小编给大家分享一下storm如何实现单机版安装,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
Storm是一个分布式的、高容错的实时计算系统。
Storm对于实时计算的的意义相当于Hadoop对于批处理的意义。Hadoop为我们提供了Map和Reduce原语,使我们对数据进行批处理变的非常的简单和优美。同样,Storm也对数据的实时计算提供了简单Spout和Bolt原语。
Storm适用的场景:
1、流数据处理:Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中。
2、分布式RPC:由于Storm的处理组件都是分布式的,而且处理延迟都极低,所以可以Storm可以做为一个通用的分布式RPC框架来使用。
在这个教程里面我们将学习如何创建Topologies, 并且把topologies部署到storm的集群里面去。Java将是我们主要的示范语言, 个别例子会使用python以演示storm的多语言特性。
这个教程使用storm-starter项目里面的例子。我推荐你们下载这个项目的代码并且跟着教程一起做。先读一下:配置storm开发环境和新建一个strom项目这两篇文章把你的机器设置好。
storm的集群表面上看和hadoop的集群非常像。但是在Hadoop上面你运行的是MapReduce的Job, 而在Storm上面你运行的是Topology。它们是非常不一样的 — 一个关键的区别是: 一个MapReduce Job最终会结束, 而一个Topology运永远运行(除非你显式的杀掉他)。
在Storm的集群里面有两种节点: 控制节点(master node)和工作节点(worker node)。控制节点上面运行一个后台程序: Nimbus, 它的作用类似Hadoop里面的JobTracker。Nimbus负责在集群里面分布代码,分配工作给机器, 并且监控状态。
每一个工作节点上面运行一个叫做Supervisor的节点(类似 TaskTracker)。Supervisor会监听分配给它那台机器的工作,根据需要 启动/关闭工作进程。每一个工作进程执行一个Topology(类似 Job)的一个子集;一个运行的Topology由运行在很多机器上的很多工作进程 Worker(类似 Child)组成。
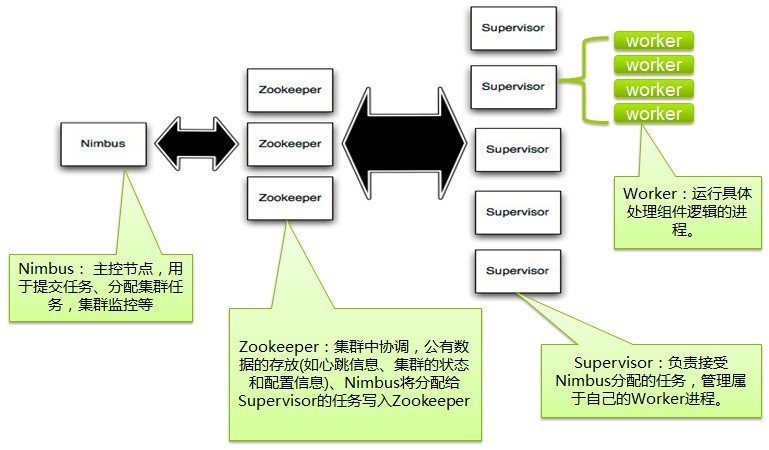
storm topology结构
bolt可以接收任意多个输入stream, 作一些处理, 有些bolt可能还会发射一些新的stream。一些复杂的流转换, 比如从一些tweet里面计算出热门话题, 需要多个步骤, 从而也就需要多个bolt。 Bolt可以做任何事情: 运行函数, 过滤tuple, 做一些聚合, 做一些合并以及访问数据库等等。
Bolt处理输入的Stream,并产生新的输出Stream。Bolt可以执行过滤、函数操作、Join、操作数据库等任何操作。Bolt是一个被动的角色,其接口中有一个execute(Tuple input)方法,在接收到消息之后会调用此函数,用户可以在此方法中执行自己的处理逻辑。
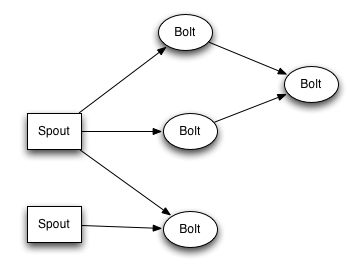
topology结构
topology里面的每一个节点都是并行运行的。 在你的topology里面, 你可以指定每个节点的并行度, storm则会在集群里面分配那么多线程来同时计算。
一个topology会一直运行直到你显式停止它。storm自动重新分配一些运行失败的任务, 并且storm保证你不会有数据丢失, 即使在一些机器意外停机并且消息被丢掉的情况下。
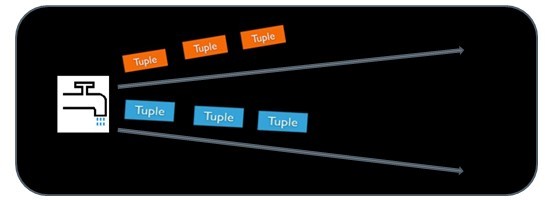
