zeppelin该如何入门使用,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
text
默认使用scala语言输出text内容 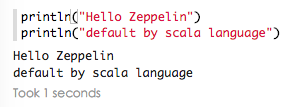
shell 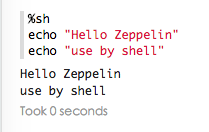
html
scala 输出html 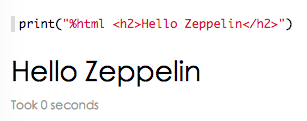
shell 输出html 
table
scala 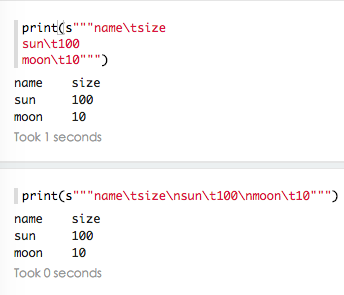
shell 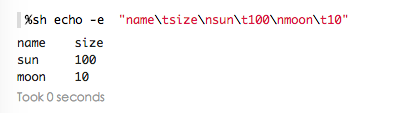
table
scala: 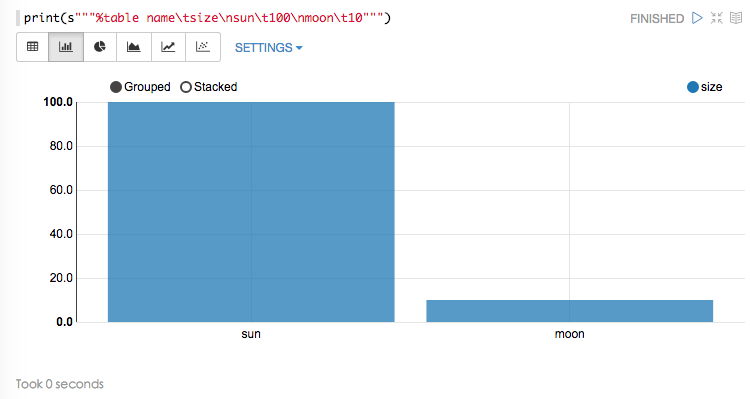
shell: 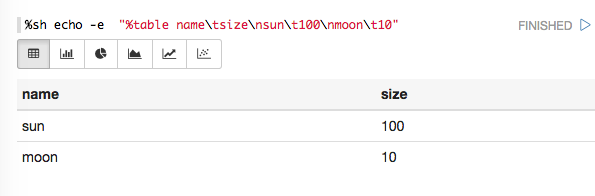
html: 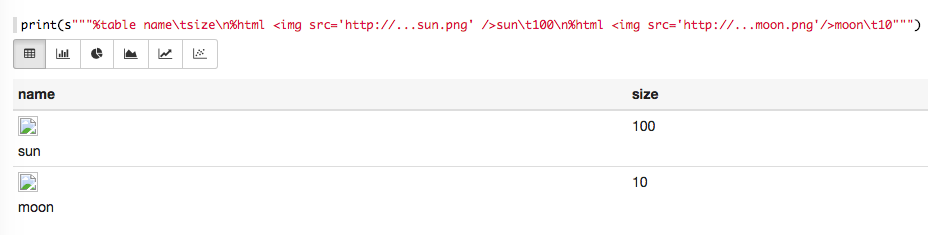
动态表格
使用表格模板
文本输入格式:
使用 formName模板,使用{formName=defaultValue} 提供默认值 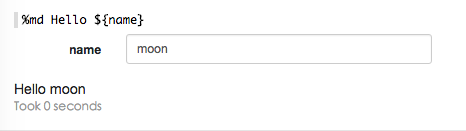
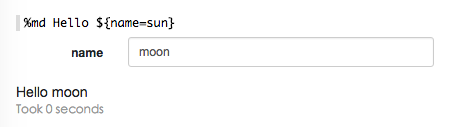
下拉选择表格
${formName=defaultValue,option1|option2…} 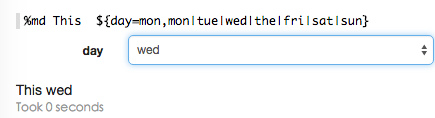
k-v格式,${formName=defaultValue,
option1(DisplayName)|option2(DisplayName)…} 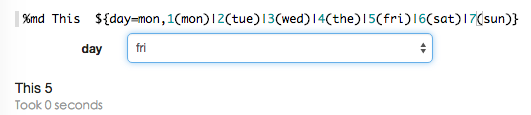
动态编程 
z 是ZeppelinContext对象
文本输入格式 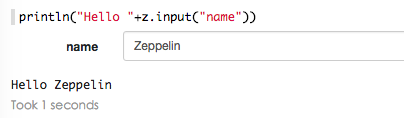
