这篇文章主要介绍“jvm file.encoding属性引起的HBase乱码问题怎么解决”,在日常操作中,相信很多人在jvm file.encoding属性引起的HBase乱码问题怎么解决问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”jvm file.encoding属性引起的HBase乱码问题怎么解决”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
最近在往 HBase 写中文的时候,发现 hbase 查出来的数据会有部分中文乱码了,而部分中文又是正常的,按理来说,一般的乱码问题要么全乱,要么不乱。考虑到出现中文的地方都是来源于 hdfs 上的一个配置文件,而这个配置文件可以确定是 utf-8 编码的,那排除了原始文件导致的乱码,想想 MR 代码里也没有转码的逻辑,也排除了代码的问题,那就只有一种可能:Hadoop 集群的系统环境是异构的,这里面可能涉及到 linux 、java 的环境变量、配置的问题。
(1)打印了整个集群的 echo $LANG、echo $LC_ALL 等linux系统变量,发现都是一致的,排除了 os 环境的问题。
(2)剩下的重点放在了 java 环境上,在代码里加上如下两句,打印每条记录的 ip 和 jvm 编码,然后看看乱码的记录是那台机器产生的,并且当时 jvm child 的编码情况:
java.net.InetAddress test = java.net.InetAddress.getByName("localhost");
put.add(Bytes.toBytes("cf"), Bytes.toBytes("ip"), Bytes.toBytes(test.getLocalHost().getHostAddress()));
put.add(Bytes.toBytes("cf"), Bytes.toBytes("ec"), Bytes.toBytes(System.getProperty("file.encoding")));同时也直接 System.out.println 出相应的中文字段,看是写进 hbase 之前还是之后乱掉的。
跑了一份测试数据后,发现 hbase 里的 ip、jvm 编码是没有规律的,然后查看 syso 打印的 log 发现,在写 hbase 之前已经就已经乱码了,然后想想 hbase 里的数据乱码之所以没有规律是因为 map 后要 shuffle、reduce 才能到 hbase。PS:sysout本身无编码概念,类似 linux 下的 cat、head、more 等。
然后再次把 ip、jvm编码 统计代码放到 map 阶段输出,果真发现了规律,集群中有两台机器的 jvm 编码不一致,不是 utf-8 的:
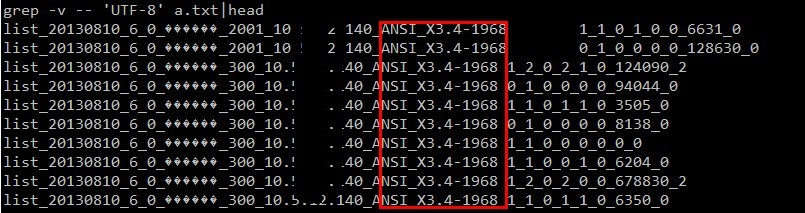
到这里我们可以知道原因了:由于集群中两台机器的 jvm 参数(file.encoding)不一致导致了部分中文结果的乱码。
知道原因了,那就看如何解决了,目的就是要改变 file.encoding 的值 。
由于这个参数是 jvm 的启动参数,运行时不可被更改(你可以理解为这个参数是个全局参数,而且被缓存了,如果一旦运行时更改了, 可能会造成整个 jvm 里面的程序奔溃),你只能修改系统的charset, 或者jvm的启动参数里加上 -Dfile.encoding="UTF-8">,你运行时 setProperty("file.encoding","ISO-8859-1"); 这样是没用的,so,永久的解决办法是:啥时候把这两台机器offline 改编码后再online,然后再手动执行下 data balance。
或者可以在提交作业的时候设置作业参数: –Dmapred.child.env="LANG=en_US.UTF-8,LC_ALL=en_US.UTF-8"
不想这么大动干戈,想要临时解决方案,也行,那就需要在咱们自己的业务代码里绕开 jvm 提供的默认 file.encoding 编码,自己指定编码:
BufferedReader in = new BufferedReader(new FileReader(path.toString()));
换成:
BufferedReader in = new BufferedReader((new InputStreamReader(new FileInputStream(path.toString()),"utf-8")));上面一句是我之前乱码的代码,如果你没有指定读取编码,那么 jvm 会使用自己的 file.encoding,这样就会造成在某些机器上读取文件就乱掉了。下面一句是自己指定编码,这样绕开了 jvm 的默认编码,与 jvm 从此形同陌路~
PS:FileReader 貌似没有提供指定编码的构造方法,所以换成了下面的类。
为什么之前一直都没乱码,而这次读文件却乱码了呢?
那是因为 hbase 的 Bytes、map 的 fileinputformat key/value、mapreduce 的 context.write 默认都是自己硬编码了 utf-8,做到了 和 jvm 编码无关,所以不会遇到上述问题。
上面说了这么多,可能有同学还是不大明白:jvm 的这参数有毛用啊?为毛之前都没听过这玩意呢?
恩,没听过正常,之前我也没听过哈~
在JDK 1.6.0_20的src.zip文件中,查找包含file.encoding字眼的文件.
共找到4个, 分别是:
(a)先上重头戏 java.nio.Charset类:
public static Charset defaultCharset() {
if (defaultCharset == null) {
synchronized (Charset.class) {
java.security.PrivilegedAction pa = new GetPropertyAction("file.encoding");
String csn = (String) AccessController.doPrivileged(pa);
Charset cs = lookup(csn);
if (cs != null)
defaultCharset = cs;
else
defaultCharset = forName("UTF-8");
}
}
return defaultCharset;
}在java中,如果没有指定charset的时候,比如new String(byte[] bytes), 都会调用Charset.defaultCharset()的方法,我们可以清楚的看到defaultCharset是只能被初始化一次,这里还是有点小问题的,在多线程并发调用的时候还是会初始话多次,当然后面都是从cache(lookup的函数)里读出来的,问题也不大。
当我们在改变System.getProperties里的file.encoding 的时候,defaultCharset已经被初始化过了,所以不会在调用初始化的代码。
当jvm 启动的时候,load class, 最后调用main函数之前,defaultCharset已经初始化好,而很多函数里都掉用了这个方法象String.getBytes, 还有 InputStreamReader, InputStreamWriter 都是调用了 Charset.defaultCharset()的方法。
(b)java.net.URLEncoder的静态构造方法, 影响到的方法 java.net.URLEncoder.encode(String)
恩,这里也需要注意,之前已经有同学掉坑里去了,请使用:encode(String s, String enc) 方法,此法无侧漏,一觉睡到大天亮~
(c)com.sun.org.apache.xml.internal.serializer.Encoding的getMimeEncoding方法(209行起)
(d)最后一个javax.print.DocFlavor类的静态构造方法
可以看到,系统变量file.encoding影响到
1. Charset.defaultCharset() Java环境中最关键的编码设置
2. URLEncoder.encode(String) Web环境中最常遇到的编码使用
3. com.sun.org.apache.xml.internal.serializer.Encoding 影响对无编码设置的xml文件的读取
4. javax.print.DocFlavor 影响打印的编码
到此,关于“jvm file.encoding属性引起的HBase乱码问题怎么解决”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/leejun2005/blog/157338



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



