Zookeeper и·ЁеҢәй«ҳеҸҜз”Ёж–№жЎҲ
жңҖиҝ‘з”ұдәҺдёҡеҠЎйңҖжұӮпјҢжөӢиҜ•еҗ„з§Қ组件зҡ„й«ҳеҸҜз”ЁжҖ§гҖӮз”ұдәҺжҲ‘们зҡ„зҺҜеўғеңЁAWS еҢ—дә¬йғЁзҪІгҖӮеҸӘжңүдёӨдёӘAviable ZoneпјҲеҸҜз”ЁеҢәпјүгҖӮ
жіЁйҮҠпјҡжңүдёӨдёӘж•°жҚ®дёӯеҝғпјҢзӣёдә’йңҖиҰҒеҒҡе®№зҒҫзҡ„йңҖжұӮпјҢе’Ңжң¬ж–ҮжөӢиҜ•зҡ„жғ…еҶөжҳҜзӣёеҗҢзҡ„гҖӮ
иҖҢZookeeperйңҖиҰҒ3дёӘд»ҘдёҠзҡ„еҚ•ж•°иҠӮзӮ№еҗҢж—¶е·ҘдҪңпјҢ并且пјҢеҝ…йЎ»дҝқиҜҒеҚҠж•°д»ҘдёҠзҡ„иҠӮзӮ№еӯҳжҙ»пјҢиҝҳиғҪжӯЈеёёжҸҗдҫӣжңҚеҠЎгҖӮ
йӮЈд№ҲпјҢй’ҲеҜ№еҸӘжңүдёӨдёӘAZзҡ„жғ…еҶөпјҢдёҚз®ЎжҖҺд№Ҳ规еҲ’пјҢйғҪжңүжҰӮзҺҮйҒҮеҲ°еӯҳеңЁеҚҠж•°д»ҘдёҠзҡ„AZжҢӮжҺүпјҢеҜјиҮҙж•ҙдёӘZookeeperдёҚеҸҜз”Ёзҡ„жғ…еҶөгҖӮ
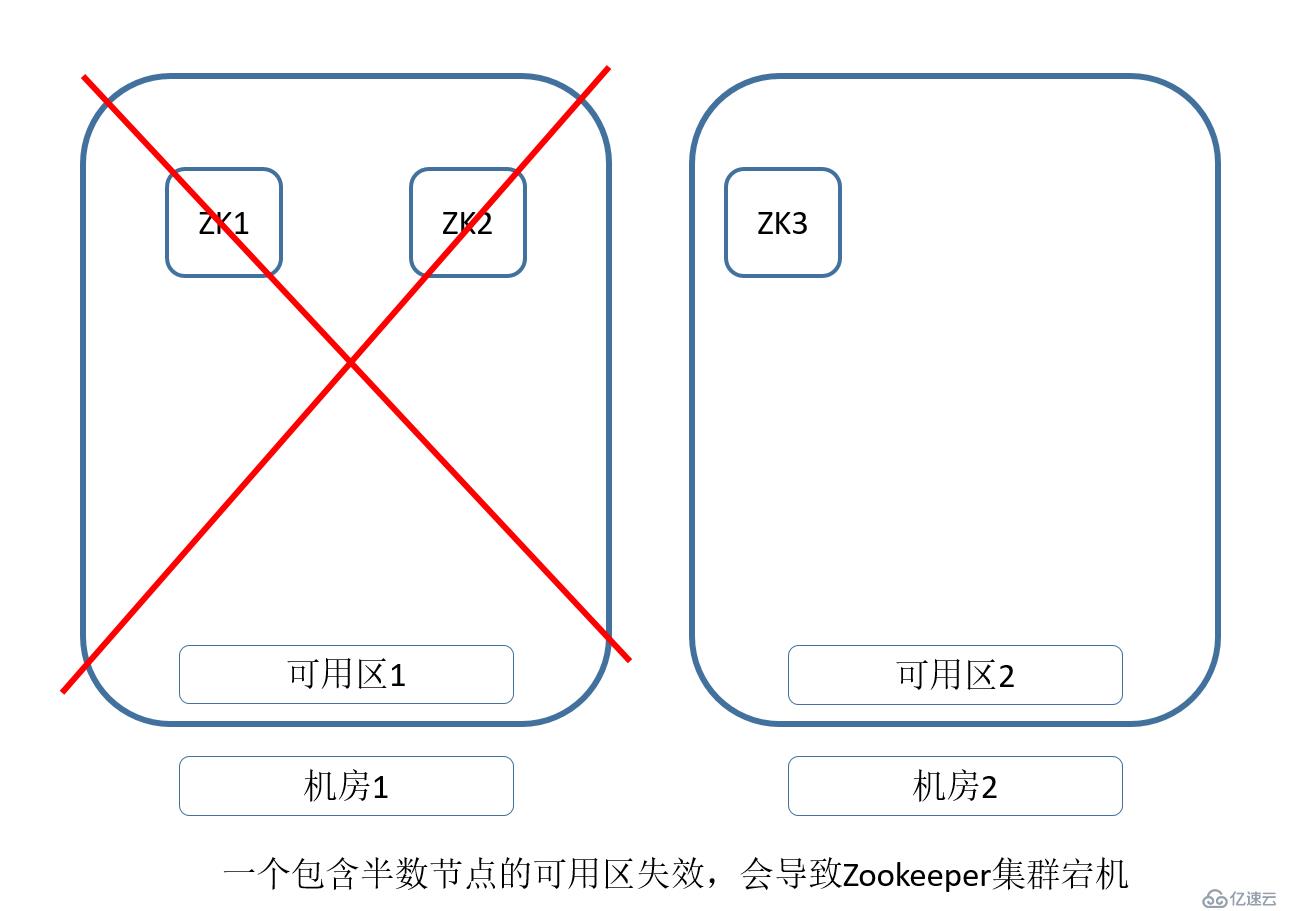
жүҖд»ҘпјҢжҲ‘们иғҪеҒҡзҡ„е°ұжҳҜпјҢеңЁиҝҷдёӘAZжҢӮжҺүд№ӢеҗҺпјҢжҲ‘们жҖҺд№Ҳе°Ҫеҝ«еӨ„зҗҶпјҢ并жҒўеӨҚзҺҜеўғгҖӮ
жҲ‘们еҮҶеӨҮдёӨдёӘиҪҜ件е®үиЈ…еҘҪпјҢеҸӮж•°й…ҚзҪ®еҘҪзҡ„жңәеҷЁгҖӮеңЁеҸҜз”ЁеҢә1е®Ңе…ЁжҢӮжҺүд№ӢеҗҺпјҢеҸҜд»ҘжүӢеҠЁеҗҜеҠЁдёӨдёӘеӨҮз”ЁиҠӮзӮ№гҖӮе°ҶеҸҜз”ЁеҢә2зҡ„Zookeeperж•°йҮҸеўһеҠ иҝҮеҚҠж•°гҖӮе°ұеҸҜд»ҘеңЁеҸҜз”ЁеҢә2жҒўеӨҚZookeeperзҡ„жңҚеҠЎгҖӮ
еҸӮиҖғдёӢеӣҫпјҡ
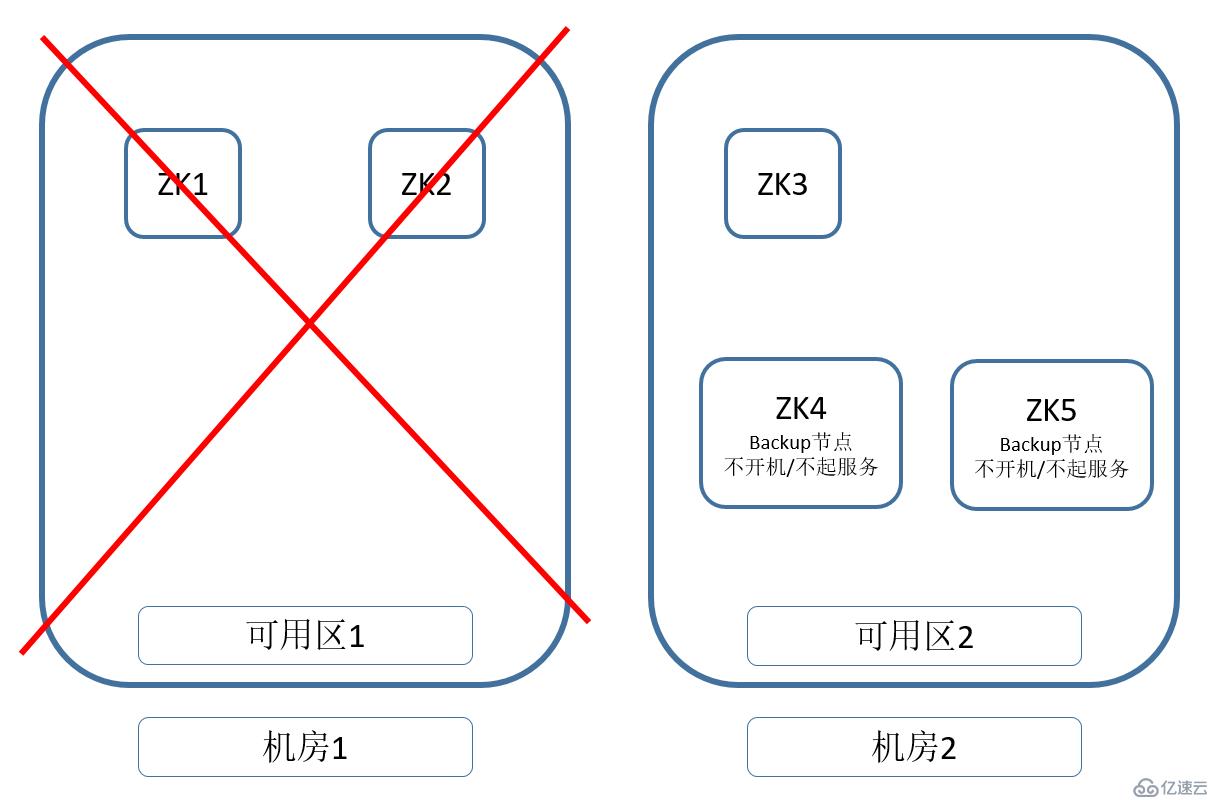
д»ҘдёҠзҡ„и®ҫжғіпјҢжҳҜеҗҰиғҪе®һзҺ°е‘ўпјҹ