带默认值的文本输入格式 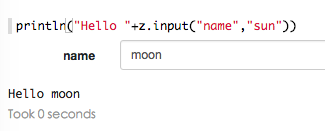
下拉选择表格 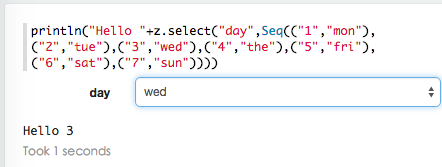
Notebook as Homepage
这部分不是很重,直接看这个链接吧,http://zeppelin.incubator.apache.org/docs/manual/notebookashomepage.html
spark,http://zeppelin.incubator.apache.org/docs/interpreter/spark.html
hive
md
sh
flink
and so on
上面都有涉及,如何使用
Data Refine
下载需要bank数据,http://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank.zip
首先,将csv格式数据转成Bank对象RDD,并过滤表头列
val bankText = sc.textFile("/home/cluster/data/test/bank/bank-full.csv")
case class Bank(age:Integer, job:String, marital : String, education : String, balance : Integer)
val bank = bankText.map(s=>s.split(";")).filter(s=>s(0)!="\"age\"").map(
s=>Bank(s(0).toInt,
s(1).replaceAll("\"", ""),
s(2).replaceAll("\"", ""),
s(3).replaceAll("\"", ""),
s(5).replaceAll("\"", "").toInt
)
)
// Below line works only in spark 1.3.0.
// For spark 1.1.x and spark 1.2.x,
// use bank.registerTempTable("bank") instead.