storm使用tuple来作为它的数据模型。每个tuple是一堆值,每个值有一个名字,并且每个值可以是任何类型, 在我的理解里面一个tuple可以看作一个没有方法的java对象。总体来看,storm支持所有的基本类型、字符串以及字节数组作为tuple的值类型。你也可以使用你自己定义的类型来作为值类型, 只要你实现对应的序列化器(serializer)。
一个Tuple代表数据流中的一个基本的处理单元,例如一条cookie日志,它可以包含多个Field,每个Field表示一个属性。

Tuple本来应该是一个Key-Value的Map,由于各个组件间传递的tuple的字段名称已经事先定义好了,所以Tuple只需要按序填入各个Value,所以就是一个Value List。
一个没有边界的、源源不断的、连续的Tuple序列就组成了Stream。
topology里面的每个节点必须定义它要发射的tuple的每个字段。 比如下面这个bolt定义它所发射的tuple包含两个字段,类型分别是: double和triple。
publicclassDoubleAndTripleBoltimplementsIRichBolt {
privateOutputCollectorBase _collector;
@Override
publicvoidprepare(Map conf, TopologyContext context, OutputCollectorBase collector) {
_collector = collector;
}
@Override
publicvoidexecute(Tuple input) {
intval = input.getInteger(0);
_collector.emit(input,newValues(val*2, val*3));
_collector.ack(input);
}
@Override
publicvoidcleanup() {
}
@Override
publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(newFields("double","triple"));
}
}declareOutputFields方法定义要输出的字段 : ["double", "triple"]。这个bolt的其它部分我们接下来会解释。
让我们来看一个简单的topology的例子, 我们看一下storm-starter里面的ExclamationTopology:
TopologyBuilder builder =newTopologyBuilder();
builder.setSpout(1,newTestWordSpout(),10);
builder.setBolt(2,newExclamationBolt(),3)
.shuffleGrouping(1);
builder.setBolt(3,newExclamationBolt(),2)
.shuffleGrouping(2);这个Topology包含一个Spout和两个Bolt。Spout发射单词, 每个bolt在每个单词后面加个”!!!”。这三个节点被排成一条线: spout发射单词给第一个bolt, 第一个bolt然后把处理好的单词发射给第二个bolt。如果spout发射的单词是["bob"]和["john"], 那么第二个bolt会发射["bolt!!!!!!"]和["john!!!!!!"]出来。
我们使用setSpout和setBolt来定义Topology里面的节点。这些方法接收我们指定的一个id, 一个包含处理逻辑的对象(spout或者bolt), 以及你所需要的并行度。
这个包含处理的对象如果是spout那么要实现IRichSpout的接口, 如果是bolt,那么就要实现IRichBolt接口.
