ELKStacks是一个技术栈的组合,分别是Elasticsearch、Logstash、Kibana
ELK Stack:
1、扩展性:采用高扩展性分布式架构设计,可支持每日TB级数据
2、简单易用:通过图形页面可对日志数据各种统计,可视化
3、查询效率高:能做到秒级数据采集、处理和搜索
https://www.elastic.co/cn/products/elasticsearch
https://www.elastic.co/cn/products/kibana
https://www.elastic.co/cn/products/beats/filebeat
https://www.elastic.co/cn/products/beats/metricbeat
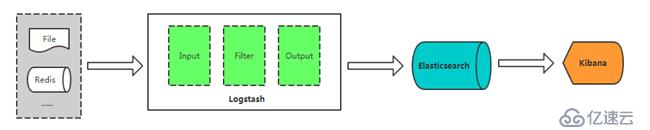
Logstash :开源的服务器端数据处理管道,能够同时从多个来源采集数据、转换数据,然后将数据存储到数据库中。
Elasticsearch:搜索、分析和存储数据。
Kibana:数据可视化。
Beats :轻量型采集器的平台,从边缘机器向 Logstash 和 Elasticsearch 发送数据。
Filebeat:轻量型日志采集器。
https://www.elastic.co/cn/
https://www.elastic.co/subscriptions
Input:输入,输出数据可以是Stdin、File、TCP、Redis、Syslog等。
Filter:过滤,将日志格式化。有丰富的过滤插件:Grok正则捕获、Date时间处理、Json编解码、Mutate数据修改等。
Output:输出,输出目标可以是Stdout、File、TCP、Redis、ES等。
Node:运行单个ES实例的服务器
Cluster:一个或多个节点构成集群
Index:索引是多个文档的集合
Document:Index里每条记录称为Document,若干文档构建一个Index
Type:一个Index可以定义一种或多种类型,将Document逻辑分组
Field:ES存储的最小单元
Shards:ES将Index分为若干份,每一份就是一个分片
Replicas:Index的一份或多份副本
ES | |
Index | Database |
Type | Table |
Document | Row |
Field | Column |
首先做好系统的初始化配置,安装好jdk
#1) System initialization on each Servers cat >> /etc/security/limits.conf << EOF * hard memlock unlimited * soft memlock unlimited * - nofile 65535 EOF cat > /etc/sysctl.conf << EOF net.ipv6.conf.all.disable_ipv6 = 1 net.ipv6.conf.default.disable_ipv6 = 1 vm.swappiness = 0 vm.max_map_count=262144 vm.dirty_ratio=10 vm.dirty_background_ratio=5 net.ipv4.tcp_fin_timeout = 30 net.ipv4.tcp_keepalive_time = 1200 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_max_syn_backlog = 8192 net.ipv4.tcp_max_tw_buckets = 5000 net.ipv4.ip_local_port_range = 10000 65000 EOF sysctl -p setenforce 0 sed -i 's/^SELINUX=.*$/SELINUX=disabled/' /etc/selinux/config systemctl stop firewalld.service systemctl disable firewalld.service #2) Install JDK on each Servers wget -c http://download.cashalo.com/schema/auto_jdk.sh source auto_jdk.sh
接下来执行下面的脚本,我这里是三台服务器组成的ES集群,脚本里已经带了参数,可以交互式的输入实际的服务器IP地址,所以请在每个节点都运行
#!/bin/bash
IP=`ifconfig|sed -n 2p|awk '{print $2}'|cut -d ":" -f2`
if [ `whoami` != root ]
then
echo "Please login as root to continue :)"
exit 1
fi
if [ ! -d /home/tools/ ];then
mkdir -p /home/tools
else
rm -rf /home/tools && mkdir -p /home/tools
fi
yum install perl-Digest-SHA -y && cd /home/tools
#wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.8.1.rpm
#wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.8.1.rpm.sha512
#shasum -a 512 -c elasticsearch-6.8.1.rpm.sha512
#sudo rpm --install elasticsearch-6.8.1.rpm
#3) Download elasticsearch-5.6.10 on each servers
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.10.rpm
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.10.rpm.sha512
shasum -a 512 -c elasticsearch-5.6.10.rpm.sha512
sudo rpm --install elasticsearch-5.6.10.rpm
#4) Modify elasticsearch.yml File
#Note: network.host means your IP address
cat >/etc/elasticsearch/elasticsearch.yml<<EOF
cluster.name: graylog
node.name: localhost
path.data: /data/elasticsearch
path.logs: /var/log/elasticsearch
network.host: $IP
http.port: 9200
discovery.zen.ping.unicast.hosts: ["node1", "node2", "node3"]
discovery.zen.minimum_master_nodes: 2
EOF
read -p "pls input nodename: " Name
sed -i "s/localhost/$Name/g" /etc/elasticsearch/elasticsearch.yml
echo -e "\033[33m your nodename is $Name \033[0m"
read -p "pls input node1 ip address: " ip1
sed -i "s/node1/$ip1/g" /etc/elasticsearch/elasticsearch.yml
echo -e "\033[33m your node1 ip address is $ip1 \033[0m"
echo -e "###############################################"
echo -e "###############################################"
read -p "pls input node2 ip address: " ip2
sed -i "s/node2/$ip2/g" /etc/elasticsearch/elasticsearch.yml
echo -e "\033[33m your node2 ip address is $ip2 \033[0m"
echo -e "###############################################"
echo -e "###############################################"
read -p "pls input node3 ip address: " ip3
sed -i "s/node3/$ip3/g" /etc/elasticsearch/elasticsearch.yml
echo -e "\033[33m your node3 ip address is $ip3 \033[0m"
echo -e "###############################################"
echo -e "###############################################"
#5) Create elasticsearch Directory on each Servers
mkdir -p /data/elasticsearch/
chown -R elasticsearch.elasticsearch /data/elasticsearch/
#6) Start elasticsearch on each Servers
service elasticsearch restart && chkconfig elasticsearch on
#7) Check your elasticsearch Service
curl -X GET "http://127.0.0.1:9200/_cat/health?v"3.3 数据操作
RestFul API格式
curl -X<verb> ‘<protocol>://<host>:<port>/<path>?<query_string>’-d ‘<body>’
参数 | 描述 |
verb | HTTP方法,比如GET、POST、PUT、HEAD、DELETE |
host | ES集群中的任意节点主机名 |
port | ES HTTP服务端口,默认9200 |
path | 索引路径 |
query_string | 可选的查询请求参数。例如?pretty参数将返回JSON格式数据 |
-d | 里面放一个GET的JSON格式请求主体 |
body | 自己写的 JSON格式的请求主体 |
查看索引:
curl http://127.0.0.1:9200/_cat/indices?v
新建索引:
curl -X PUT 127.0.0.1:9200/logs-2018.05.22
删除索引:
curl -X DELETE 127.0.0.1:9200/logs-2018.05.22
ES提供一种可用于执行查询JSON式的语言,被称为Query DSL
使用官方提供的示例数据:
https://www.elastic.co/guide/en/elasticsearch/reference/current/_exploring_your_data.html
wget https://raw.githubusercontent.com/elastic/elasticsearch/master/docs/src/test/resources/accounts.json
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





