这篇文章主要介绍“hadoop2.7.1环境的搭建方法”,在日常操作中,相信很多人在hadoop2.7.1环境的搭建方法问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”hadoop2.7.1环境的搭建方法”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
在老板的支持下,陆续划拉到了10几台机器,绑定了固定IP,工作之余开始了Hadoop之旅。将要点记录下来,以备查阅。
硬件构成:
Resource | Volume |
CPU | 2 cores |
Memory | 4 GB |
Disk | 500 GB |
Network | 100 M |
软件构成:
Name | Version | Install Path |
CentOS | 6.7 x86_64 | / |
Oracle JDK | 7u79-linux-x64 | /usr/local/java/ |
Hadoop | 2.7.1 | /home/hadoop/ |
Flume | 1.6.0 | /home/flume/ |
Maven | 3.3.9 | /usr/local/maven/ |
Ant | 1.9.6 | /usr/local/ant |
5.6.21 Community Server | /home/mysql/ | |
D3.js | v3 |
整体架构:
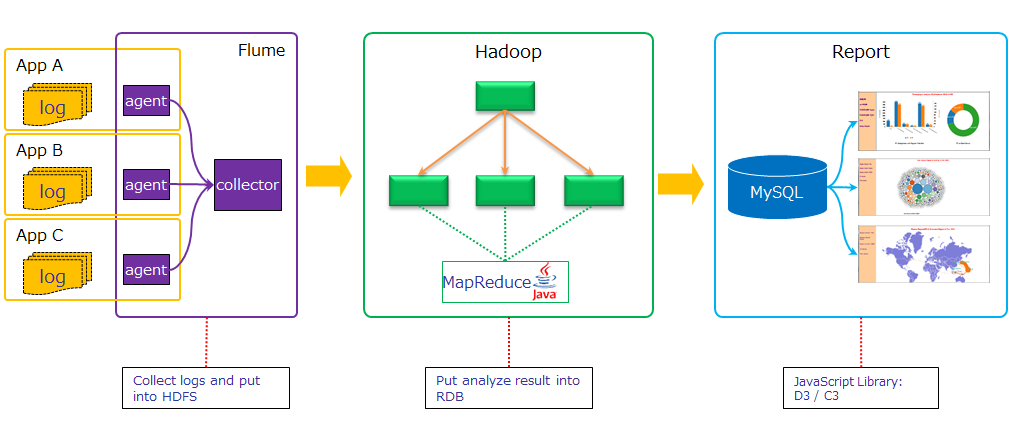
DFS和Yarn构成:
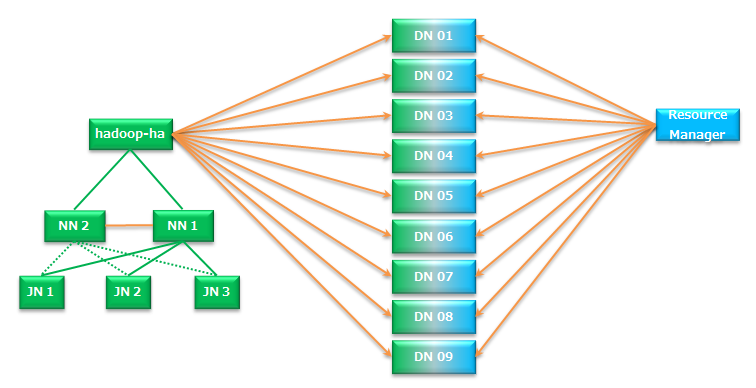
各个节点需要的配置:
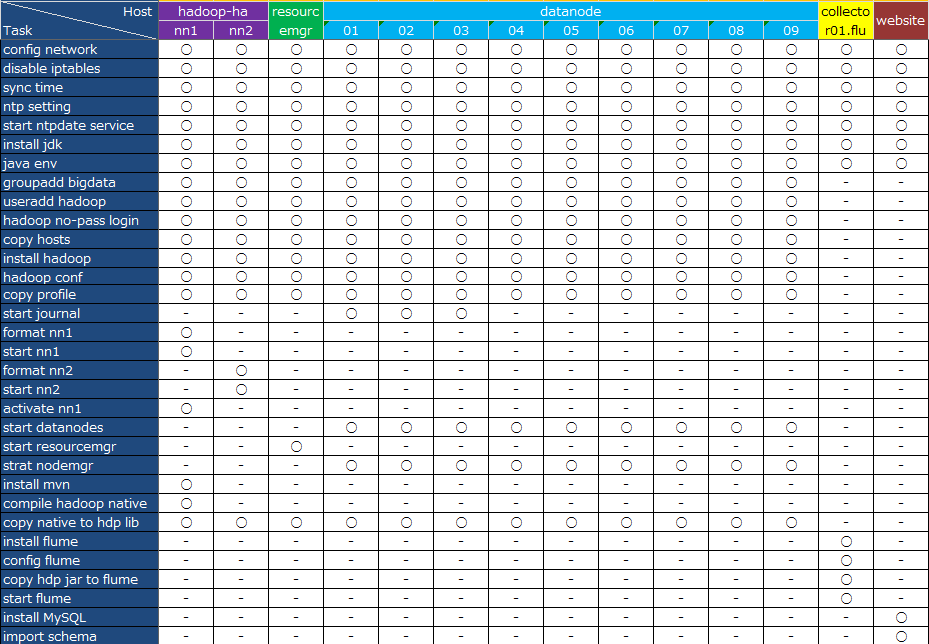
调试hadoop节点用到的命令:
