这篇文章主要讲解了“Hadoop中的MultipleOutput实例使用”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Hadoop中的MultipleOutput实例使用”吧!
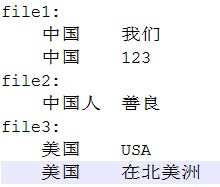
原数据:

预想处理后的结果:
MyMapper.java
package com.xr.text;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String[] split = value.toString().split(";");
context.write(new Text(split[0]), new Text(split[1]));
}
}MyReducer.java
package com.xr.text;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
public class MyReducer extends Reducer<Text, Text, Text, Text> {
private MultipleOutputs mos;
/**
* start before set MultipleOutputs;
*/
protected void setup(Context context) throws IOException,
InterruptedException {
mos = new MultipleOutputs(context);
}
protected void reduce(Text k1, Iterable<Text> value,Context context)
throws IOException, InterruptedException {
String key = k1.toString();
for(Text t : value){
if("中国".equals(key)){
mos.write("china",new Text("中国"), t);
}else if("美国".equals(key)){
mos.write("usa",new Text("美国"),t);
}else if("中国人".equals(key)){
mos.write("cpeople",new Text("中国人"),t);
}
}
}
/**
* close MultipleOutputs;
*/
protected void cleanup(Context context)
throws IOException, InterruptedException {
mos.close();
}
}JobTest.java
package com.xr.text;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class JobTest {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
String inputPath = "hdfs://192.168.75.100:9000/1.txt";
String outputPath = "hdfs://192.168.75.100:9000/ceshi";
Job job = new Job();
job.setJarByClass(JobTest.class);
job.setMapperClass(MyMapper.class);
/**
* set MultipleOutput file name
*/
MultipleOutputs.addNamedOutput(job, "china", TextOutputFormat.class, Text.class, Text.class);
MultipleOutputs.addNamedOutput(job, "usa", TextOutputFormat.class, Text.class, Text.class);
MultipleOutputs.addNamedOutput(job, "cpeople", TextOutputFormat.class, Text.class, Text.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path(inputPath));
// Configuration conf = new Configuration();
// FileSystem fs = FileSystem.get(conf);
//
// if(fs.exists(new Path(outputPath))){
// fs.delete(new Path(outputPath), true);
// }
FileOutputFormat.setOutputPath(job, new Path(outputPath));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}运行过程中报错:
14/08/12 12:44:02 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
14/08/12 12:44:02 ERROR security.UserGroupInformation: PriviledgedActionException as:Xr cause:java.io.IOException: Failed to set permissions of path: \tmp\hadoop-Xr\mapred\staging\Xr-1514460710\.staging to 0700
Exception in thread "main">java.io.IOException: Failed to set permissions of path: \tmp\hadoop-Xr\mapred\staging\Xr-1514460710\.staging to 0700
at org.apache.hadoop.fs.FileUtil.checkReturnValue(FileUtil.java:689)
at org.apache.hadoop.fs.FileUtil.setPermission(FileUtil.java:662)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:509)
at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:344)
at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:189)
at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:116)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:918)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:912)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:396)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1149)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:912)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:500)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:530)
at com.xr.text.JobTest.main(JobTest.java:37)
错误解决方案:
1. 把hadoop-core-1.1.2.jar中的FileUtil.class删除.
2. 再把/org/apache/hadoop/fs/FileUtil.java从源码中copy出来
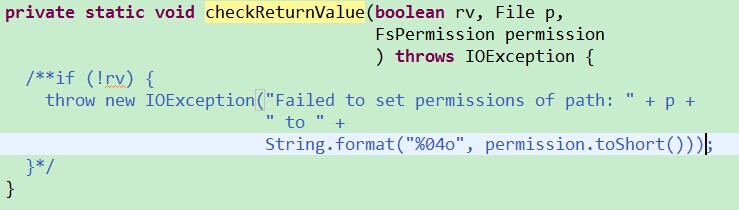
3. 注释checkReturnValue()方法
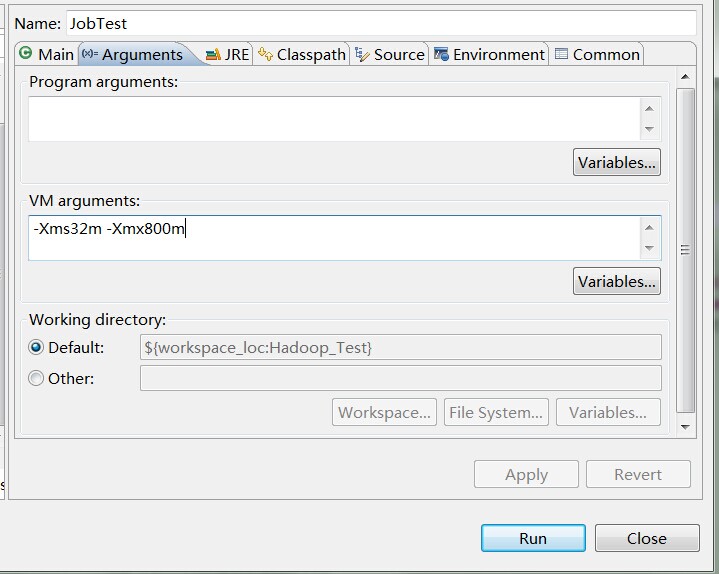
运行时再次报错:
java.lang.OutOfMemoryError: Java heap space
解决方案:
ok,job顺利执行。
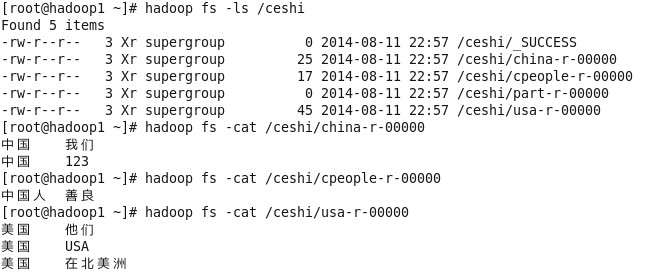
生成以下文件:
感谢各位的阅读,以上就是“Hadoop中的MultipleOutput实例使用”的内容了,经过本文的学习后,相信大家对Hadoop中的MultipleOutput实例使用这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





