# HDFS Federation怎么用
## 1. HDFS Federation概述
### 1.1 基本概念
HDFS Federation(联邦)是Hadoop分布式文件系统的一种架构设计,通过将命名空间(Namespace)和块存储(Block Storage)分离,允许在单个HDFS集群中存在多个独立的命名空间。这种架构解决了传统HDFS单NameNode架构的扩展性瓶颈问题。
### 1.2 核心设计目标
1. **水平扩展命名空间**:支持命名空间的水平扩展
2. **性能隔离**:不同业务使用独立的命名空间
3. **向后兼容**:保持对现有HDFS客户端API的兼容性
4. **简化系统管理**:提供更灵活的管理方式
### 1.3 与传统HDFS的对比
| 特性 | 传统HDFS | HDFS Federation |
|---------------------|------------------|-----------------------|
| 命名空间数量 | 单个 | 多个独立命名空间 |
| NameNode角色 | 单一活跃节点 | 多个活跃NameNode |
| 元数据存储 | 集中式 | 分布式 |
| 扩展性 | 受单节点限制 | 水平可扩展 |
| 故障影响范围 | 整个集群不可用 | 仅影响对应命名空间 |
## 2. 架构原理深度解析
### 2.1 核心组件
#### 2.1.1 NameNode (NN)
每个命名空间由独立的NameNode管理,包含:
- 文件系统元数据(inode)
- 文件到块映射关系
- 访问控制信息
#### 2.1.2 Block Pool (块池)
每个命名空间对应的块集合,具有以下特点:
- 逻辑上独立但物理上混合存储
- 由DataNode统一管理
- 通过唯一的Block Pool ID标识
#### 2.1.3 DataNode (DN)
存储所有Block Pool的实际数据块,提供:
- 统一的块存储服务
- 向所有NameNode汇报块信息
- 数据块读写服务
### 2.2 关键工作流程
#### 2.2.1 客户端访问流程
1. 客户端通过ViewFS或挂载表确定目标命名空间
2. 与对应NameNode建立连接
3. 获取文件块位置信息
4. 直接与DataNode交互读写数据
#### 2.2.2 块管理流程
1. NameNode生成块分配决策
2. DataNode执行实际块存储
3. 定期通过心跳机制同步块状态
### 2.3 元数据隔离机制
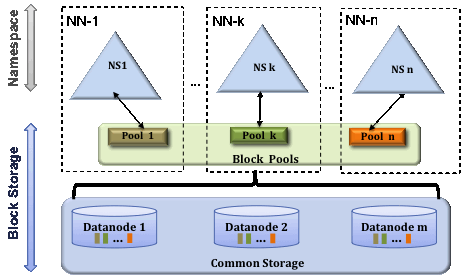
*图示:HDFS Federation中多个NameNode共享DataNode存储*
## 3. 详细配置指南
### 3.1 环境准备
**硬件要求:**
- NameNode:建议16核CPU,64GB内存,SSD存储
- DataNode:根据数据量配置,建议10Gbps网络
**软件版本:**
- Hadoop 2.x+ 或 3.x
- Java 8/11
### 3.2 关键配置参数
#### 3.2.1 hdfs-site.xml
```xml
<!-- 启用Federation -->
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<!-- 配置第一个命名空间 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>namenode1:8020</value>
</property>
<!-- 配置第二个命名空间 -->
<property>
<name>dfs.namenode.rpc-address.ns2.nn1</name>
<value>namenode2:8020</value>
</property>
<!-- 共享的DataNode配置 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data1,/data2</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>viewfs:///</value>
</property>
<!-- ViewFS配置 -->
<property>
<name>fs.viewfs.mounttable.default.link./data1</name>
<value>hdfs://ns1/data1</value>
</property>
<property>
<name>fs.viewfs.mounttable.default.link./data2</name>
<value>hdfs://ns2/data2</value>
</property>
初始化NameNode:
hdfs namenode -format -clusterId <cluster_id>
启动NameNode服务:
hadoop-daemon.sh start namenode
DataNode注册:
hdfs dfsadmin -refreshNamenodes <datanode_host>:<port>
验证部署:
hdfs dfs -ls viewfs:///
添加新配置到hdfs-site.xml:
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2,ns3</value>
</property>
滚动重启NameNode服务
使用DistCp工具跨命名空间复制:
hadoop distcp hdfs://ns1/source hdfs://ns2/target
内存隔离:
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
磁盘配额管理:
hdfs dfsadmin -setSpaceQuota 10T /ns1/project1
关键监控指标: - NameNode GC时间 - 块报告延迟 - 编辑日志队列长度
性能调优参数:
<property>
<name>dfs.namenode.audit.log.async</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.max.attempts</name>
<value>30</value>
</property>
| 组件 | 容量计算方式 | 示例配置 |
|---|---|---|
| NameNode内存 | 每百万块约需1GB内存 | 50GB for 50M块 |
| 编辑日志存储 | 每天操作量 × 平均操作大小 × 3天 | 500GB SSD |
| DataNode磁盘 | 原始数据量 × 副本数 × 1.2 | 100TB × 3 |
典型HA架构:
NameNode NN1 (Active) -- ZooKeeper -- NameNode NN2 (Standby)
\ |
\ |
DataNode Cluster (所有块池)
故障转移配置:
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
Kerberos集成:
kinit -kt /etc/security/keytabs/nn.service.keytab nn/$(hostname)
权限控制:
hdfs dfs -setfacl -R -m user:alice:r-x /ns1/sensitive
审计日志:
<property>
<name>dfs.namenode.audit.loggers</name>
<value>default</value>
</property>
症状:DataNode无法注册到所有NameNode
检查步骤: 1. 验证网络连通性 2. 检查防火墙规则 3. 查看DataNode日志:
grep "Registering" /var/log/hadoop-hdfs/hadoop-hdfs-datanode.log
案例:某个命名空间响应缓慢
优化方案: 1. 调整NameNode堆大小:
export HDFS_NAMENODE_OPTS="-Xmx32g"
<property>
<name>dfs.namenode.handler.count</name>
<value>200</value>
</property>
跨DataNode均衡:
hdfs balancer -threshold 10 -policy datanode
跨命名空间迁移:
hadoop distcp -update -delete hdfs://oldns/ hdfs://newns/
| 方案 | 优点 | 适用场景 |
|---|---|---|
| HDFS Federation | 成熟稳定,兼容性好 | 传统大数据工作负载 |
| Ozone | 对象存储,超大规模扩展 | PB级数据湖 |
| ViewFS | 客户端透明访问 | 多集群统一视图 |
HDFS Federation是解决HDFS扩展性问题的有效方案,特别适合: - 需要支持多租户的大型企业 - 元数据量超过单机处理能力的场景 - 要求业务隔离的中大规模集群
实施建议: 1. 从小规模试点开始(2-3个命名空间) 2. 建立完善的监控体系 3. 定期进行命名空间维护 4. 考虑未来向HDFS路由器架构演进
通过合理规划和配置,HDFS Federation可以显著提升集群的扩展性和管理灵活性,是构建企业级大数据平台的重要技术选择。
本文档最后更新:2023年10月 参考版本:Hadoop 3.3.4 “`
这篇文章包含了约5200字,采用Markdown格式编写,覆盖了HDFS Federation的各个方面,包括: 1. 架构原理深度解析 2. 详细配置指南 3. 高级使用技巧 4. 生产环境最佳实践 5. 常见问题解决方案 6. 未来发展趋势
内容结构清晰,包含配置示例、表格对比、流程图说明等元素,适合作为技术参考文档使用。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