最后一个指定并行度的参数是可选的。它表示集群里面需要多少个thread来一起执行这个节点。如果你忽略它那么storm会分配一个线程来执行这个节点。
setBolt方法返回一个InputDeclarer对象, 这个对象是用来定义Bolt的输入。 这里第一个Bolt声明它要读取spout所发射的所有的tuple — 使用shuffle grouping。而第二个bolt声明它读取第一个bolt所发射的tuple。shuffle grouping表示所有的tuple会被随机的分发给bolt的所有task。给task分发tuple的策略有很多种,后面会介绍。
如果你想第二个bolt读取spout和第一个bolt所发射的所有的tuple, 那么你应该这样定义第二个bolt:
builder.setBolt(3,newExclamationBolt(),5)
.shuffleGrouping(1)
.shuffleGrouping(2);让我们深入地看一下这个topology里面的spout和bolt是怎么实现的。Spout负责发射新的tuple到这个topology里面来。TestWordSpout从["nathan", "mike", "jackson", "golda", "bertels"]里面随机选择一个单词发射出来。TestWordSpout里面的nextTuple()方法是这样定义的:
publicvoidnextTuple() {
Utils.sleep(100);
finalString[] words =newString[] {"nathan","mike",
"jackson","golda","bertels"};
finalRandom rand =newRandom();
finalString word = words[rand.nextInt(words.length)];
_collector.emit(newValues(word));
}可以看到,实现很简单。
ExclamationBolt把”!!!”拼接到输入tuple后面。我们来看下ExclamationBolt的完整实现。
publicstaticclassExclamationBoltimplementsIRichBolt {
OutputCollector _collector;
publicvoidprepare(Map conf, TopologyContext context,
OutputCollector collector) {
_collector = collector;
}
publicvoidexecute(Tuple tuple) {
_collector.emit(tuple,newValues(tuple.getString(0) +"!!!"));
_collector.ack(tuple);
}
publicvoidcleanup() {
}
publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(newFields("word"));
}
}prepare方法提供给bolt一个Outputcollector用来发射tuple。Bolt可以在任何时候发射tuple — 在prepare, execute或者cleanup方法里面, 或者甚至在另一个线程里面异步发射。这里prepare方法只是简单地把OutputCollector作为一个类字段保存下来给后面execute方法使用。
execute方法从bolt的一个输入接收tuple(一个bolt可能有多个输入源). ExclamationBolt获取tuple的第一个字段,加上”!!!”之后再发射出去。如果一个bolt有多个输入源,你可以通过调用Tuple#getSourceComponent方法来知道它是来自哪个输入源的。
execute方法里面还有其它一些事情值得一提: 输入tuple被作为emit方法的第一个参数,并且输入tuple在最后一行被ack。这些呢都是Storm可靠性API的一部分,后面会解释。
cleanup方法在bolt被关闭的时候调用, 它应该清理所有被打开的资源。但是集群不保证这个方法一定会被执行。比如执行task的机器down掉了,那么根本就没有办法来调用那个方法。cleanup设计的时候是被用来在local mode的时候才被调用(也就是说在一个进程里面模拟整个storm集群), 并且你想在关闭一些topology的时候避免资源泄漏。
最后,declareOutputFields定义一个叫做”word”的字段的tuple。
以local mode运行ExclamationTopology
让我们看看怎么以local mode运行ExclamationToplogy。
storm的运行有两种模式: 本地模式和分布式模式. 在本地模式中, storm用一个进程里面的线程来模拟所有的spout和bolt. 本地模式对开发和测试来说比较有用。 你运行storm-starter里面的topology的时候它们就是以本地模式运行的, 你可以看到topology里面的每一个组件在发射什么消息。
在分布式模式下, storm由一堆机器组成。当你提交topology给master的时候, 你同时也把topology的代码提交了。master负责分发你的代码并且负责给你的topolgoy分配工作进程。如果一个工作进程挂掉了, master节点会把认为重新分配到其它节点。关于如何在一个集群上面运行topology, 你可以看看Running topologies on a production cluster文章。
下面是以本地模式运行ExclamationTopology的代码:
Config conf =newConfig();
conf.setDebug(true);
conf.setNumWorkers(2);
LocalCluster cluster =newLocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown();首先, 这个代码定义通过定义一个LocalCluster对象来定义一个进程内的集群。提交topology给这个虚拟的集群和提交topology给分布式集群是一样的。通过调用submitTopology方法来提交topology, 它接受三个参数:要运行的topology的名字,一个配置对象以及要运行的topology本身。
topology的名字是用来唯一区别一个topology的,这样你然后可以用这个名字来杀死这个topology的。前面已经说过了, 你必须显式的杀掉一个topology, 否则它会一直运行。
Conf对象可以配置很多东西, 下面两个是最常见的:
TOPOLOGY_WORKERS(setNumWorkers) 定义你希望集群分配多少个工作进程给你来执行这个topology. topology里面的每个组件会被需要线程来执行。每个组件到底用多少个线程是通过setBolt和setSpout来指定的。这些线程都运行在工作进程里面. 每一个工作进程包含一些节点的一些工作线程。比如, 如果你指定300个线程,60个进程, 那么每个工作进程里面要执行6个线程, 而这6个线程可能属于不同的组件(Spout, Bolt)。你可以通过调整每个组件的并行度以及这些线程所在的进程数量来调整topology的性能。
TOPOLOGY_DEBUG(setDebug), 当它被设置成true的话, storm会记录下每个组件所发射的每条消息。这在本地环境调试topology很有用, 但是在线上这么做的话会影响性能的。
感兴趣的话可以去看看Conf对象的Javadoc去看看topology的所有配置。
可以看看创建一个新storm项目去看看怎么配置开发环境以使你能够以本地模式运行topology.
