这篇文章给大家介绍kafka工作原理分析怎样的,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
1.关于kafka
Kafka是由Apache软件基金会开发的一个开源消息队列,由Scala和Java编写。
相关文章参考:
MQ: 消息队列常见应用场景及主流消息队列ActiveMQ、RabbitMQ、RocketMQ和Kafka的简单对比
MQ: kafka的Java接入与入门示例(topic增删改查,Producer多参发送,Consumer多分区接受)
2.工作原理
首先,我们来kafka的整体数据流架构图:
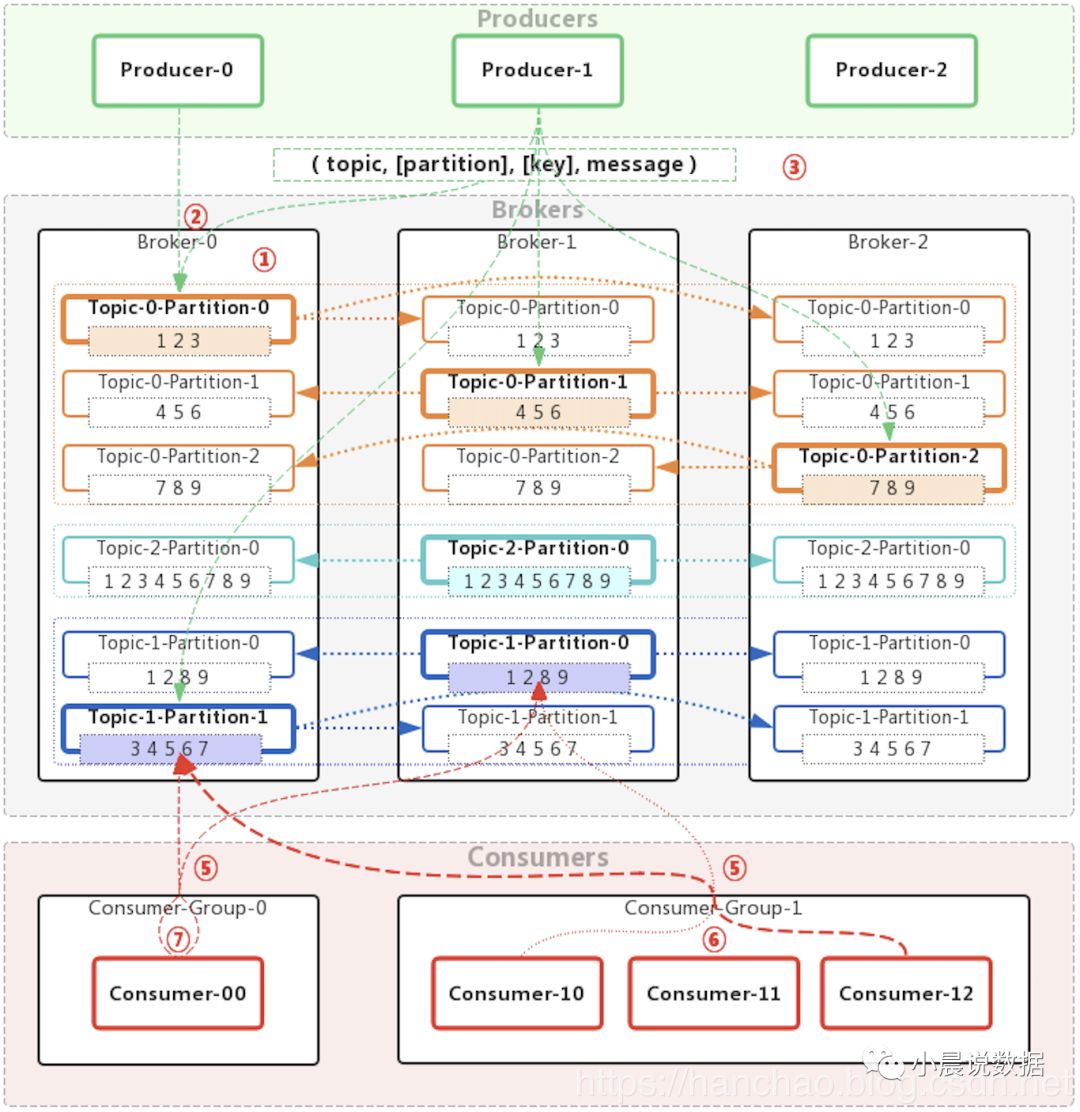
2.1.相关术语
上图中,涉及以下术语:
Producer:消息生产者,生产消息,然后push到消息队列。
Broker:消息中间人,消息的存储容器。
Consumer:消息消费者,从消息队列中pull数据,进行消费。
Topic:消息话题,消息在业务角度的划分,用于区分不同种类的消息。
Partition:消息分区,消息在存储上的逻辑划分(10条消息,5条存于分区1,5条存于分区2),用于加快消息消费速度,提示消息消费吞吐量。
Consumer Group:消息消费者组,可以区分不同种类的消费者,用于实现点对点模式和发布订阅模式。
其他术语Key、Leader、Replicas、ISR在后续章节中逐步介绍。
2.2.消息存储相关
想要弄清楚kafka的工作原理,首先应该对消息的存储结构进行掌握。
区分消息的逻辑概念是话题Topic,Topic存储于Broker之中,如下图所示:
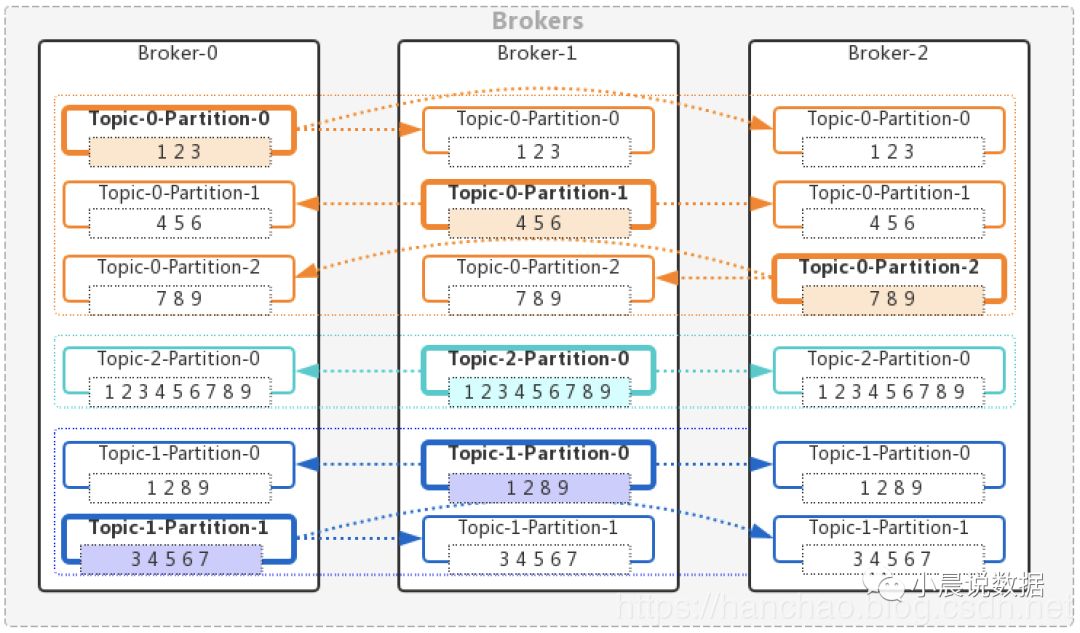
为了便于理解,我们直接看图说话:
Broker与Topic