йӮЈжҲ‘们д»ҠеӨ©е°ұжқҘжөӢиҜ•дёҖдёӢгҖӮ
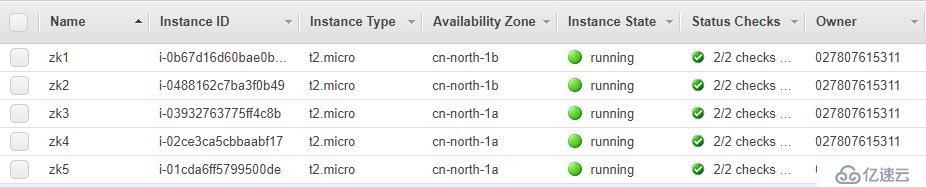
1. дёҖе…ұеҮҶеӨҮдәҶ5еҸ°жңәеҷЁпјҢдҪңдёәжөӢиҜ•
2. Zookeeperзҡ„дёӢиҪҪдёҺе®үиЈ…гҖӮ
2.1 Zookeeperе®ҳж–№дёӢиҪҪең°еқҖ
https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/
2.2 дёӢиҪҪиҪҜ件
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
2.3 иҜҰз»ҶZookeeperе®үиЈ…жӯҘйӘӨпјҢиҜ·еҸӮиҖғпјҡ
https://blog.51cto.com/hsbxxl/1971241
2.4 zoo.cfgзҡ„й…ҚзҪ®
#cat zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/data
dataLogDir=/data/zookeeper/log
clientPort=2181
autopurge.snapRetainCount=3
autopurge.purgeInterval=6
server.1=172.31.9.73:2888:3888
server.2=172.31.20.233:2888:3888
server.3=172.31.26.111:2888:3888
server.4=172.31.17.68:2888:3888
server.5=172.31.16.33:2888:3888
2.5 В ж №жҚ®zoo.cfgеҲӣе»әdataе’ҢlogдёӨдёӘж–Ү件еӨ№
mkdirВ -pВ /data/zookeeper/dataВ
mkdirВ -pВ /data/zookeeper/log
2.6 ж №жҚ®иҠӮзӮ№еҸ·з ҒпјҢдҝ®ж”№ж–Ү件
echoВ 1В >В /data/zookeeper/data/myid
3. дёҖе…ұеҮҶеӨҮдәҶ5еҸ°EC2иҝӣиЎҢжөӢиҜ•пјҢ并且йғҪе·Із»Ҹе®үиЈ…еҘҪZookeeper