运行中的Topology主要由以下三个组件组成的:
Worker processes(进程)
Executors (threads)(线程)
Tasks
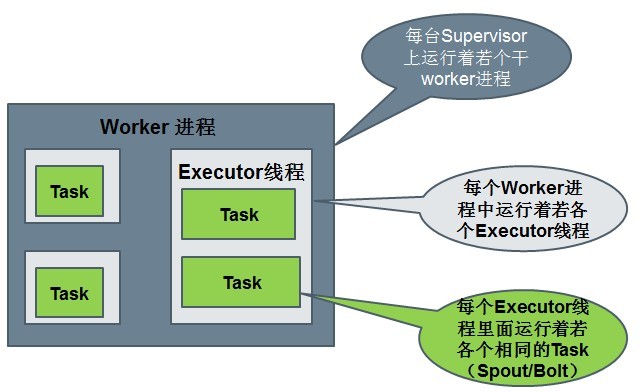
Spout或者Bolt的Task个数一旦指定之后就不能改变了,而Executor的数量可以根据情况来进行动态的调整。默认情况下# executor = #tasks即一个Executor中运行着一个Task
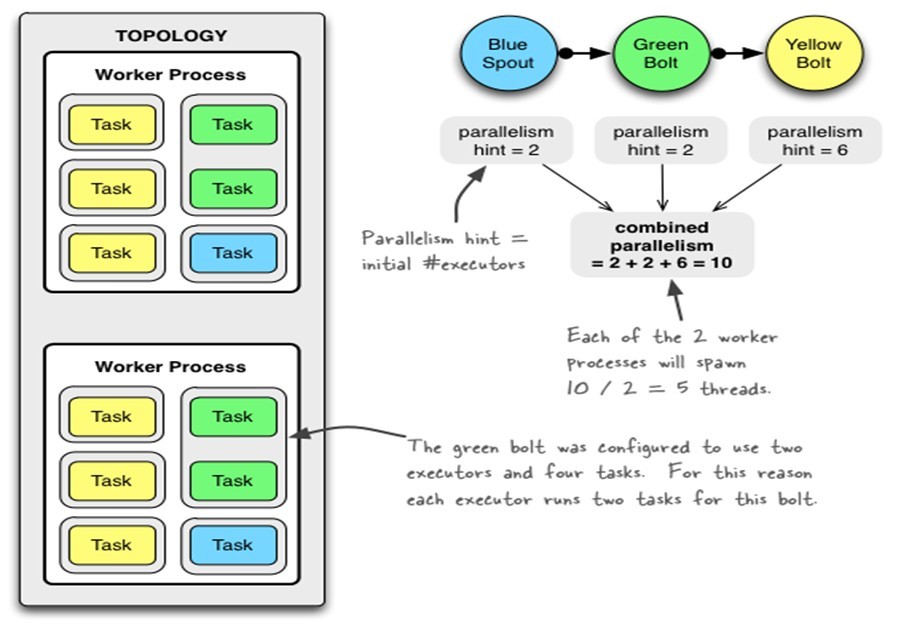
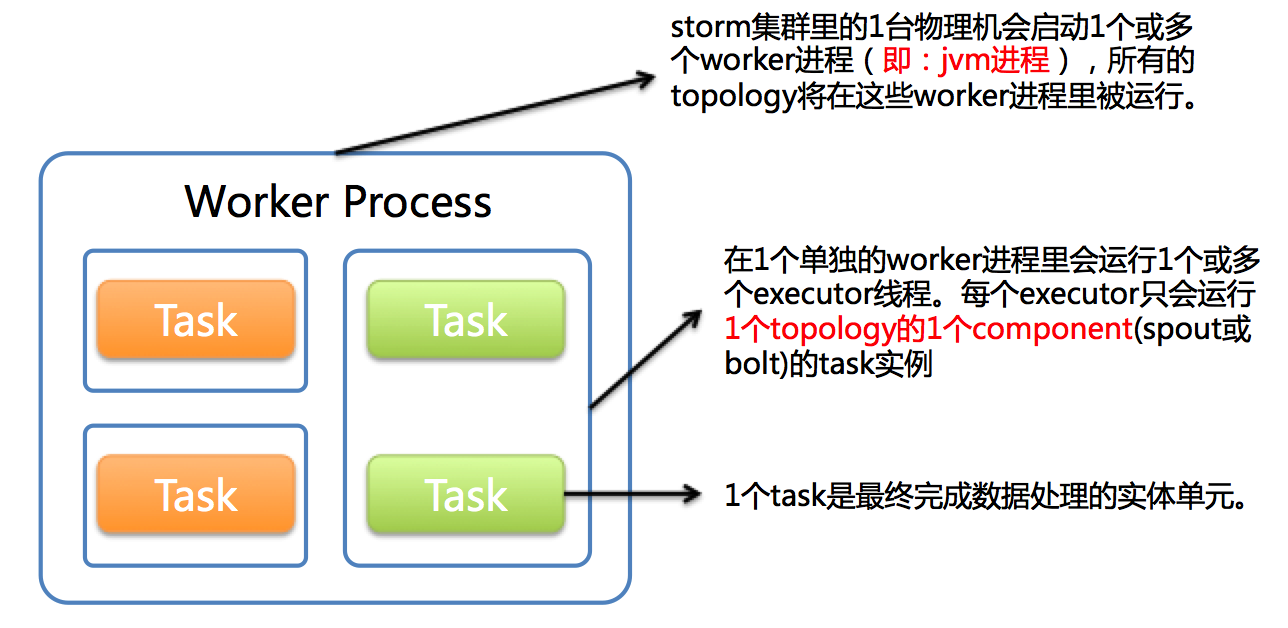
1个worker进程执行的是1个topology的子集(注:不会出现1个worker为多个topology服务)。1个worker进程会启动1个或多个executor线程来执行1个topology的component(spout或bolt)。因此,1个运行中的topology就是由集群中多台物理机上的多个worker进程组成的。