图中的Broker集群实际是由3个Broker构成的,其实每个Broker就是一个Kafka服务节点。
图中共有3个Topic:橙色为Topic-0,提夫尼蓝为Topic-2,深蓝色为Topic-1。
Topic与Partition
单看Topic-0-Partition-0:Broker中消息容器的最小单元为Partition,Partition存储了一条条的消息。
单看Broker-1:
Topic可有多个Partition,如Topic-1有2个分区;若共计9条消息,则可能2个分区分别存储了4、5条消息。
Topic可只有1个Partition,如Topic-2;若共计9条消息,则这个单独的分区存储了9条消息。
分区存储哪条消息取决于Producer发送消息时的选择,相关内容后续章节介绍。
多副本冗余机制
单看Topic-2:
粗框Partition表示Leader(主)分区,负责读写消息;
细框Partition表示Replicas(从)分区,被动复制Leader,复制冗余容灾。
如果Broker-1挂掉,则Topic-2-Partition-0的Leader挂掉,从其余两个Replicas中选举出新的Leader继续提供服务。
Replicas的数量不能超过Broker的数量,因为一个Broker上存在多个Replicas与存在一个Replicas的效果是一样的。
Replicas的数量可以小于Broker的数量。
再看Topic-0:
每个Partition都会有Leader和Replicas。
kafka会尽量打散同一Topic的分区Leader,如图,3个Leader分布于3个Broker中。
分区Leader的分散分布不是绝对的,比方说此时只有一个Broker,则3个分区都是Leader,都分布在同一个Broker上。
分区的数量可以大于Broker的数量,因为分区存在的目的是加快消息消费速度,与冗余容灾无关。
