这期内容当中小编将会给大家带来有关K8s中如何进行优雅停机和零宕机部署,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
创建、删除 Pod 是 K8s 中最常见的任务之一。下面介绍了 Pod 在响应创建、删除请求时发生的内部流程,还讨论了如何在 Pod 启动或关闭时防止断开连接,以及如何正常关闭长时间运行的任务。
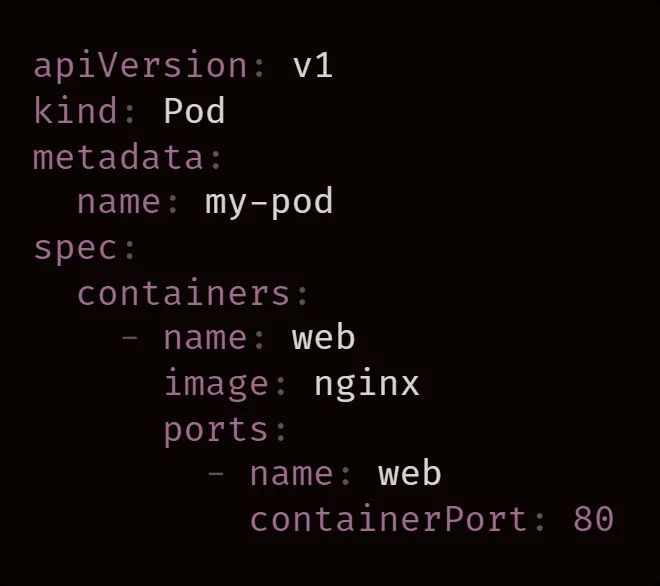

在输入命令后,kubectl 就会将 Pod 定义提交给 Kubernetes API。
在数据库中保存集群状态
API 接收并检查 Pod 定义,然后将其存储在 etcd 数据库中。另外,Pod 将被添加到调度程序的队列中。
Kubelet
kubelet 的工作是轮询控制平面以获取更新。kubelet 不会自行创建 Pod,而是将工作交给其他三个组件:
如果 Pod 不是任何 Service 的一部分,那到这里就结束了,因为 Pod 已经创建完毕并可以使用,但如果 Pod 是 Service 的一部分,那还有几个步骤需要执行。
Pod 和 Service
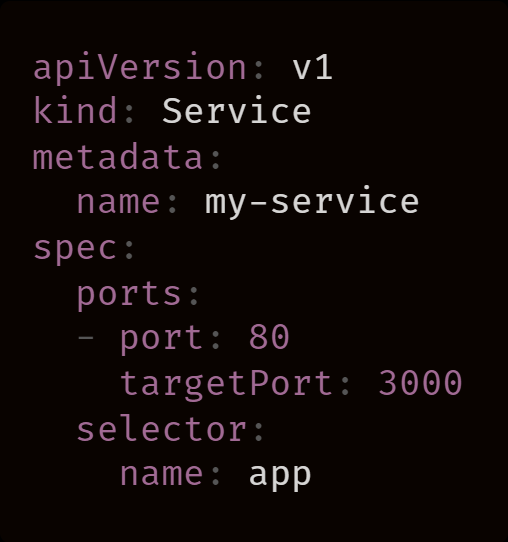
在创建 Service 时,我们需要注意两点信息:
kubectl apply
将 Service 提交给集群时,Kubernetes 会找到所有和选择器(name: app)有着相同标签的 Pod,并收集其 IP 地址,当然它们需要先通过 Readiness 探针,然后再将每个 IP 地址都和端口连接在一起。