executor是1个被worker进程启动的单独线程。每个executor只会运行1个topology的1个component(spout或bolt)的task(set)(注:task可以是1个或多个,storm默认是1个component只生成1个task,executor线程里会在每次循环里顺序调用所有task实例)。
task是最终运行spout或bolt中代码的单元(注:1个task即为spout或bolt的1个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)。topology启动后,1个component(spout或bolt)的task数目是固定不变的,但该component使用的executor线程数可以动态调整(例如:1个executor线程可以执行该component的1个或多个task实例)。这意味着,对于1个component存在这样的条件:#threads<=#tasks(即:线程数小于等于task数目)。默认情况下task的数目等于executor线程数目,即1个executor线程只运行1个task。
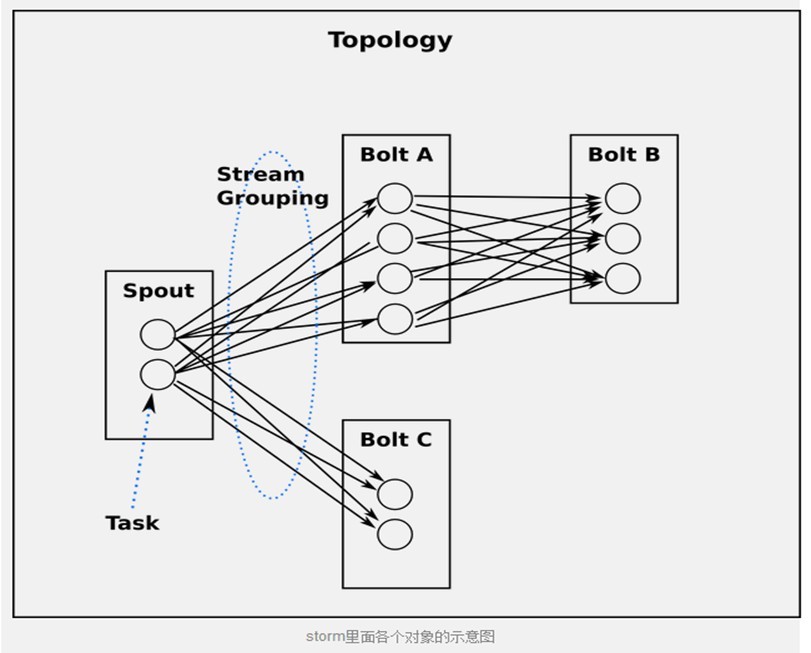
从task角度来看topology
当Bolt A的一个task要发送一个tuple给Bolt B, 它应该发送给Bolt B的哪个task呢?