bank.toDF().registerTempTable("bank")1234567891011121314151617Data Retrieval
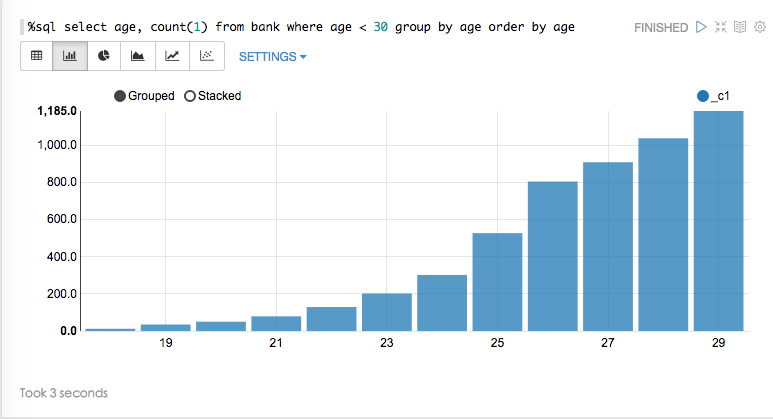
Suppose we want to see age distribution from bank. To do this, run:
执行以下语句,可看到年龄的分布:
%sql select age, count(1) from bank where age < 30 group by age order by age1
动态输入maxAge参数(默认是30岁):
%sql select age, count(1) from bank where age < ${maxAge=30} group by age order by age1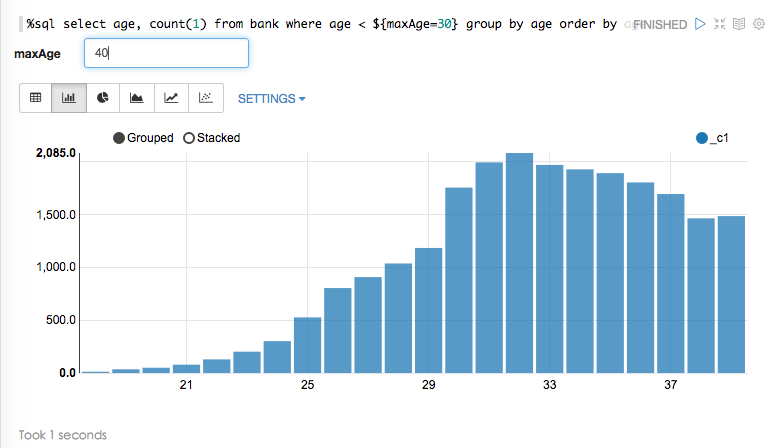
根据婚姻状况选项,查看年龄分布状况:
%sql select age, count(1) from bank where marital="${marital=single,single|divorced|married}" group by age order by age1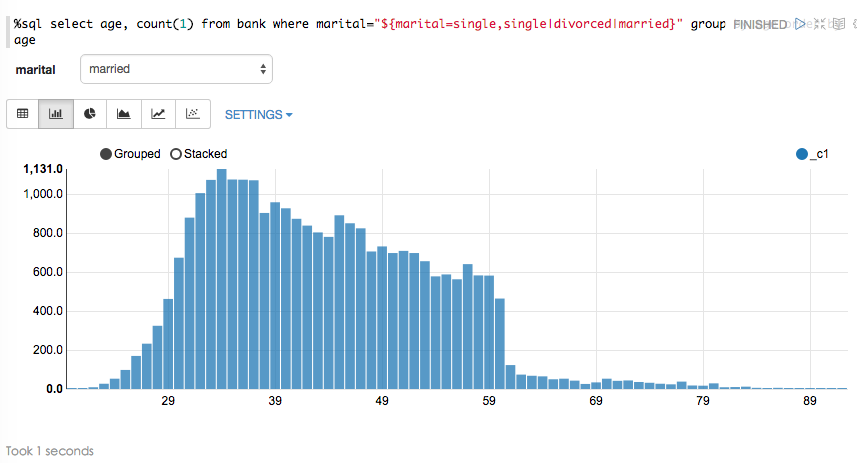
Zeppelin的工作方式和Spark的Thrift Server很像,都是向Spark提交一个应用(Application),然后每一个查询对应一个stage。 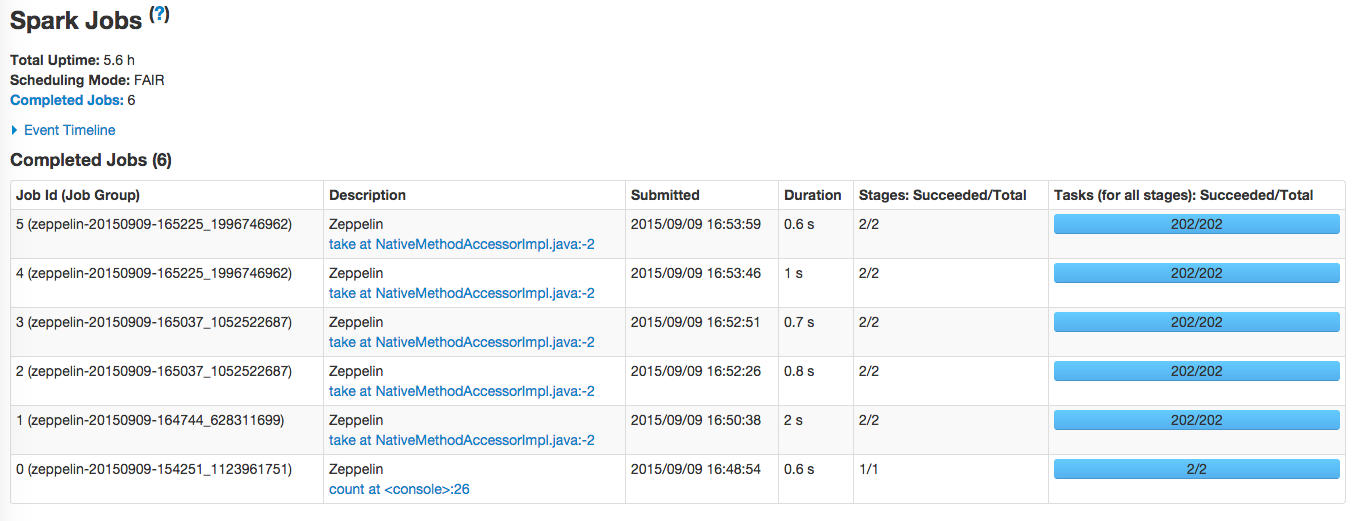
因此,在启动Zeppelin前,可以通过配置环境变量ZEPPELIN_JAVA_OPTS来对即将启动的Spark driver进行配置,例如“-Dspark.executor.memory=6g -Dspark.cores.max=32”。
关于zeppelin该如何入门使用问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