10.0.0.3
,
targetPort
是 3000,Kubernetes 会将这两个值连接起来称为 endpoint。
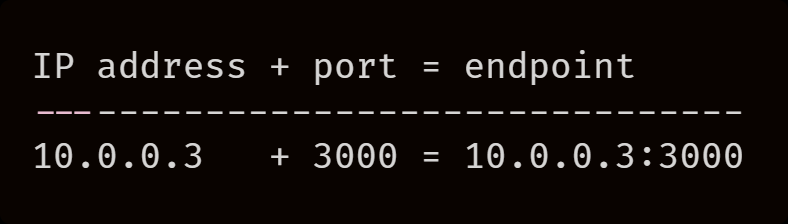
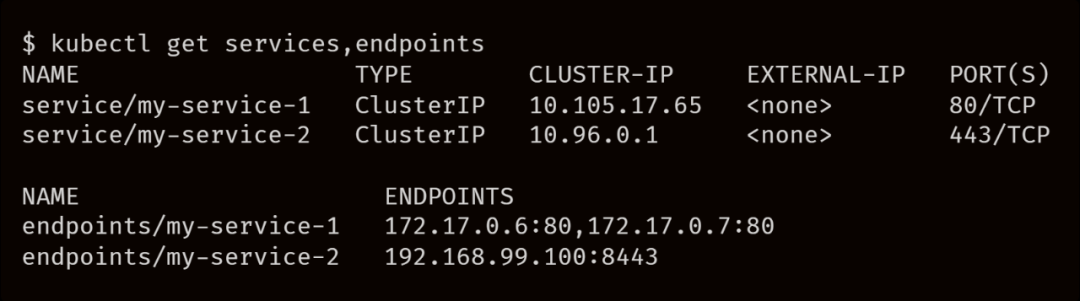
endpoint 存储在控制平面中,Endpoint 对象也会更新。
在 Kubernetes 中使用 endpoint
endpoint 被 Kubernetes 中的多个组件所使用。Kube-proxy 使用 endpoint 在节点上设置 iptables 规则。因此,每次对 Endpoint 对象进行更改时,kube-proxy 都会检索 IP 地址和 endpiont 新列表,以编写新的 iptables 规则。

删除 Pod
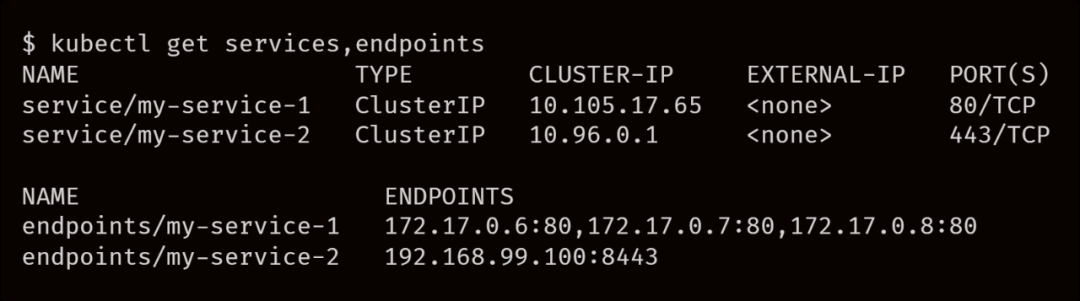
删除 Pod 时,我们要遵循上文相同的步骤,不过是相反的。首先,我们从 Endpoint 对象中删除 endpiont,但这次“readiness”探针会被忽略,endpiont 会立即从控制平面中移除,然后再依次触发所有事件到 kube-proxy,Ingress 控制器、DNS、服务网格等。这些组件将更新其内部状态,并停止将流量路由到 IP 地址。
创建 Pod 时,Kubernetes 会等待 kubelet 报告 IP 地址,然后进行 endpoint 广播,但删除 Pod 时,这些事件是并行开始的。这可能会导致一些条件竞争。如果在 endpoint 广播之前删除Pod怎么办?