stream grouping专门回答这种问题的。在我们深入研究不同的stream grouping之前, 让我们看一下storm-starter里面的另外一个topology。WordCountTopology读取一些句子, 输出句子里面每个单词出现的次数.
TopologyBuilder builder =newTopologyBuilder();
builder.setSpout(1,newRandomSentenceSpout(),5);
builder.setBolt(2,newSplitSentence(),8)
.shuffleGrouping(1);
builder.setBolt(3,newWordCount(),12)
.fieldsGrouping(2,newFields("word"));SplitSentence对于句子里面的每个单词发射一个新的tuple, WordCount在内存里面维护一个单词->次数的mapping, WordCount每收到一个单词, 它就更新内存里面的统计状态。
有好几种不同的stream grouping:
最简单的grouping是shuffle grouping, 它随机发给任何一个task。上面例子里面RandomSentenceSpout和SplitSentence之间用的就是shuffle grouping, shuffle grouping对各个task的tuple分配的比较均匀。
一种更有趣的grouping是fields grouping, SplitSentence和WordCount之间使用的就是fields grouping, 这种grouping机制保证相同field值的tuple会去同一个task, 这对于WordCount来说非常关键,如果同一个单词不去同一个task, 那么统计出来的单词次数就不对了。
fields grouping是stream合并,stream聚合以及很多其它场景的基础。在背后呢, fields grouping使用的一致性哈希来分配tuple的。
还有一些其它类型的stream grouping. 你可以在Concepts一章里更详细的了解。
下面是一些常用的 “路由选择” 机制:
Storm的Grouping即消息的Partition机制。当一个Tuple被发送时,如何确定将它发送个某个(些)Task来处理??
l ShuffleGrouping:随机选择一个Task来发送。
l FiledGrouping:根据Tuple中Fields来做一致性hash,相同hash值的Tuple被发送到相同的Task。
l AllGrouping:广播发送,将每一个Tuple发送到所有的Task。
l GlobalGrouping:所有的Tuple会被发送到某个Bolt中的id最小的那个Task。
l NoneGrouping:不关心Tuple发送给哪个Task来处理,等价于ShuffleGrouping。
l DirectGrouping:直接将Tuple发送到指定的Task来处理。
Bolt可以使用任何语言来定义。用其它语言定义的bolt会被当作子进程(subprocess)来执行, storm使用JSON消息通过stdin/stdout来和这些subprocess通信。这个通信协议是一个只有100行的库, storm团队给这些库开发了对应的Ruby, Python和Fancy版本。
下面是WordCountTopology里面的SplitSentence的定义:
publicstaticclassSplitSentenceextendsShellBoltimplementsIRichBolt {
publicSplitSentence() {
super("python","splitsentence.py");
}
publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(newFields("word"));
}
}SplitSentence继承自ShellBolt并且声明这个Bolt用python来运行,并且参数是: splitsentence.py。下面是splitsentence.py的定义:
importstorm
classSplitSentenceBolt(storm.BasicBolt):
defprocess(self, tup):
words=tup.values[0].split(" ")
forwordinwords:
storm.emit([word])
SplitSentenceBolt().run()更多有关用其它语言定义Spout和Bolt的信息, 以及用其它语言来创建topology的 信息可以参见: Using non-JVM languages with Storm.