дҪҶжҳҜеҸӘеҗҜеҠЁдёүеҸ°пјҢеҸҰдёӨдёӘжңәеҷЁдҪңдёәstandby
дёӢеӣҫеҸҜд»ҘзңӢеҲ°пјҢе·Із»ҸжңүдёүеҸ°еҗҜеҠЁzookeeperпјҢ
жіЁж„ҸпјҢеңЁZookeeperеҗҜеҠЁзҡ„иҝҮзЁӢдёӯпјҢеҝ…йЎ»дҝқиҜҒдёүеҸ°еҸҠд»ҘдёҠпјҢzookeeperйӣҶзҫӨжүҚиғҪжӯЈеёёе·ҘдҪң
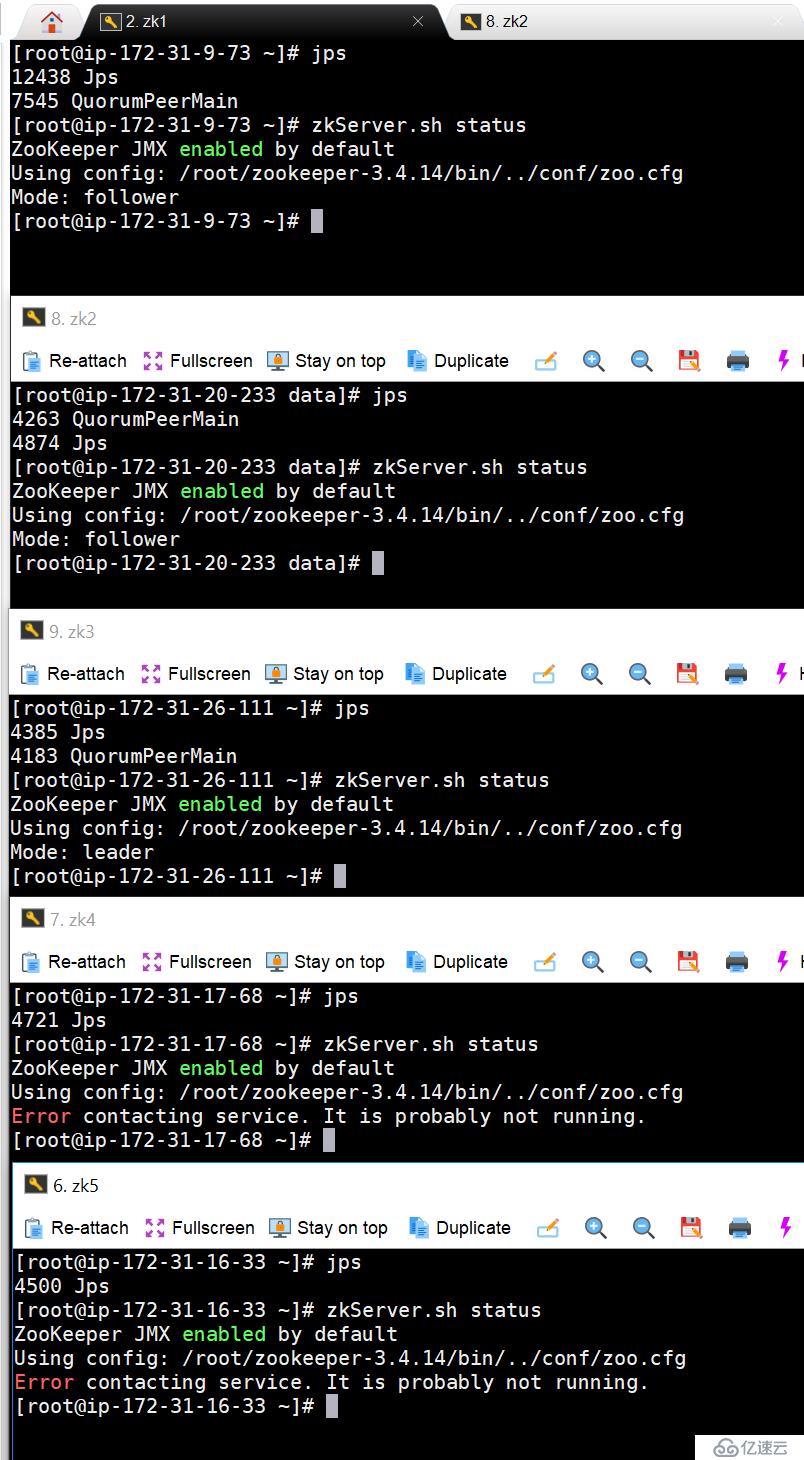
4. жҺҘдёӢжқҘпјҢжҲ‘ејҖе§ӢйҖҗдёӘжңәеҷЁе…іжңәпјҢзңӢzookeeperзҡ„зҠ¶жҖҒ
еҪ“еүҚleaderеңЁzk3дёҠпјҢжҲ‘们е…Ҳе…ій—ӯzk1пјҢеҶҚе…ій—ӯzk3пјҢзңӢLeaderдјҡдёҚдјҡйЈҳеҲ°zk2дёҠ
4.1 еңЁzk1дёҠжү§иЎҢkillпјҢжқҖжҺүиҝӣзЁӢ
[root@ip-172-31-9-73В ~]#В jps
12438В Jps
7545В QuorumPeerMain
[root@ip-172-31-9-73В ~]#В zkServer.shВ status
ZooKeeperВ JMXВ enabledВ byВ default
UsingВ config:В /root/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode:В follower
[root@ip-172-31-9-73В ~]#В killВ -9В 7545
4.2 еңЁzk5дёҠйҖҡиҝҮzkCliй“ҫжҺҘzk3пјҢ并еҸҜд»ҘжҹҘиҜўж•°жҚ®гҖӮ
еңЁzk1дёҠkillжҺүиҝӣзЁӢд№ӢеҗҺпјҢзҗҶи®әдёҠпјҢиҝҳжңүzk2е’Ңzk3еӯҳжҙ»пјҢдҪҶжҳҜzkCliзҡ„иҝһжҺҘжҳҫзӨәе·Із»ҸжҠҘй”ҷгҖӮ
[root@ip-172-31-16-33В bin]#В ./zkCli.shВ -serverВ 172.31.26.111:2181
ConnectingВ toВ 172.31.26.111:2181
......