相对有序性
Topic-0的3个分区的消息分别是:1、2、3,4、5、6,7、8、9。
Topic-1的2个分区的消息分别是:1、2、8、9,4、5、6、7。
Topic-2的1个分区的消息是:1、2、3、4、5、6、7、8、9。
相对有序性:单个partition内消息有序,多个partition间消息无序。
kafka通过在Partition中标记offset,来记录消息的顺序。
如果业务场景追求全局有序性,则每个Topic只配置一个Partition即可。
Producer消息生产语义
消息最多发送一次:第一种方式:异步发送消息。第二种方式:同步发送消息并且重试次数为0。
消息最少发送一次:同步发送消息,失败与超时重试,知道消息发送成功。
2.3.消息生产相关
搞清楚消息的存储之后,我们再来看消息的生产:
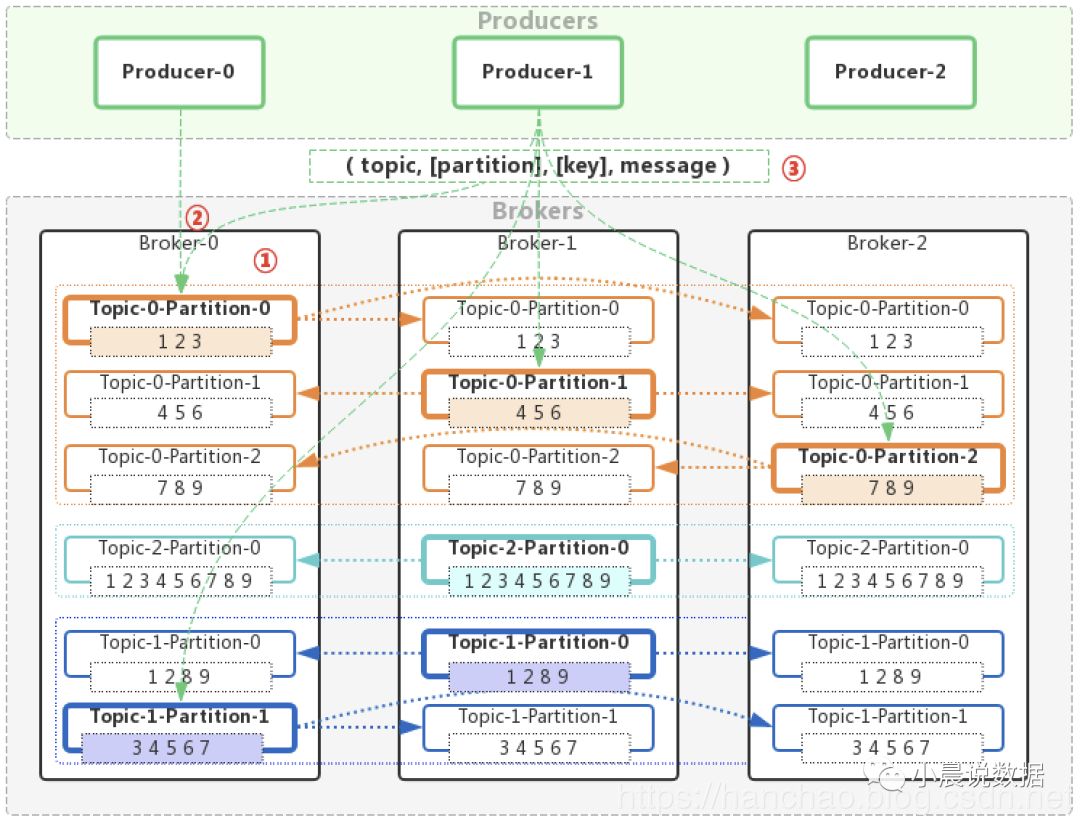
为了便于理解,我们直接看图说话:
①:一个Producer可以向多个Topic、多个Partition发送消息。
②:多个Producer可以向同一个Topic、同一个Partition发送消息。
③:消息发送参数:( topic, [partition], [key], message )
topic必填;message即消息本身,必填。
partition选填。如未填,则判断key是否存在,若key不存在,则随机选分区。
key选填。如填写,则根据key哈希之后取模分区数量的结果,选择分区;如未填,则随机选分区。
随机选分区:优先使用缓存的随机分区;若缓存为空,则随机选分区,然后将随机分区存入缓存,供下次使用。
2.4.消息消费相关
我们继续学习消息的消费:
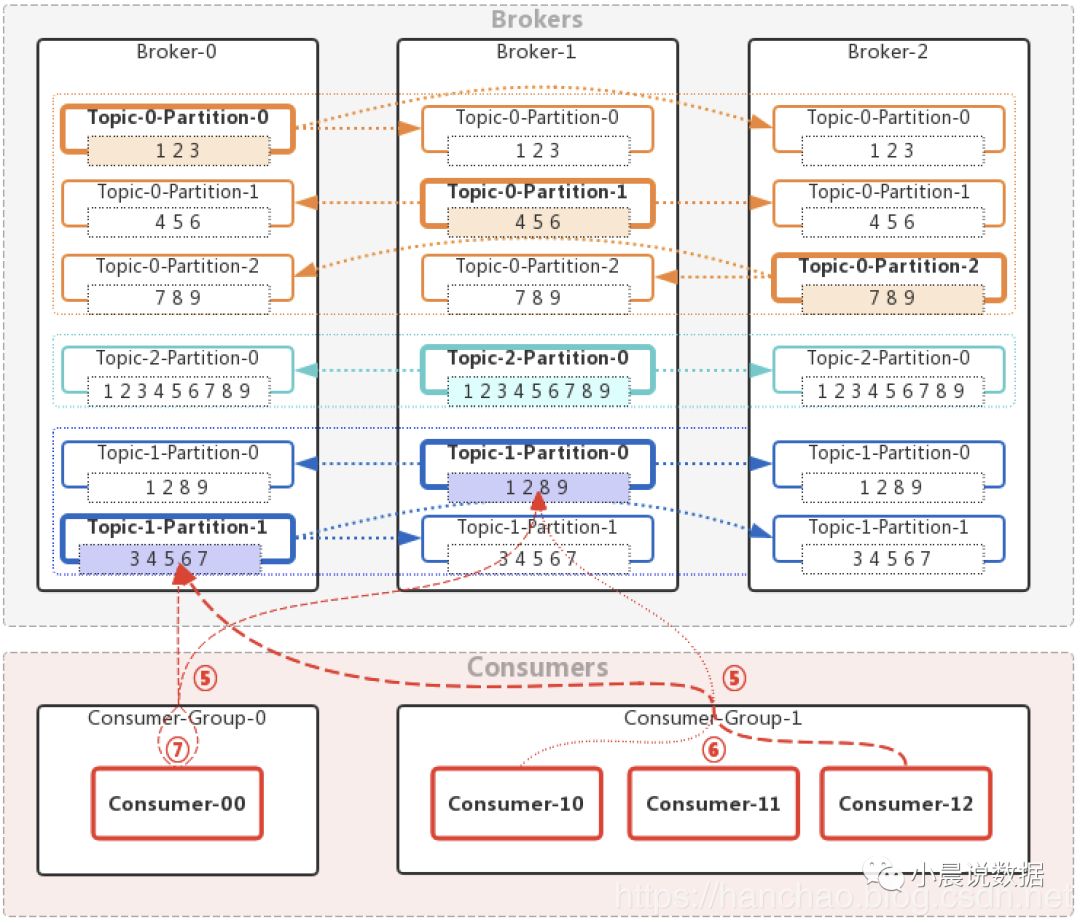
为了便于理解,我们直接看图说话:
消息消费方式