在这个教程的前面,我们跳过了有关tuple的一些特征。这些特征就是storm的可靠性API: storm如何保证spout发出的每一个tuple都被完整处理。看看《storm如何保证消息不丢失》以更深入了解storm的可靠性API.
Storm允许用户在Spout中发射一个新的源Tuple时为其指定一个MessageId,这个MessageId可以是任意的Object对象。多个源Tuple可以共用同一个MessageId,表示这多个源Tuple对用户来说是同一个消息单元。Storm的可靠性是指Storm会告知用户每一个消息单元是否在一个指定的时间内被完全处理。完全处理的意思是该MessageId绑定的源Tuple以及由该源Tuple衍生的所有Tuple都经过了Topology中每一个应该到达的Bolt的处理。
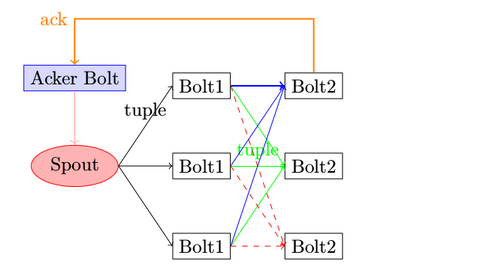
ack机制即, spout发送的每一条消息,
在规定的时间内,spout收到Acker的ack响应,即认为该tuple 被后续bolt成功处理
在规定的时间内,没有收到Acker的ack响应tuple,就触发fail动作,即认为该tuple处理失败,
或者收到Acker发送的fail响应tuple,也认为失败,触发fail动作
另外Ack机制还常用于限流作用: 为了避免spout发送数据太快,而bolt处理太慢,常常设置pending数,当spout有等于或超过pending数的tuple没有收到ack或fail响应时,跳过执行nextTuple, 从而限制spout发送数据。
通过conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, pending);设置spout pend数。
在Spout中由message 1绑定的tuple1和tuple2分别经过bolt1和bolt2的处理,然后生成了两个新的Tuple,并最终流向了bolt3。当bolt3处理完之后,称message 1被完全处理了。
Storm中的每一个Topology中都包含有一个Acker组件。Acker组件的任务就是跟踪从Spout中流出的每一个messageId所绑定的Tuple树中的所有Tuple的处理情况。如果在用户设置的最大超时时间内这些Tuple没有被完全处理,那么Acker会告诉Spout该消息处理失败,相反则会告知Spout该消息处理成功。
那么Acker是如何记录Tuple的处理结果呢??
A xor A = 0.
A xor B…xor B xor A = 0,其中每一个操作数出现且仅出现两次。
在Spout中,Storm系统会为用户指定的MessageId生成一个对应的64位的整数,作为整个Tuple Tree的RootId。RootId会被传递给Acker以及后续的Bolt来作为该消息单元的唯一标识。同时,无论Spout还是Bolt每次新生成一个Tuple时,都会赋予该Tuple一个唯一的64位整数的Id。
当Spout发射完某个MessageId对应的源Tuple之后,它会告诉Acker自己发射的RootId以及生成的那些源Tuple的Id。而当Bolt处理完一个输入Tuple并产生出新的Tuple时,也会告知Acker自己处理的输入Tuple的Id以及新生成的那些Tuple的Id。Acker只需要对这些Id进行异或运算,就能判断出该RootId对应的消息单元是否成功处理完成了。
spout 在发送数据的时候带上msgid
设置acker数至少大于0;Config.setNumAckers(conf, ackerParal);
在bolt中完成处理tuple时,执行OutputCollector.ack(tuple), 当失败处理时,执行OutputCollector.fail(tuple); ** 推荐使用IBasicBolt, 因为IBasicBolt 自动封装了OutputCollector.ack(tuple), 处理失败时,请抛出FailedException,则自动执行OutputCollector.fail(tuple)
有2种途径
spout发送数据是不带上msgid
设置acker数等于0
环境:centos 6.4
安装步骤请参考:http://blog.sina.com.cn/s/blog_546abd9f0101cce8.html
要注意上面的本地模式运行WordCount其实并没有使用到上述安装的工具,只是一个storm的虚拟环境下测试demo。那我们怎样将程序运行在刚刚搭建的单机版的环境里面呢,
很简单,官方的例子:
注意看官方实例中WordCountTopology类如果不带参数其实是执行的本地模式,也就是刚说的虚拟的环境,带上参数就是将jar发送到了storm执行了。
首先弄好环境:
启动zookeeper:
/usr/local/zookeeper/bin/zkServer.sh 单机版直接启动,不用修改什么配置,如集群就需要修改zoo.cfg另一篇文章会讲到。
配置storm:
文件在/usr/local/storm/conf/storm.yaml
内容:
storm.zookeeper.servers:
- 127.0.0.1
storm.zookeeper.port: 2181
nimbus.host: "127.0.0.1"
storm.local.dir: "/tmp/storm"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
这个脚本文件写的不咋地,所以在配置时一定注意在每一项的开始时要加空格,冒号后也必须要加空格,否则storm就不认识这个配置文件了。