[zk:В 172.31.26.111:2181(CONNECTED)В 0]В lsВ /
[zk-permanent,В zookeeper,В test]
[zk:В 172.31.26.111:2181(CONNECTED)В 1]В 2019-06-23В 07:28:06,581В [myid:]В -В INFOВ В [main-SendThread(ip-172-31-26-111.cn-north-1.compute.internal:2181):ClientCnxn$SendThread@1158]В -В UnableВ toВ readВ additionalВ dataВ fromВ serverВ sessionidВ 0x30000c504530000,В likelyВ serverВ hasВ closedВ socket,В closingВ socketВ connectionВ andВ attemptingВ reconnect
......
2019-06-23В 07:28:09,822В [myid:]В -В INFOВ В [main-SendThread(ip-172-31-26-111.cn-north-1.compute.internal:2181):ClientCnxn$SendThread@1025]В -В OpeningВ socketВ connectionВ toВ serverВ ip-172-31-26-111.cn-north-1.compute.internal/172.31.26.111:2181.В WillВ notВ attemptВ toВ authenticateВ usingВ SASLВ (unknownВ error)
2019-06-23В 07:28:09,824В [myid:]В -В INFOВ В [main-SendThread(ip-172-31-26-111.cn-north-1.compute.internal:2181):ClientCnxn$SendThread@879]В -В SocketВ connectionВ establishedВ toВ ip-172-31-26-111.cn-north-1.compute.internal/172.31.26.111:2181,В initiatingВ session
2019-06-23В 07:28:09,825В [myid:]В -В INFOВ В [main-SendThread(ip-172-31-26-111.cn-north-1.compute.internal:2181):ClientCnxn$SendThread@1158]В -В UnableВ toВ readВ additionalВ dataВ fromВ serverВ sessionidВ 0x30000c504530000,В likelyВ serverВ hasВ closedВ socket,В closingВ socketВ connectionВ andВ attemptingВ reconnect
4.3 жҲ‘们继з»ӯ killжҺүzk3дёҠзҡ„иҝӣзЁӢпјҢеҸӘдҝқз•ҷzk2дёҠзҡ„иҝӣзЁӢгҖӮдҪҶжҳҜжҲ‘们已з»Ҹж— жі•зЎ®и®Өzk2жҳҜLeaderиҝҳжҳҜFollowпјҢжҲ–иҖ…иҜҙпјҢд»–жҳҜеҗҰиҝҳдҝқз•ҷжңүж•°жҚ®гҖӮ
[root@ip-172-31-26-111В bin]#В jps
4183В QuorumPeerMain
4648В Jps
[root@ip-172-31-26-111В bin]#В killВ -9В 4183
[root@ip-172-31-26-111В bin]#В jps
4658В Jps
4.4 zk3дёҠиҝӣзЁӢkillжҺүд№ӢеҗҺпјҢй“ҫжҺҘе°ұдёҚеҸӘжҳҜдёҠйқўзҡ„жҠҘй”ҷдәҶпјҢиҖҢжҳҜзӣҙжҺҘиҝһжҺҘжӢ’з»қ
[root@ip-172-31-16-33В bin]#В ./zkCli.shВ -serverВ 172.31.26.111:2181
ConnectingВ toВ 172.31.26.111:2181
......
WelcomeВ toВ ZooKeeper!
2019-06-23В 07:35:18,411В [myid:]В -В INFOВ В [main-SendThread(ip-172-31-26-111.cn-north-1.compute.internal:2181):ClientCnxn$SendThread@1025]В -В OpeningВ socketВ connectionВ toВ serverВ ip-172-31-26-111.cn-north-1.compute.internal/172.31.26.111:2181.В WillВ notВ attemptВ toВ authenticateВ usingВ SASLВ (unknownВ error)
JLineВ supportВ isВ enabled
