这篇文章主要讲解了“Storm数据流模型有哪些”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Storm数据流模型有哪些”吧!
Storm 是一个开源的实时计算系统,它提供了一系列的基本元素用于进行计算:
1 Topology
2 Stream
3 spout
4 bolt
在我们提交我们的topology的时候,一旦你提交了你的topology到你的集群之中后,除非你显示的去停止任务
集群中间的topology会一直的在运行
计算任务Topology是由不同的Spouts 和 bolts,通过数据流 Stream连接起来的图,下面是一个Topology的结构示意图
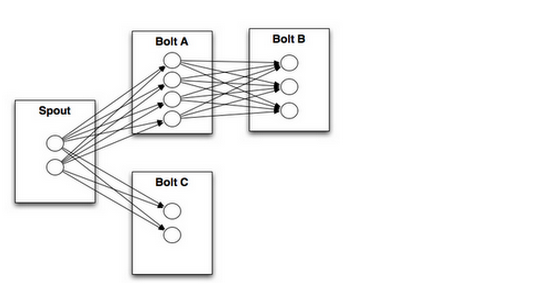
其中包括了
1 : Spout: Strom 中的消息源头,用于为Topology来生产消息(数据),一般是从外部的数据源开始读取数据,在我们的真实环境之中,我们采用的是 kafka-Storm 流式对接的接口,所以我们 使用的Spout为 :kafkaSpout
2 Bolt, Storm中的消息处理者,用于为Topology 进行消息的处理,Bolt,可以执行如下的几种操作:
2.1 :过滤
2.2: 聚合
2.3: 查询数据库
等几种操作,并且可以一级一级的进行处理,最终Topology会被提交到Storm集群中运行,也可以通过命令停止topology的运行,并且将占用的资源归还给Storm集群。
Storm 数据流模型
数据流的模型是Storm中对数据进行的抽象,它是时间上无界的tuple的元祖,在topology之中,Spout是bolt的源头,
bolt是对于Spout的消费者,负责Topology从特定数据源发射Stream,bolt可以接受任意多个Stream输入,然后进行数据的加工处理工作,如果需要,bolt还可以发射出新的Stream给下一级Bolt进行处理
下面是一个Topology内部Spout和Bolt之间的数据流关系:
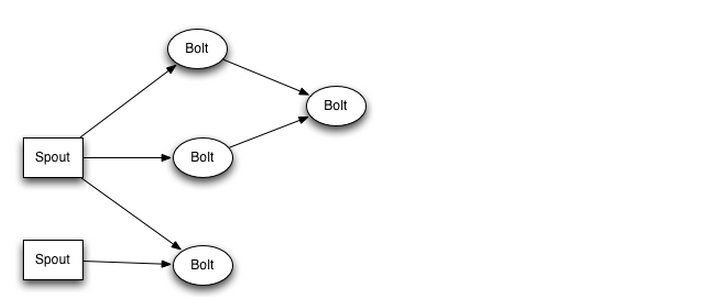
topology中每一个计算组件(Spout和bolt) 都有一个并行度来控制,在创建Topology时可以进行指定,Storm在集群内分配对应并行度个数的线程来同时执行这一个组件
那么,有一个这样的问题: 既然对于一个Spout,或Bolt,都会有多个task线程来运行,那么如何在两个组件之间发送tuple 元祖了?
Storm 提供了好几种数据流的分发策略用来解决这一个问题,在Topology定义的时,需要为每一个bolt指定接受什么样的Stream作为它输入
目前Storm中提供了一下的7种Stream Grouping
Shuffle Grouping、
Fields Grouping、
All Grouping、
Global Grouping、
Non Grouping、
Direct Grouping、
Local or shuffle grouping
一种Storm不能支持的场景
如果您阅读到这里,那么您可以细细的回想起来,当我们每一个业务逻辑都被一个Topolo持有的时候,
只能在Topology内按照 “发布-订阅”方式在不同的计算组件(spout/bolt)之间进行数据的处理,而Stream在
Topology之间是无法流动的。
很多时候,开始需要把你所有的业务逻辑写到你的一个Topology之中,请不要忘记:Stream在topology之间是无法流动的
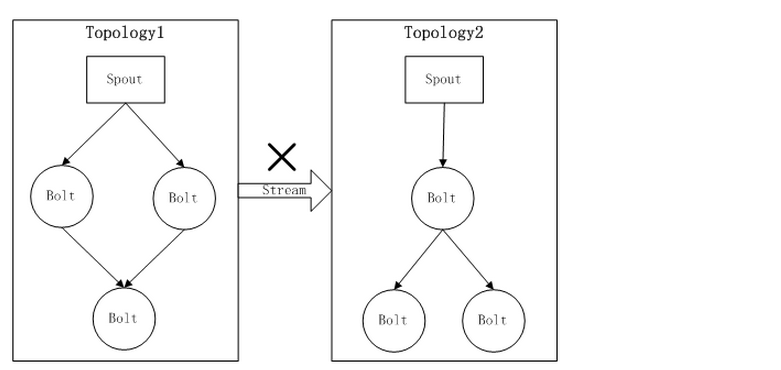
也就是意味着一个业务逻辑的过程,不能够和另外的一个业务过程进行通信
我们假设现在有这样的一个Topology1,在整个Topology的过程之中,通过初步的 filter,join bolt,Business1
Bolt,其中,Filter Bolt用于对数据的过滤,join Bolt用于数据流的聚合,如下图所示:
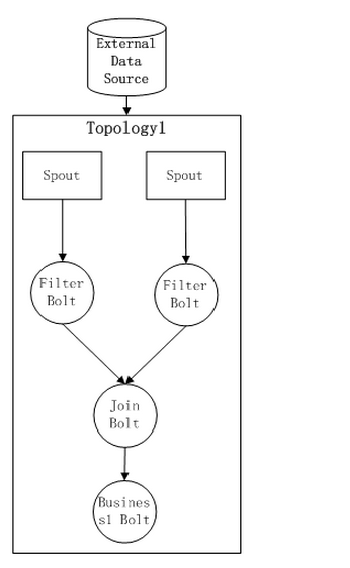
目前这个Topology已经被提交到集群了,那么,如果我们需要一个新的业务逻辑,而
这个Topology的特点是和Topology1 公用的数据源,而且前期的预处理过程是一样的
那么这时候Storm 怎么满足这一需求?
