这篇文章主要讲解了“机器学习中使用kNN算法的问题有哪些”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“机器学习中使用kNN算法的问题有哪些”吧!
A)真 B)假
解决方案:A
该算法的训练阶段仅包括存储训练样本的特征向量和类别标签。
在测试阶段,通过分配最接近该查询点的k个训练样本中最频繁使用的标签来对测试点进行分类——因此需要更高的计算量。

A) 3 B) 10 C) 20 D) 50 解决方案:B
当k的值为10时,验证误差最小。
A) Manhattan B) Minkowski C) Tanimoto D) Jaccard E) Mahalanobis F)都可以使用
解决方案:F
所有这些距离度量都可以用作k-NN的距离度量。
A)可用于分类 B)可用于回归 C)可用于分类和回归
解决方案:C
我们还可以将k-NN用于回归问题。在这种情况下,预测可以基于k个最相似实例的均值或中位数。
如果所有数据的比例均相同,则k-NN的效果会更好
k-NN在少数输入变量(p)下工作良好,但在输入数量很大时会遇到困难
k-NN对所解决问题的函数形式没有任何假设
A)1和2 B)1和3 C)仅1 D)以上所有
解决方案:D
以上陈述是kNN算法的假设
A)K-NN B)线性回归 C)Logistic回归
解决方案:A
k-NN算法可用于估算分类变量和连续变量的缺失值。
A)可用于连续变量 B)可用于分类变量 C)可用于分类变量和连续变量 D)无
解决方案:A
曼哈顿距离是为计算实际值特征之间的距离而设计的。
汉明距离
欧氏距离
曼哈顿距离
A)1 B)2 C)3 D)1和2 E)2和3 F)1,2和3
解决方案:A
在连续变量的情况下使用欧氏距离和曼哈顿距离,而在分类变量的情况下使用汉明距离。
A)1 B)2 C)4 D)8
解决方案:A
sqrt((1-2)^ 2 +(3-3)^ 2)= sqrt(1 ^ 2 + 0 ^ 2)= 1
A)1 B)2 C)4 D)8
解决方案:A
sqrt(mod((1-2))+ mod((3-3)))= sqrt(1 + 0)= 1
假设你给出了以下数据,其中x和y是2个输入变量,而Class是因变量。

以下是散点图,显示了2D空间中的上述数据。
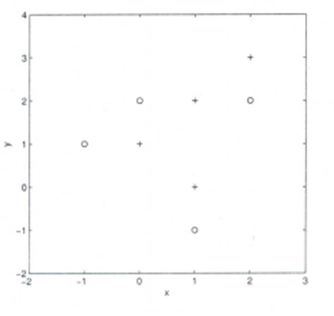
A)+ 类 B)– 类 C)不能判断 D)这些都不是
解决方案:A
所有三个最近点均为 + 类,因此此点将归为+ 类。
A)+ 类 B)– 类
C)不能判断
解决方案:B
现在,此点将归类为 – 类,因为在最近的圆圈中有4个 – 类点和3个 + 类点。
假设你提供了以下2类数据,其中“+”代表正类,“-”代表负类。
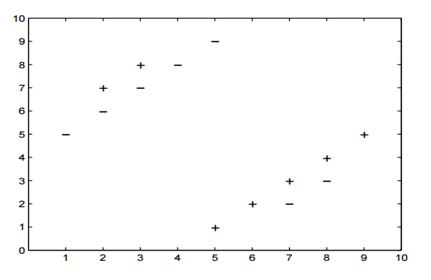
A)3 B)5 C)两者都相同 D)没有一个
解决方案:B
5-NN将至少留下一个交叉验证错误。
A)2/14 B)4/14 C)6/14 D)8/14 E)以上都不是
解决方案:E
在5-NN中,我们将有10/14的交叉验证精度。
A)当你增加k时,偏差会增加 B)当你减少k时,偏差会增加 C)不能判断 D)这些都不是
解决方案:A
大K表示简单模型,简单模型始终被视为高偏差
A)当你增加k时,方差会增加 B)当你减少k时,方差会增加 C)不能判断 D)这些都不是
解决方案:B
简单模型将被视为方差较小模型
你的任务是通过查看以下两个图形来标记两个距离。关于下图,以下哪个选项是正确的?