2019-06-23В 07:35:18,533В [myid:]В -В INFOВ В [main-SendThread(ip-172-31-26-111.cn-north-1.compute.internal:2181):ClientCnxn$SendThread@1162]В -В SocketВ errorВ occurred:В ip-172-31-26-111.cn-north-1.compute.internal/172.31.26.111:2181:В ConnectionВ refused
[zk:В 172.31.26.111:2181(CONNECTING)В 0]В 2019-06-23В 07:35:19,639В [myid:]В -В INFOВ В [main-SendThread(ip-172-31-26-111.cn-north-1.compute.internal:2181):ClientCnxn$SendThread@1025]В -В OpeningВ socketВ connectionВ toВ serverВ ip-172-31-26-111.cn-north-1.compute.internal/172.31.26.111:2181.В WillВ notВ attemptВ toВ authenticateВ usingВ SASLВ (unknownВ error)
2019-06-23В 07:35:19,640В [myid:]В -В INFOВ В [main-SendThread(ip-172-31-26-111.cn-north-1.compute.internal:2181):ClientCnxn$SendThread@1162]В -В SocketВ errorВ occurred:В ip-172-31-26-111.cn-north-1.compute.internal/172.31.26.111:2181:В ConnectionВ refused
4.5 еҸҜд»ҘзңӢеҲ°zk2дёҠзҡ„иҝӣзЁӢиҝҳеңЁпјҢ
#В jps
5155В QuorumPeerMain
5211В Jps
4.6 并且йҖҡиҝҮдёӢйқўе‘Ҫд»ӨпјҢеҸҜд»ҘжЈҖжҹҘеҲ°zk2 зҡ„2181з«ҜеҸЈиҝҳеңЁжҸҗдҫӣжңҚеҠЎ
#В echoВ ruokВ |В ncВ localhostВ 2181
imok
4.7 дҪҶжҳҜе…¶д»–е‘Ҫд»ӨжҳҜжІЎжңүжӯЈеёёиҫ“еҮәзҡ„пјҢеҸӘжңүecho ruok | nc localhost 2181иҫ“еҮәokгҖӮ
#В echoВ ruokВ |В ncВ 172.31.16.33В 2181
imok[root@ip-172-31-16-33В bin]#В echoВ confВ |В ncВ 172.31.16.33В 2181
ThisВ ZooKeeperВ instanceВ isВ notВ currentlyВ servingВ requests
#В echoВ dumpВ |В ncВ 172.31.16.33В 2181
ThisВ ZooKeeperВ instanceВ isВ notВ currentlyВ servingВ requests
4.8 В ZooKeeper еӣӣеӯ—е‘Ҫд»Ө
ZooKeeper еӣӣеӯ—е‘Ҫд»Ө | еҠҹиғҪжҸҸиҝ° |
conf | иҫ“еҮәзӣёе…іжңҚеҠЎй…ҚзҪ®зҡ„иҜҰз»ҶдҝЎжҒҜгҖӮ |
cons | еҲ—еҮәжүҖжңүиҝһжҺҘеҲ°жңҚеҠЎеҷЁзҡ„е®ўжҲ·з«Ҝзҡ„е®Ңе…Ёзҡ„иҝһжҺҘ / дјҡиҜқзҡ„иҜҰз»ҶдҝЎжҒҜгҖӮеҢ…жӢ¬вҖңжҺҘеҸ— / еҸ‘йҖҒвҖқзҡ„еҢ…ж•°йҮҸгҖҒдјҡиҜқ id гҖҒж“ҚдҪң延иҝҹгҖҒжңҖеҗҺзҡ„ж“ҚдҪңжү§иЎҢзӯүзӯүдҝЎжҒҜгҖӮ |
dump | еҲ—еҮәжңӘз»ҸеӨ„зҗҶзҡ„дјҡиҜқе’Ңдёҙж—¶иҠӮзӮ№гҖӮ |
envi | иҫ“еҮәе…ідәҺжңҚеҠЎзҺҜеўғзҡ„иҜҰз»ҶдҝЎжҒҜпјҲеҢәеҲ«дәҺ conf е‘Ҫд»ӨпјүгҖӮ |
reqs | еҲ—еҮәжңӘз»ҸеӨ„зҗҶзҡ„иҜ·жұӮ |
ruok | жөӢиҜ•жңҚеҠЎжҳҜеҗҰеӨ„дәҺжӯЈзЎ®зҠ¶жҖҒгҖӮеҰӮжһңзЎ®е®һеҰӮжӯӨпјҢйӮЈд№ҲжңҚеҠЎиҝ”еӣһвҖңimok вҖқпјҢеҗҰеҲҷдёҚеҒҡд»»дҪ•зӣёеә”гҖӮ |
stat | иҫ“еҮәе…ідәҺжҖ§иғҪе’ҢиҝһжҺҘзҡ„е®ўжҲ·з«Ҝзҡ„еҲ—иЎЁгҖӮ |
wchs | еҲ—еҮәжңҚеҠЎеҷЁ watch зҡ„иҜҰз»ҶдҝЎжҒҜгҖӮ |
wchc | йҖҡиҝҮ session еҲ—еҮәжңҚеҠЎеҷЁ watch зҡ„иҜҰз»ҶдҝЎжҒҜпјҢе®ғзҡ„иҫ“еҮәжҳҜдёҖдёӘдёҺwatch зӣёе…ізҡ„дјҡиҜқзҡ„еҲ—иЎЁгҖӮ |
wchp | йҖҡиҝҮи·Ҝеҫ„еҲ—еҮәжңҚеҠЎеҷЁВ watch зҡ„иҜҰз»ҶдҝЎжҒҜгҖӮе®ғиҫ“еҮәдёҖдёӘдёҺ sessionзӣёе…ізҡ„и·Ҝеҫ„гҖӮ |