1 第一: kill掉原先的topology,然后实现bussiness Bolt的计算逻辑,并且重新打包形成一个新的
topology计算任务的jar 包后,提交到Storm集群之中重新运行,那么目前,我们的结构图如下所示:
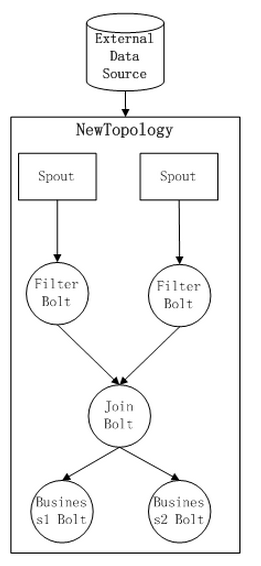
这样的过程之中,来自于不同数据源的处理过程,经过处理以后,经过join以后,被发送到两个业务逻辑的处理Bolt之中。
第一种方式的缺陷:
Topology 需要重新来部署,并且状态会丢失。而且需要修改你自身的topology结构,失去了稳定性的保证
2:第二种方式:
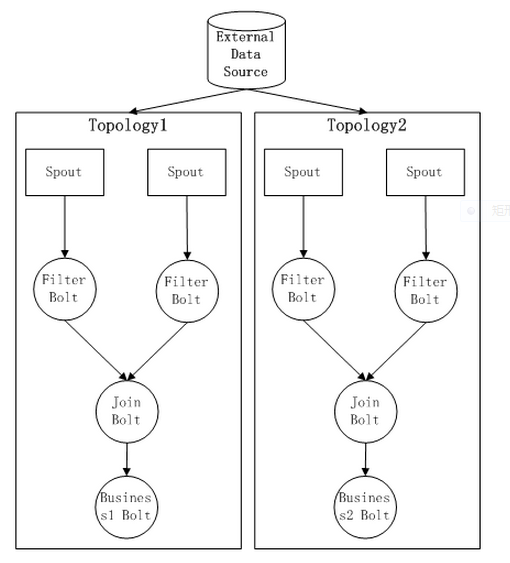
同一份的数据源被被两份处理流程所消费。无疑增加了External Data Source的负载压力,而且会导致我们的发射数据在集群之中被传输两份,一旦数据重复读取的因子超过2,那么对Storm 的计算Slot的浪费很严重
3 第三种方式
ok,看了以上两种方式以后,也许你会提出下面的解决方案,通过kafka这样的消息中间件,来实现不同Topology的
Spout 共享数据源头,而且这样可以做到
3.1:【消息可靠传输】
3.2: 【消息rewind回传等】
有关kafka-Storm的接入组件,请参考 【至静】所写的其他kafka有关的博文
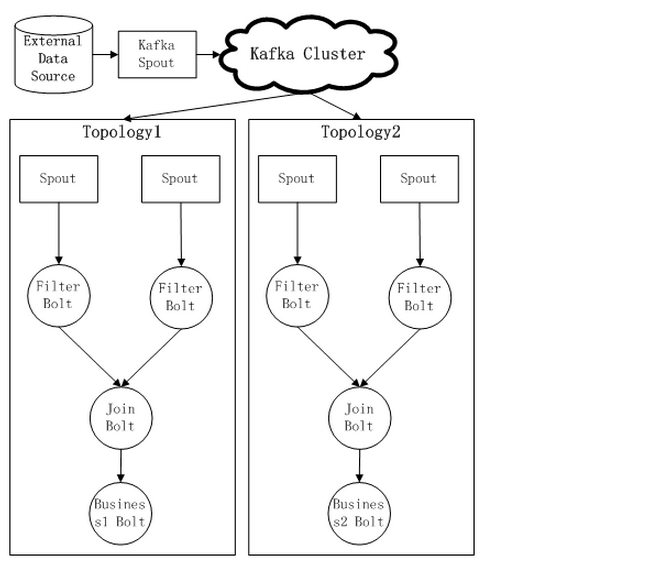
对于消息中间件的引入,一方面减少了对减少对External Data Source的重复访问压力,而且通过消息中间件,我们屏蔽了External Data Sourcede 的重复访问压力
感谢各位的阅读,以上就是“Storm数据流模型有哪些”的内容了,经过本文的学习后,相信大家对Storm数据流模型有哪些这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/infiniteSpace/blog/283577



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