A)左为曼哈顿距离,右为欧几里得距离 B)左为欧几里得距离,右为曼哈顿距离 C)左或右都不是曼哈顿距离 D)左或右都不是欧几里得距离 解决方案:B
左图是欧几里得距离的工作原理,右图是曼哈顿距离。
A)我将增加k的值 B)我将减少k的值 C)噪声不能取决于k D)这些都不是
解决方案:A
为了确保你进行的分类,你可以尝试增加k的值。
降维
特征选择
A)1 B)2 C)1和2 D)这些都不是
解决方案:C
在这种情况下,你可以使用降维算法或特征选择算法
k-NN是一种基于记忆的方法,即分类器会在我们收集新的训练数据时立即进行调整。
在最坏的情况下,新样本分类的计算复杂度随着训练数据集中样本数量的增加而线性增加。
A)1 B)2 C)1和2 D)这些都不是
解决方案:C
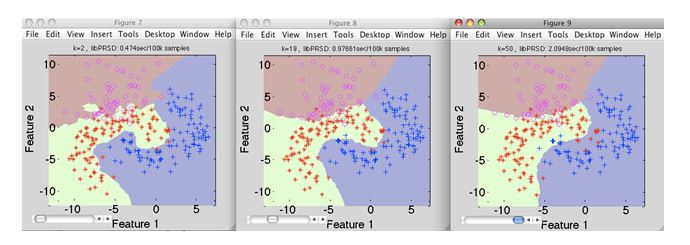
A)k1 > k2 > k3 B)k1 < k2 C)k1 = k2 = k3 D)这些都不是
解决方案:D
k值在k3中最高,而在k1中则最低
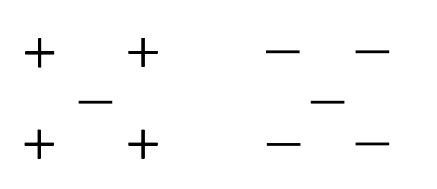
A)1 B)2 C)3 D)5 解决方案:B
如果将k的值保持为2,则交叉验证的准确性最低。你可以自己尝试。
注意:模型已成功部署,除了模型性能外,在客户端没有发现任何技术问题
A)可能是模型过拟合 B)可能是模型未拟合 C)不能判断 D)这些都不是
解决方案:A
在一个过拟合的模块中,它似乎会在训练数据上表现良好,但它还不够普遍,无法在新数据上给出相同的结果。
如果k的值非常大,我们可以将其他类别的点包括到邻域中。
如果k的值太小,该算法会对噪声非常敏感
A)1 B)2 C)1和2 D)这些都不是
解决方案:C
这两个选项都是正确的,并且都是不言而喻的。
A) k值越大,分类精度越好
B) k值越小,决策边界越光滑
C) 决策边界是线性的
D) k-NN不需要显式的训练步骤
解决方案:D
选项A:并非总是如此。你必须确保k的值不要太高或太低。
选项B:此陈述不正确。决策边界可能有些参差不齐
选项C:与选项B相同
选项D:此说法正确
A)真 B)假
解决方案:A
你可以通过组合1-NN分类器来实现2-NN分类器
A) K值越大,边界越光滑
B) 随着K值的减小,边界变得更平滑
C) 边界的光滑性与K值无关
D) 这些都不是
解决方案:A
通过增加K的值,决策边界将变得更平滑
我们可以借助交叉验证来选择k的最优值
欧氏距离对每个特征一视同仁
A)1 B)2 C)1和2 D)这些都不是
解决方案:C
两种说法都是正确的
注意:计算两个观测值之间的距离将花费时间D。
A)N * D B)N * D * 2 C)(N * D)/ 2 D)这些都不是
解决方案:A
N的值非常大,因此选项A是正确的
A)1-NN > 2-NN > 3-NN B)1-NN < 2-NN < 3-NN C)1-NN ~ 2-NN ~ 3-NN D)这些都不是
解决方案:C
在kNN算法中,任何k值的训练时间都是相同的。
以下是参与者的分数分布:
感谢各位的阅读,以上就是“机器学习中使用kNN算法的问题有哪些”的内容了,经过本文的学习后,相信大家对机器学习中使用kNN算法的问题有哪些这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4253699/blog/4649873



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



