这篇文章主要介绍了HIVE体系架构是怎么样的,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
*注:本文基于hive-0.8.1写的
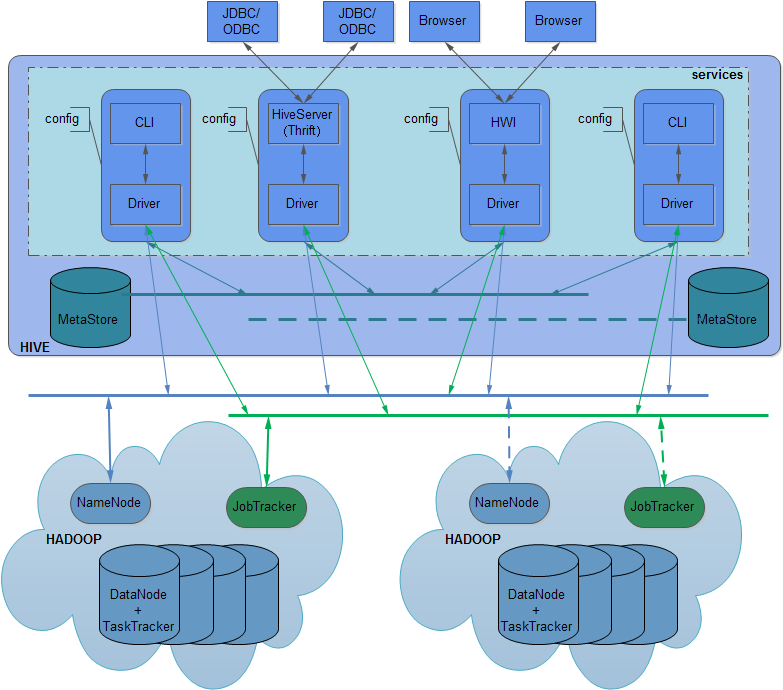
架构图:
一、 service
1、 hive有三种service,分别是cli,hiveserver和hwi。
2、 cli是命令行工具,为默认服务,启动方式$HIVE_HOME/bin/hive 或 $HIVE_HOME/bin/hive --service cli。
3、 hiverserver通过thrift对外提供服务,默认端口10000,启动方式为$HIVE_HOME/bin/hive--service hiveserver。
4、 hwi为web接口,可以通过浏览器访问hive,默认端口9999,启动方式为$HIVE_HOME/bin/hive--service hwi。
5、 每个服务间互相独立,有各自的配置文件(配置metasotre/namenode/jobtracker等),如果metasotre的配置一样则物理上对应同一hive库。
6、 Driver用于解释、编译、优化、执行HQL,每个service的Driver相互独立。
7、 CLI为用户提供命令行接口,每个CLI独享配置,即在一个CLI里修改配置不影响别的CLI。
8、 多个JDBC可同时连到同一HiveServer上,所有会话共享一份配置。(注:从0.9.0起hiveserver配置已经从global降为session,即每个session的配置相互独立,见 [HIVE-2503])
9、 多个浏览器可同时连到同一HWI上,所有会话共享一份配置。
二、MetaStore
MetaStore位置通过参数javax.jdo.option.ConnectionURL来指定,可在会话中自由修改。相关的参数包括:
javax.jdo.option.ConnectionDriverName#数据库驱动
javax.jdo.option.ConnectionURL #数据库ip端口库名等
javax.jdo.option.ConnectionUserName #用户名
javax.jdo.option.ConnectionPassword #密码
通过修改这些参数可以在多个MetaStore间热切换,可用于HA。
三、NameNode与JobTracker
NameNode由fs.default.name指定,JobTracker由mapred.job.tracker指定,这两个参数都可以在会话中自由修改来指向不同的NameNode和JobTracker。
配合MetaStore可以有多种组合出现,例如在同一个MetaStore里让table1的数据存在HDFS1,用JobTracker1计算,table2的数据存在HDFS2,用JobTracker2计算,或者让两个表都在JobTracker3上计算。
四、注意事项
1、 NameNode和JobTracker最好指向同一个集群,否则计算的时候需要跨集群复制数据。
2、 在MetaStore存储的是表数据文件的绝对路径,当心其与NameNode/JobTracker不再同一个集群里导致夸集群复制。
3、 对hiveserver与hwi配置的修改会作用到同一service上的所有会话。 (注:从0.9.0起hiveserver配置已经从global降为session,即每个session的配置相互独立
感谢你能够认真阅读完这篇文章,希望小编分享的“HIVE体系架构是怎么样的”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





