高度,黑子数和道琼斯工业平均指数的每日收盘价。
我们将看到一些重要的点,可以帮助我们分析任何时间序列数据集。这些是:
在Pandas中正确加载时间序列数据集
时间序列数据索引
使用Pandas进行时间重采样
滚动时间序列
使用Pandas绘制时间序列数据
让我们在Pandas中加载上述数据集。

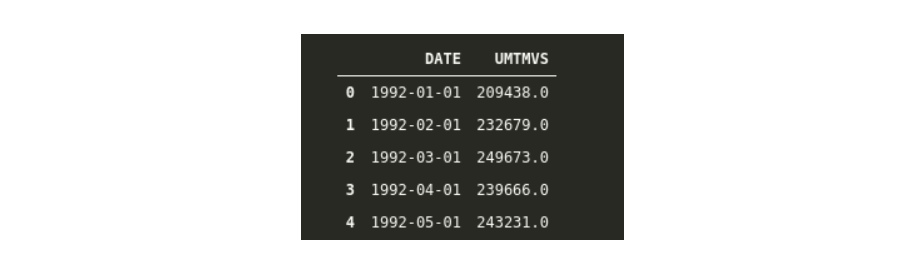
由于我们希望将“ DATE”列作为索引,而只是通过读取就可以了,因此,我们必须添加一些额外的参数。
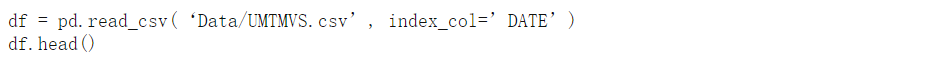
太好了,现在我们将DATE列添加为索引,但是让我们检查它的数据类型以了解pandas是作为简单对象还是pandas内置的DateTime数据类型来处理索引。
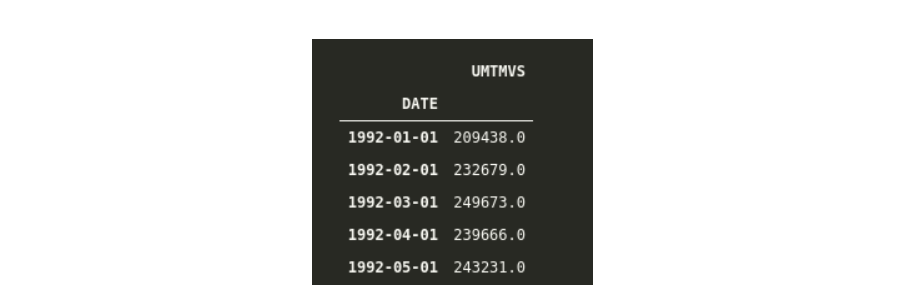
太好了,现在我们将DATE列添加为索引,但是让我们检查它的数据类型以了解pandas是作为简单对象还是pandas内置的DateTime数据类型来处理索引。

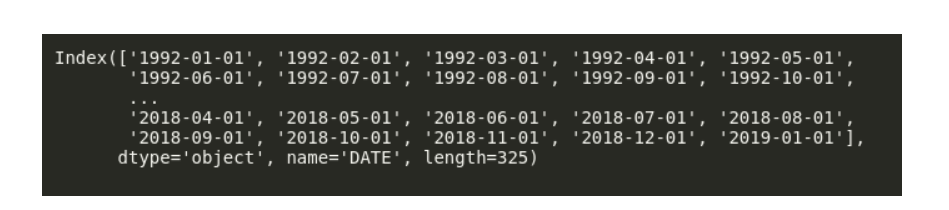
在这里,我们可以看到Pandas将Index列作为一个简单对象处理,因此让我们将其转换为DateTime。我们可以做到如下:

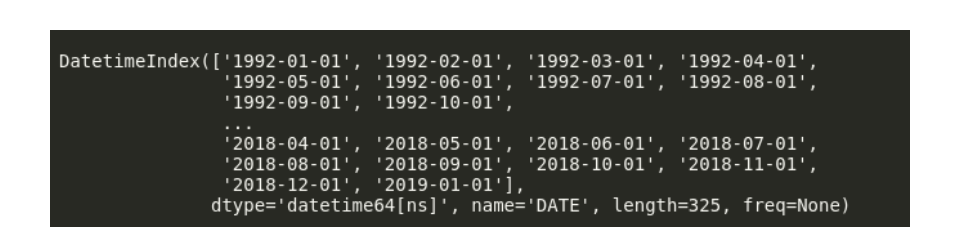
现在我们可以看到 我们的数据集的dtype是 datetime64 [ns]。此“ [ns]”表明它的精确度为纳秒。如果需要,我们可以将其更改为“天”或“月”。
另外,为了避免这些麻烦,我们可以使用Pandas在单行代码中加载数据,如下所示。


在这里,我们添加了 parse_dates = True,因此它将自动使用我们的 索引 作为日期。
比方说,我想获得的所有数据从 2000-01-01 至 2015年5月1日。为此,我们可以像这样在Pandas中简单地使用索引。

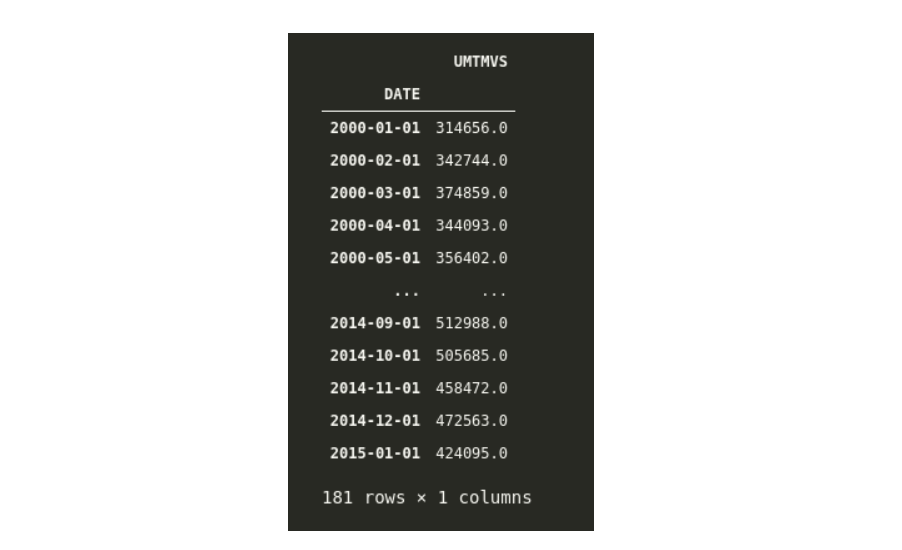
这里我们提供了从2000-01-01 到 2015-01-01的所有月份的数据 。
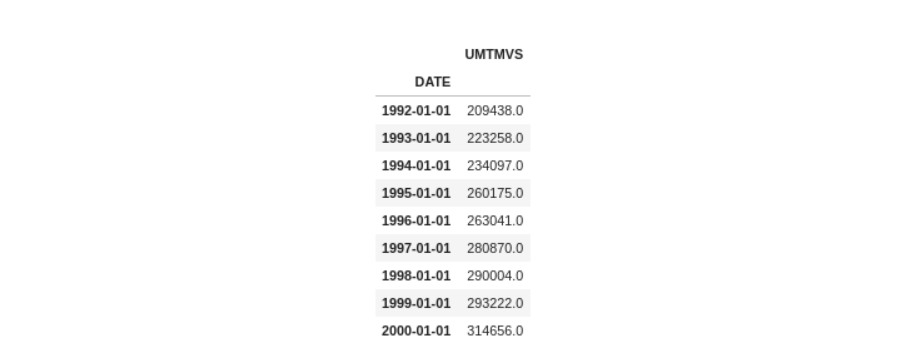
比方说,我们希望所有的头几个月中的所有数据得到 1992-01-01 至 2000-01-01。我们可以简单地通过添加另一个参数来实现它,该参数类似于在python中对列表进行切片时,最后添加一个step参数。
在Pandas中,此语法为 ['starting date':'end date':step]。现在,如果我们观察数据集,它是以月格式的,因此我们需要从1992年到2000年的每12个月一次的数据。我们可以按以下方式进行操作。

以上就是Python中怎么实现一个时间序列,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4662955/blog/4662670



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