消息消费的箭头方向:kafka消费消息的方式只有pull,没有push。
push的优势在于实时性高,但是容易因Producer生产消息过快压垮Consumer。
pull的优势在于可以控制消费速度,但是容易出现空轮训。
kafka对pull的优化:通过配置使得只有当数据存在且到达一定量级,才进行pull。
Consumer Group与Consumer
⑥⑦:一个Consumer-Group可以有多个Consumer,也可以只有1个Consumer。
⑤:一个Topic-Partition的消息可以被多个Consumer-Group消费,注意:是Consumer-Group,而不是Consumer。
⑦:若Consumer-Group只有1个Consumer,则这个Partition中的所有消息都被这个Consumer消费。
⑥:若Consumer-Group有多个Consumer,且在正常连接期间:
单个Partition的消息只能被其中一个Consumer消费,不能被Consumer-Group内的多个Consumer消费。
多个Partition的消息可以被一个Consumer消费。
若单个Topic的分区数量小于Consumer-Group内的Consumer个数,则会存在Consumer接受不到这个Topic的消息。
Consumer消息消费语义
消息最多消费一次:1.读取消息,2,确认offset,3.处理消息。
消息最少消费一次:1.读取消息,2.处理消息,3.确认offset。
关于kafka工作原理分析怎样的就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4658124/blog/4643963



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