sbin/hadoop-daemon.sh start journal
bin/hdfs namenode format
sbin/hadoop-daemon.sh start namenode
bin/hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode
bin/hdfs haadmin -transitionToActive nn1
sbin/hadoop-daemons.sh start datanode
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
调试完毕后的集群启动/关闭命令:
sbin/start-dfs.sh
sbin/start-yarn.sh
bin/hdfs haadmin -transitionToActive nn1
sbin/stop-dfs.sh
sbin/stop-yarn.sh
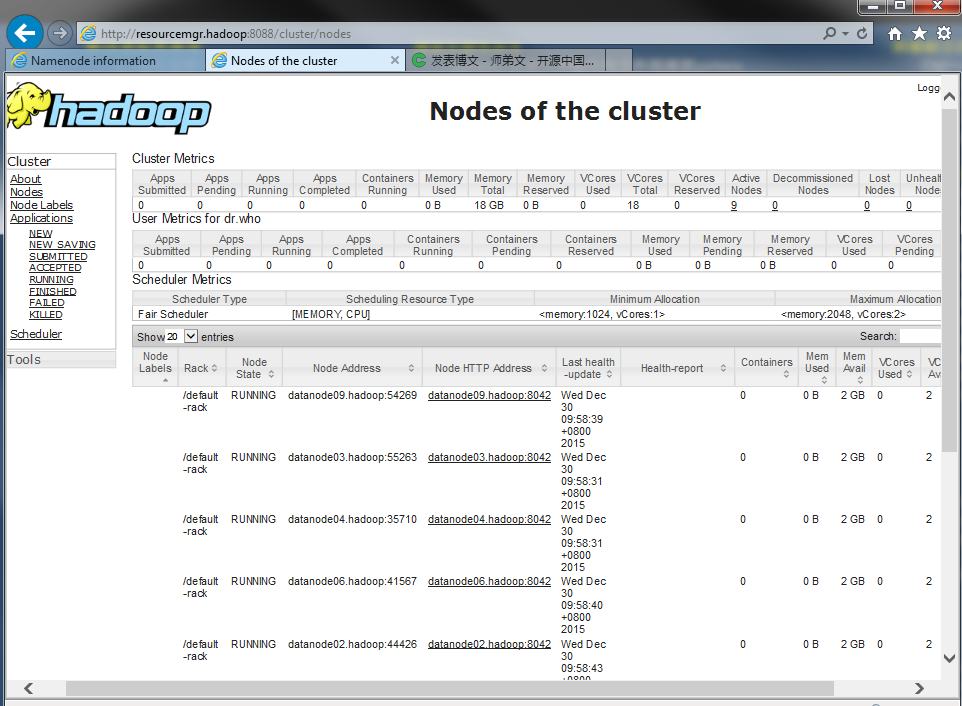
DFS管理界面:
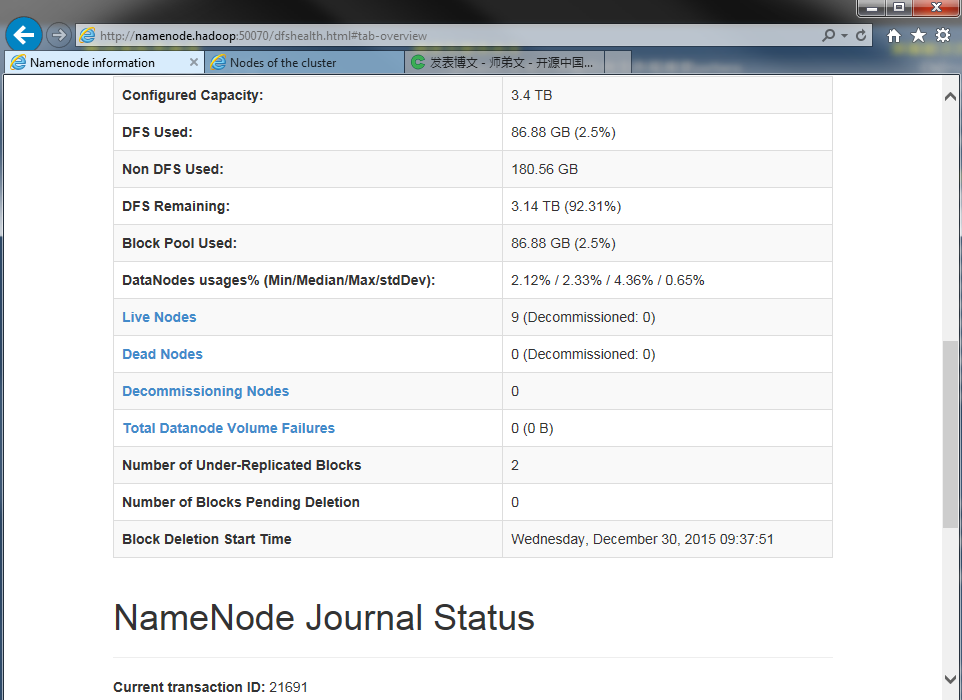
YARN管理界面:
正在把150G日志手动导入DFS,暂时还没用上Flume,后面逐步集成进来。
MR运行结果存入DFS或者灌入MySQL都试验成功,回头整理。
Yarn的资源队列临时配置了一个,现在只是能跑,还不明白咋回事,抽时间继续研究。
在4个data node节点上(昨晚才凑到9节点)对15G日志跑一个过滤useragent的MR,需要8分钟,这样算下来需要1天时间才能对1个月的日志解析完,孰能忍!性能优化需要陆续展开。
到此,关于“hadoop2.7.1环境的搭建方法”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