4.9 жӯЈеёёжғ…еҶөдёӢпјҢд»ҘдёҠе‘Ҫд»ӨеҸҜд»Ҙиҫ“еҮәпјҡ
# echo dump | nc 172.31.20.233 2181
SessionTrackerВ dump:
org.apache.zookeeper.server.quorum.LearnerSessionTracker@77714302
ephemeralВ nodesВ dump:
SessionsВ withВ EphemeralsВ (0):
# echo conf | nc 172.31.20.233 2181
clientPort=2181
dataDir=/data/zookeeper/data/version-2
dataLogDir=/data/zookeeper/log/version-2
tickTime=2000
maxClientCnxns=60
minSessionTimeout=4000
maxSessionTimeout=40000
serverId=2
initLimit=10
syncLimit=5
electionAlg=3
electionPort=3888
quorumPort=2888
peerType=0
# echo envi| nc 172.31.20.233 2181
Environment:
zookeeper.version=3.4.14-4c25d480e66aadd371de8bd2fd8da255ac140bcf,В builtВ onВ 03/06/2019В 16:18В GMT
host.name=ip-172-31-20-233.cn-north-1.compute.internal
java.version=1.8.0_212
java.vendor=OracleВ Corporation
java.home=/usr/java/jdk1.8.0_212-amd64/jre
java.class.path=/root/zookeeper-3.4.14/bin/../zookeeper-server/target/classes:/root/zookeeper-3.4.14/bin/../build/classes:/root/zookeeper-3.4.14/bin/../zookeeper-server/target/lib/*.jar:/root/zookeeper-3.4.14/bin/../build/lib/*.jar:/root/zookeeper-3.4.14/bin/../lib/slf4j-log4j12-1.7.25.jar:/root/zookeeper-3.4.14/bin/../lib/slf4j-api-1.7.25.jar:/root/zookeeper-3.4.14/bin/../lib/netty-3.10.6.Final.jar:/root/zookeeper-3.4.14/bin/../lib/log4j-1.2.17.jar:/root/zookeeper-3.4.14/bin/../lib/jline-0.9.94.jar:/root/zookeeper-3.4.14/bin/../lib/audience-annotations-0.5.0.jar:/root/zookeeper-3.4.14/bin/../zookeeper-3.4.14.jar:/root/zookeeper-3.4.14/bin/../zookeeper-server/src/main/resources/lib/*.jar:/root/zookeeper-3.4.14/bin/../conf:
java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib
java.io.tmpdir=/tmp
java.compiler=<NA>
os.name=Linux
os.arch=amd64
os.version=4.14.123-86.109.amzn1.x86_64
user.name=root
user.home=/root
user.dir=/root/zookeeper-3.4.14/bin
5. иҝҷдёӘж—¶еҖҷпјҢжҲ‘еҺ»еҗҜеҠЁеҸҰеӨ–дёӨдёӘеӨҮз”ЁиҠӮзӮ№пјҢzk4пјҢzk5.иҝҷдёӘдёӨдёӘиҠӮзӮ№йғҪжҳҜ第дёҖж¬ЎеҗҜеҠЁгҖӮ
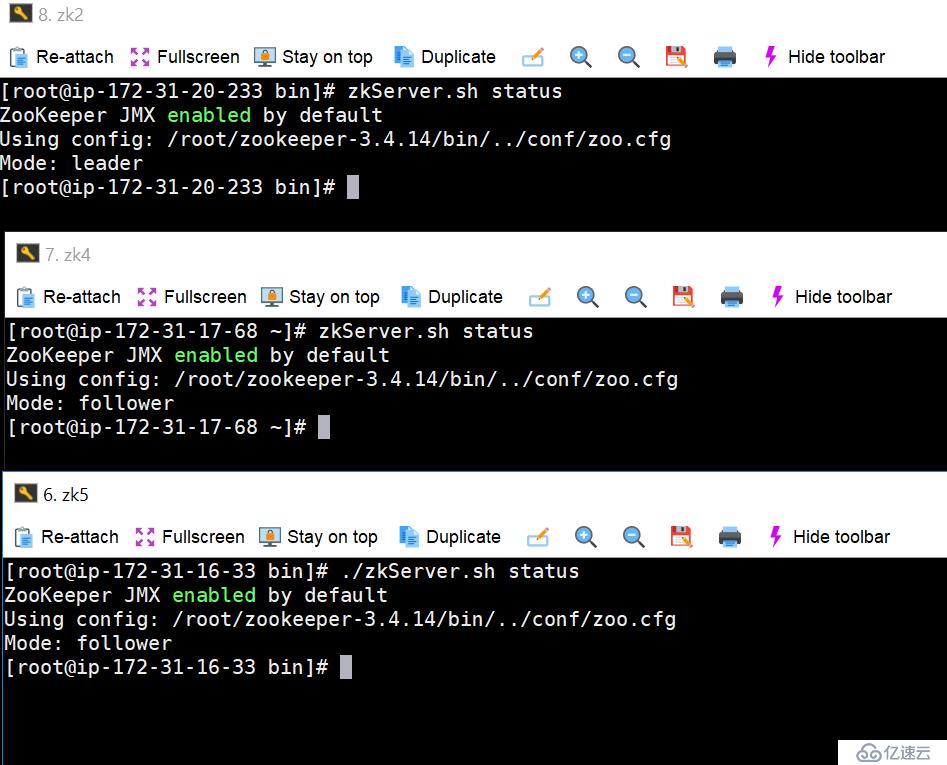
6. еҶҚж¬ЎиҝһжҺҘеҲ°zookeeperдёҠпјҢеҸҜд»ҘзңӢеҲ°пјҢиҮіе°‘ж•°жҚ®иҝҳжҳҜжІЎжңүдёўеӨұзҡ„
[root@ip-172-31-16-33В bin]#В ./zkCli.shВ -serverВ 172.31.16.33:2181
ConnectingВ toВ 172.31.16.33:2181
......
[zk:В 172.31.16.33:2181(CONNECTED)В 0]В lsВ /
[zk-permanent,В zookeeper,В test]
7. йҖҡиҝҮд»ҘдёҠжөӢиҜ•пјҢдјјд№ҺжҳҜиҫҫеҲ°жҲ‘们预жңҹзҡ„з»“жһңгҖӮе”ҜдёҖзҡ„дёҖзӮ№е°Ҹй—®йўҳпјҢе°ұжҳҜпјҡжҲ‘们жңү3дёӘиҠӮзӮ№пјҢдёәд»Җд№Ҳе…ій—ӯ1дёӘпјҢеү©дҪҷдёӨдёӘпјҢе°ұдёҚиғҪжӯЈеёёиҝҗиЎҢдәҶе‘ўпјҹ