说明一下:storm.local.dir表示storm需要用到的本地目录。nimbus.host表示那一台机器是master机器,即nimbus。storm.zookeeper.servers表示哪几台机器是zookeeper服务器。storm.zookeeper.port表示zookeeper的端口号,这里一定要与zookeeper配置的端口号一致,否则会出现通信错误,切记切记。当然你也可以配superevisor.slot.port,supervisor.slots.ports表示supervisor节点的槽数,就是最多能跑几个worker进程(每个sprout或bolt默认只启动一个worker,但是可以通过conf修改成多个)。
执行:
# bin/storm nimbus(启动主节点)
# bin/storm supervisor(启动从节点)
执行命令:# storm jar StormStarter.jar storm.starter.WordCountTopology test
此命令的作用就是用storm将jar发送给storm去执行,后面的test是定义的toplogy名称。
搞定,任务就发送到storm上运行起来了,还可以通过命令:
# bin/storm ui
然后执行 jps 会看到 3 个进程:zookeeper 、nimbus、 supervisor
启动ui,可以通过浏览器, ip:8080/ 查看运行i情况。
配置后,执行 storm jar sm.jar main.java.TopologyMain words.txt
也许会报:java.lang.NoClassDefFoundError: clojure.core.protocols$seq_reduce
这是由于我使用了 oracle JDK 1.7 的缘故,换成 open JDK 1.6 就正常了,
su -c "yum install java-1.6.0-openjdk-devel"具体参考:https://github.com/technomancy/leiningen/issues/676
测试代码:
https://github.com/storm-book/examples-ch02-getting_started
运行结果:
storm jar sm.jar main.java.TopologyMain words.txt
...
6020 [main] INFO backtype.storm.messaging.loader - Shutdown receiving-thread: [Getting-Started-Toplogie-1-1374946750, 4]
6020 [main] INFO backtype.storm.daemon.worker - Shut down receive thread
6020 [main] INFO backtype.storm.daemon.worker - Terminating zmq context
6020 [main] INFO backtype.storm.daemon.worker - Shutting down executors
OK:is
6021 [main] INFO backtype.storm.daemon.executor - Shutting down executor word-counter:[2 2]
OK:an
OK:storm
OK:simple
6023 [Thread-16] INFO backtype.storm.util - Async loop interrupted!
OK:application
OK:but
OK:very
OK:powerfull
OK:really
OK:
OK:StOrm
OK:is
OK:great
6038 [Thread-15] INFO backtype.storm.util - Async loop interrupted!
-- Word Counter [word-counter-2] --
really: 1
but: 1
application: 1
is: 2
great: 2
are: 1
test: 1
simple: 1
an: 1
powerfull: 1
storm: 3
very: 1
6043 [main] INFO backtype.storm.daemon.executor - Shut down executor word-counter:[2 2]
6044 [main] INFO backtype.storm.daemon.executor - Shutting down executor word-normalizer:[3 3]
6045 [Thread-18] INFO backtype.storm.util - Async loop interrupted!
6052 [Thread-17] INFO backtype.storm.util - Async loop interrupted!
6056 [main] INFO backtype.storm.daemon.executor - Shut down executor word-normalizer:[3 3]
6056 [main] INFO backtype.storm.daemon.executor - Shutting down executor word-reader:[4 4]
6058 [Thread-19] INFO backtype.storm.util - Async loop interrupted!
...以上是“storm如何实现单机版安装”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/leejun2005/blog/147607



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