优雅停机
当 Pod 在 kube-proxy 或 Ingress 控制器删除之前终止,我们可能会遇到停机时间。此时,Kubernetes 仍将流量路由到 IP 地址,但 Pod 已经不存在了。Ingress 控制器、kube-proxy、CoreDNS 等也没有足够的时间从其内部状态中删除 IP地址。
terminationGracePeriodSeconds
)。如果我们无法更改代码以获得更长的等待时间要怎么办?我们可以调用脚本以获得固定的等待时间,然后退出应用程序。
preStop
hook。我们可以将
preStop
hook 设置为等待 15 秒。下面是一个例子:

preStop hook 是 Pod LifeCycle hook 之一。
宽限期和滚动更新
优雅停机适用于要删除的 Pod,但如果我们不删除 Pod,会怎么样?其实即使我们不做,Kubernetes 也会删除 Pod。在每次部署较新版本的应用程序时,Kubernetes 都会创建、删除 Pod。
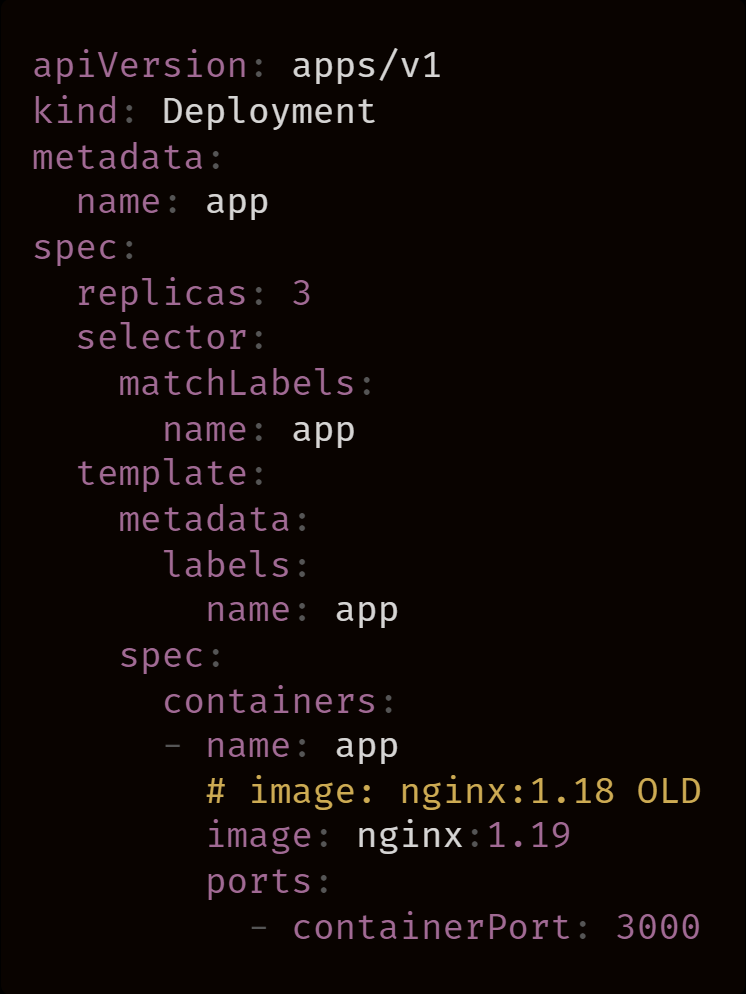
1.用新的容器镜像创建一个 Pod。
2.销毁现有的 Pod。
3.等待 Pod 准备就绪。
它会不断重复上述步骤,直到将所有 Pod 迁移到较新的版本。Kubernetes 在新 Pod 准备接收流量之后会重复每个周期。另外,Kubernetes 不会在转移 Pod 前等待 Pod 被删除。如果我们有 10 个 Pod,并且 Pod 需要 2 秒钟的准备时间和 20 秒的关闭时间,就会发生以下情况:
1.创建一个 Pod,终止前一个 Pod。
2.Kubernetes 创建一个新的 Pod 后,需要 2 秒钟的准备时间。
3.同时,被终止的 Pod 会有 20 秒的停止时间。
终止长时间运行的任务
如果我们要对大型视频进行转码,是否有任何方法可以延迟停止 Pod?
terminationGracePeriodSeconds
增加到几个小时,但这样 Pod 的 endpoint 将 unreachable。如果我们公开指标以监控 Pod,instrumentation 将无法访问 Pod。Prometheus 之类的工具依赖于 Endpoints 在集群中 scrape Pod。一旦删除 Pod,endpoint 删除信息就会在集群中传播,甚至传播到 Prometheus。
如果想自动删除,那我们可以需要设置一个自动伸缩器,当它们完成任务时,可以将 Deployment 扩展到零个副本。
我们应该注意 Pod 从集群中删除后,它们的 IP 地址可能仍用于路由流量。相比立即关闭 Pod,我们不如在应用程序中等待一下或设置一个 preStop hook。在 endpoint 传播到集群中,并且 Pod 从 kube-proxy、Ingress 控制器、CoreDNS 等中删除后,Pod 才算被移除。
上述就是小编为大家分享的K8s中如何进行优雅停机和零宕机部署了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/cncf/blog/4504917



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