е…¶е®һпјҢиҝҷйҮҢжҳҜжңүдёӘвҖңжғіеҪ“然вҖқзҡ„е°Ҹй—®йўҳгҖӮ
жҲ‘们д»ҘдёәпјҢеҸӘеҗҜеҠЁдёүдёӘ. е…¶е®һпјҢZookeeperйӣҶзҫӨпјҢиҜҶеҲ«зҡ„жҳҜ5дёӘ, дёәд»Җд№Ҳе‘ўпјҹ
Zookeeperйқ д»Җд№ҲеҺ»иҜҶеҲ«йӣҶзҫӨдёӯжңүеҮ дёӘиҠӮзӮ№е‘ўпјҹеҪ“然дёҚжҳҜйқ вҖңжғіеҪ“然вҖқгҖӮдёҖе®ҡжҳҜжңүй…ҚзҪ®ж–Ү件е‘ҠиҜүе®ғгҖӮZookeeperпјҢеҸӘжңүдёӨдёӘй…ҚзҪ®ж–Ү件zoo.cfgе’ҢmyidгҖӮ
йӮЈе°ұеҸӘжңүzoo.cfgдјҡеҪұе“ҚеҲ°е®ғдәҶгҖӮ
8. жҲ‘е°Ҷzoo.cfgеҒҡеҰӮдёӢдҝ®ж”№д№ӢеҗҺгҖӮеҸӘејҖеҗҜ3дёӘиҠӮзӮ№пјҢеңЁе…ій—ӯдёҖдёӘиҠӮзӮ№д№ӢеҗҺпјҢиҝҳжҳҜеҸҜд»ҘжӯЈеёёиҝҗиЎҢзҡ„гҖӮ
жіЁйҮҠжҺүserver2е’Ңserver5
#В catВ zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/data
dataLogDir=/data/zookeeper/log
clientPort=2181
autopurge.snapRetainCount=3
autopurge.purgeInterval=6
server.1=172.31.9.73:2888:3888
#server.2=172.31.20.233:2888:3888
server.3=172.31.26.111:2888:3888
server.4=172.31.17.68:2888:3888
#server.5=172.31.16.33:2888:3888
9. е…ій—ӯserver4д№ӢеҗҺпјҢиҝҳжңүserver2е’Ңserver3жҙ»зқҖгҖӮ
[root@ip-172-31-26-111В ~]#В zkServer.shВ status
ZooKeeperВ JMXВ enabledВ byВ default
UsingВ config:В /root/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode:В leader
[root@ip-172-31-9-73В ~]#В zkServer.shВ status
ZooKeeperВ JMXВ enabledВ byВ default
UsingВ config:В /root/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode:В follower
10. жҖ»з»“пјҢеҰӮжһңиҖғиҷ‘дёӨдёӘAZзҡ„жғ…еҶөдёӢпјҢzookeeperиҠӮзӮ№ж•°еӨҡзҡ„AZеҮәзҺ°зҒҫйҡҫжғ…еҶөпјҢжҲ‘们еҰӮдҪ•еҝ«йҖҹжҒўеӨҚпјҹ
(еҒҮи®ҫServer1/Server2еңЁ1AZпјҢServer3/Server4/Server5еңЁ2AZ)
10.1. еңЁZookeeperиҠӮзӮ№е°‘зҡ„AZпјҢеӨҡеҮҶеӨҮ2еҸ°й…ҚзҪ®еҘҪzookeeperзҡ„EC2пјҢ并关жңәеҫ…дҪҝз”ЁгҖӮServer4/Server5е…·дҪ“zoo.cfgй…ҚзҪ®еҰӮдёӢ
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/data
dataLogDir=/data/zookeeper/log
clientPort=2181
autopurge.snapRetainCount=3
autopurge.purgeInterval=6
server.3=172.31.26.111:2888:3888
server.4=172.31.17.68:2888:3888
server.5=172.31.16.33:2888:3888
10.2. В Server1/Server2/Server3пјҢжҳҜжӯЈеёёиҝҗиЎҢзҡ„иҠӮзӮ№пјҢй…ҚзҪ®еҰӮдёӢпјҡ
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/data
dataLogDir=/data/zookeeper/log
clientPort=2181
autopurge.snapRetainCount=3
autopurge.purgeInterval=6
server.1=172.31.9.73:2888:3888
server.2=172.31.20.233:2888:3888
server.3=172.31.26.111:2888:3888
10.3. В зҒҫйҡҫеҸ‘з”ҹпјҢServer1/Server2жүҖеңЁзҡ„1AZжҢӮжҺүзҡ„жғ…еҶөдёӢпјҢйңҖиҰҒдәәе·Ҙд»Ӣе…ҘпјҢе°ҶServer3зҡ„й…ҚзҪ®жӣҙж”№дёәеҰӮдёӢй…ҚзҪ®пјҢ并йҮҚеҗҜServer3зҡ„zookeeperжңҚеҠЎпјҢ然еҗҺеҗҜеҠЁServer4/Server5пјҢдёҖе®ҡиҰҒе…ҲеҗҜеҠЁServer3пјҢжіЁж„ҸйЎәеәҸгҖӮ
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/data
dataLogDir=/data/zookeeper/log
clientPort=2181
autopurge.snapRetainCount=3
autopurge.purgeInterval=6
server.3=172.31.26.111:2888:3888
server.4=172.31.17.68:2888:3888
server.5=172.31.16.33:2888:3888
10.4 ж—ҘеёёиҝҗиЎҢзҠ¶жҖҒ
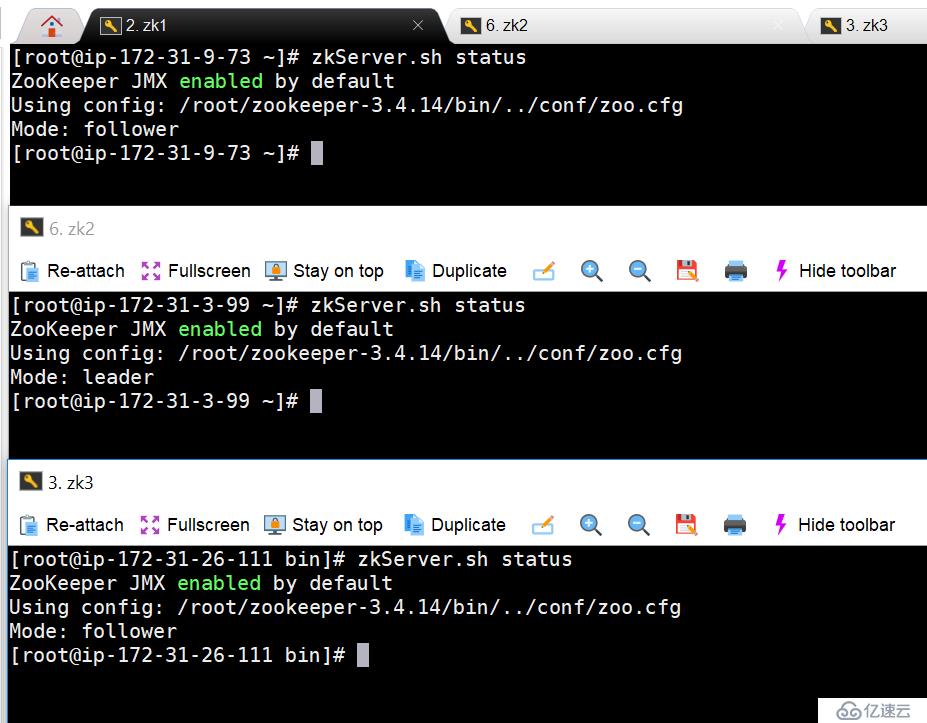
10.5 жЈҖжҹҘе·Із»ҸеҲӣе»әзҡ„znodeдҝЎжҒҜ
./zkCli.shВ -serverВ 172.31.16.33:2181В lsВ /
ConnectingВ toВ 172.31.16.33:2181
[zk-permanent,В zookeeper,В test]
10.6 е…ій—ӯServer1/Server2пјҢжіЁж„ҸйЎәеәҸпјҢе…Ҳе…ій—ӯfollowпјҢеҰӮжһңе…Ҳе…ій—ӯleaderпјҢдјҡеҸ‘з”ҹеҲҮжҚўгҖӮжҲ‘们жңҹжңӣзҡ„жҳҜServer3жңҖеҗҺд»Ҙfollowзҡ„иә«д»Ҫеӯҳжҙ»гҖӮ
11. жңҖз»ҲеҸҜд»ҘзңӢеҲ°жөӢиҜ•з»“жһңпјҢдёҖеҲҮйғҪжҳҜжҢүз…§жҲ‘们вҖңжғіеҪ“然вҖқзҡ„ж–№еҗ‘еҸ‘еұ•гҖӮ
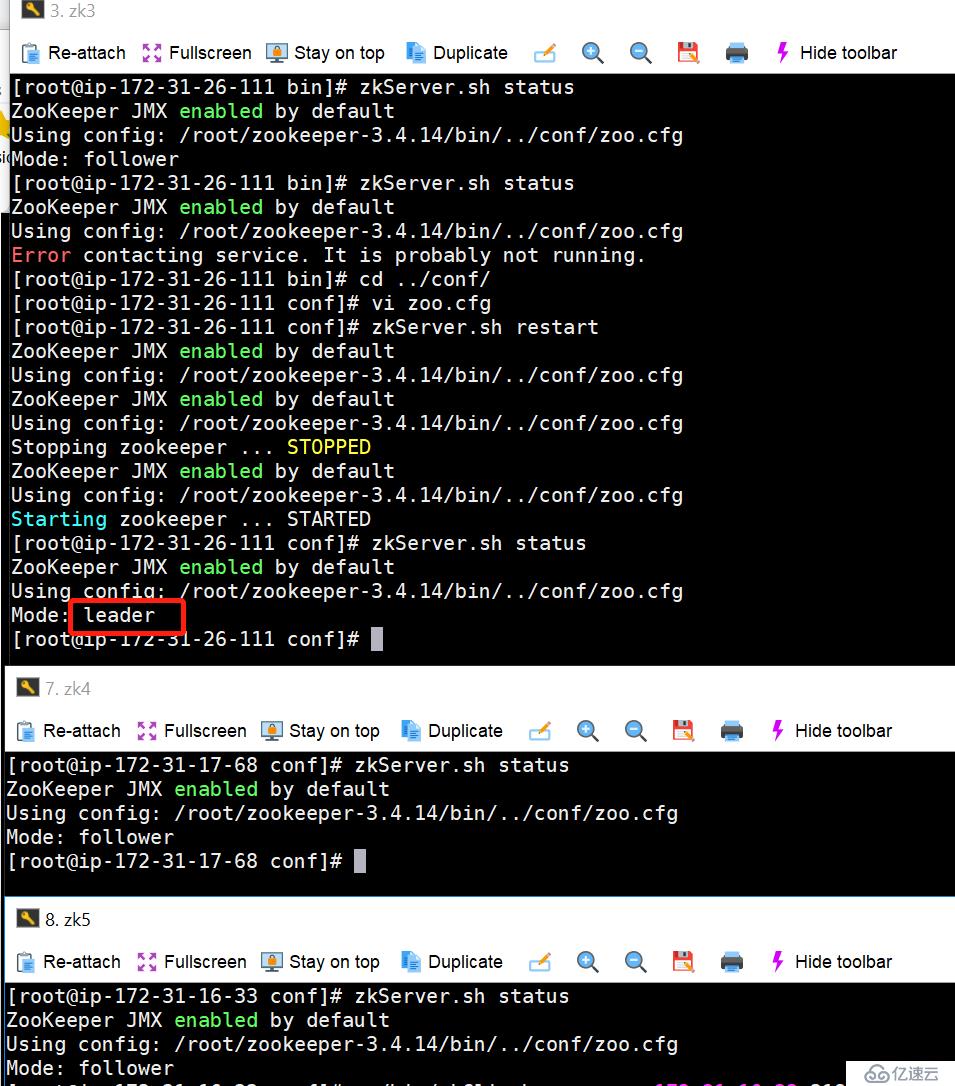
12. жңҖеҗҺйӘҢиҜҒzookeeperдёӯзҡ„znodeж•°жҚ®,иҝҳжҳҜйғҪеӯҳеңЁзҡ„гҖӮ
./zkCli.shВ В -serverВ 172.31.16.33:2181В lsВ /
ConnectingВ toВ 172.31.16.33:2181
[zk-permanent,В zookeeper,В test]
13. е…¶е®һж•°жҚ®дёҖзӣҙжҳҜеңЁиҝҷдёӘи·Ҝеҫ„дёӢпјҢеҸӘиҰҒжңүдёҖдёӘиҠӮзӮ№иҝҳдҝқз•ҷпјҢе°ұдјҡдҝқеӯҳдёӢеҺ»гҖӮ
#В lsВ /data/zookeeper/data/
myidВ В version-2В В zookeeper_server.pid
жіЁж„ҸпјҡдёҖе®ҡиҰҒдҝқиҜҒServer4/Server5зҡ„дёӢйқўдёӨдёӘи·Ҝеҫ„жҳҜз©әзҡ„пјҢдёҚ然дјҡеҮәзҺ°пјҢServer4/Server5иҜҶеҲ«зҡ„жҳҜд№ӢеүҚзҡ„йҷҲж—§дҝЎжҒҜгҖӮ
/data/zookeeper/data/version-2
/data/zookeeper/log/version-2
14. иҜҙеҲ°иҝҷйҮҢпјҢжҲ‘们еҸҜд»ҘзҗҶи§ЈеҲ°пјҢZookeeperзҡ„е…ЁйғЁж•°жҚ®пјҢйғҪжҳҜеӯҳж”ҫеңЁдёӢйқўдёӨдёӘи·Ҝеҫ„дёӯгҖӮеҰӮжһңйңҖиҰҒеҒҡеӨҮд»ҪпјҢеҸҜд»ҘзӣҙжҺҘеңЁOSеұӮйқўпјҢеҒҡcpеӨҮд»ҪеҚіеҸҜгҖӮ
dataDir=/data/zookeeper/data
dataLogDir=/data/zookeeper/log
иЎҚз”ҹдёҖдёӘжғіжі•пјҢе°ұжҳҜеҰӮжһңжғіеҒҡи·ЁRegionпјҢеҢ—дә¬пјҲдё»зҺҜеўғпјүеҲ°е®ҒеӨҸпјҲе®№зҒҫзҺҜеўғпјүзҡ„zookeeperзҡ„й«ҳеҸҜз”ЁжҖҺд№ҲеҒҡе‘ўпјҹ
жҲ‘们еҸҜд»ҘиҖғиҷ‘е°ҶеҢ—дә¬зҡ„zookeeperзҡ„ж•°жҚ®ж–Ү件е®ҡжңҹеӨҮд»ҪпјҢ并еҜје…ҘеҲ°е®ҒеӨҸзҡ„зҺҜеўғгҖӮ
е…·дҪ“жӯҘйӘӨпјҡ
<1. еңЁе®ҒеӨҸеҗҜеҠЁдёҖдёӘZookeeperйӣҶзҫӨпјҢ并й…ҚзҪ®еҘҪпјҢ然еҗҺе…ій—ӯzookeeperжңҚеҠЎпјҢжё…з©әжҺүж•°жҚ®ж–Ү件еӨ№гҖӮ
<2. еңЁеҢ—дә¬пјҢйҖҡиҝҮи„ҡжң¬е®ҡжңҹжЈҖжҹҘzookeeperеҗ„дёӘиҠӮзӮ№зҠ¶жҖҒпјҢд»ҺдёҖдёӘиҝҗиЎҢеҒҘеә·зҡ„иҠӮзӮ№пјҢе®ҡжңҹеӨҮд»Ҫж•°жҚ®еҲ°S3зҡ„дёҖдёӘbucketпјҢдёәжҜҸдёӘж–Ү件еҠ дёҠж—¶й—ҙжҲігҖӮ
<3. йҖҡиҝҮS3зҡ„Cross Region ReplicationпјҢеҗҢжӯҘеҲ°е®ҒеӨҸгҖӮ
<4. 然еҗҺеңЁе®ҒеӨҸпјҢд»ҺS3иҜ»еҸ–еӨҮд»Ҫж–Ү件пјҢ并иҝҳеҺҹеҲ°зҒҫеӨҮзҡ„zookeeperдёӯгҖӮ





