本篇内容介绍了“hbase存储结构是怎样的”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
HBase 是一个高可靠、高性能、面向列、可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建 大规模结构化存储集群。
HBase 是Google Bigtable 的开源实现,与Google Bigtable 利用GFS作为其文件存储系统类似, HBase 利用Hadoop HDFS 作为其文件存储系统;Google 运行MapReduce 来处理Bigtable中的海量数据, HBase 同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable 利用Chubby作为协同服务, HBase 利用Zookeeper作为对应。
HBase 中的表一般有以下特点。
1)大:一个表可以有上亿行,上百万列。
2)面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
3)稀疏:对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
HBase 支持很多种访问,访问HBase的常见接口如下。
1、Native Java API,最常规和高效的访问方式,适合Hadoop MapReduce Job并行批处理HBase表数据。
2、HBase Shell,HBase的命令行工具,最简单的接口,适合HBase管理使用。
3、Thrift Gateway,利用Thrift序列化技术,支持C++,PHP,Python等多种语言,适合其他异构系统在线访问HBase表数据。
4、REST Gateway,支持REST 风格的Http API访问HBase, 解除了语言限制。
5、Pig,可以使用Pig Latin流式编程语言来操作HBase中的数据,和Hive类似,本质最终也是编译成MapReduce Job来处理HBase表数据,适合做数据统计。
6、Hive,当前Hive的Release版本尚没有加入对HBase的支持,但在下一个版本Hive 0.7.0中将会支持HBase,可以使用类似SQL语言来访问HBase。
从HBase的架构图上可以看出,HBase中的存储包括HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog等,本课程统一介绍他们的作用即存储结构。 以下是 HBase 存储架构图:
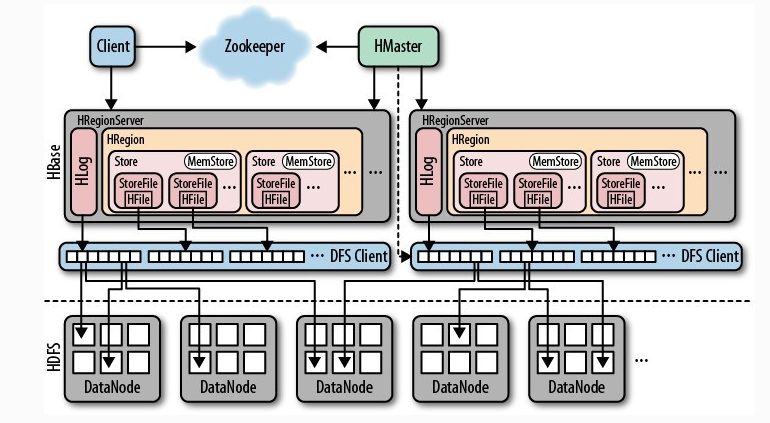
HBase中的每张表都通过行键按照一定的范围被分割成多个子表(HRegion),默认一个HRegion超过256M就要被分割成两个,这个过程由HRegionServer管理,而HRegion的分配由HMaster管理。
HMaster的作用:
1、 为Region server分配region。
2、 负责Region server的负载均衡。
3、发现失效的Region server并重新分配其上的region。
4、 HDFS上的垃圾文件回收。
5、 处理schema更新请求。
HRegionServer作用:
1、 维护master分配给他的region,处理对这些region的io请求。
2、 负责切分正在运行过程中变的过大的region。
可以看到,client访问hbase上的数据并不需要master参与(寻址访问zookeeper和region server,数据读写访问region server),master仅仅维护table和region的元数据信息(table的元数据信息保存在zookeeper上),负载很低。 HRegionServer存取一个子表时,会创建一个HRegion对象,然后对表的每个列族创建一个Store实例,每个Store都会有一个MemStore和0个或多个StoreFile与之对应,每个StoreFile都会对应一个HFile, HFile就是实际的存储文件。因此,一个HRegion有多少个列族就有多少个Store。 一个HRegionServer会有多个HRegion和一个HLog。
table在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。
Region按大小分隔,每个表一开始只有一个region。随着数据不断插入表,region不断增大,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region。
每个region由以下信息标识:
1、< 表名,startRowkey,创建时间>
2、由目录表(-ROOT-和.META.)记录该region的endRowkey
HRegion定位:Region被分配给哪个Region Server是完全动态的,所以需要机制来定位Region具体在哪个region server。
HBase使用三层结构来定位region:
1、 通过zk里的文件/hbase/rs得到-ROOT-表的位置。-ROOT-表只有一个region。
2、通过-ROOT-表查找所请求行在.META.表中相应的region的位置。.META.表中的每一个region在-ROOT-表中都是一行记录。
3、通过.META.表找到所要的用户表region的位置。用户表中的每个region在.META.表中都是一行记录。
-ROOT-表永远不会被分隔为多个region,保证了最多需要三次跳转,就能定位到任意的region。client会将查询的位置信息保存缓存起来,缓存不会主动失效,客户端碰到错误之前会一直使用所缓存的项。当发生错误时-----即区域被移动了,客户端会再取查看.META.获取区域新位置,.META.区域也别移动了,客户端会再去查看-ROOT-。因此如果client上的缓存全部失效,则需要进行6次网络来回,才能定位到正确的region,其中三次用来发现缓存失效,另外三次用来获取位置信息。
每一个region由一个或多个store组成,至少是一个store,hbase会把一起访问的数据放在一个store里面,即为每个ColumnFamily建一个store,如果有几个ColumnFamily,也就有几个Store。一个Store由一个memStore和0或者多个StoreFile组成。 HBase以store的大小来判断是否需要切分region。
到达Regionserve的写操作首先被追加到提交日志(commit log),然后被加入内存中的memStore 。当memStore的大小达到一个阀值(默认64MB)时,memStore会被flush到文件,即生成一个快照。目前hbase 会有一个线程来负责memStore的flush操作。
memStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。
HBase中KeyValue数据的存储格式,是hadoop的二进制格式文件。 首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。Trailer中有指针指向其他数据块的起始点,FileInfo记录了文件的一些meta信息。 Data Block是hbase io的基本单元,为了提高效率,HRegionServer中有基于LRU的block cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定(默认块大小64KB),大号的Block有利于顺序Scan,小号的Block利于随机查询。每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成,Magic内容就是一些随机数字,目的是防止数据损坏,结构如下。
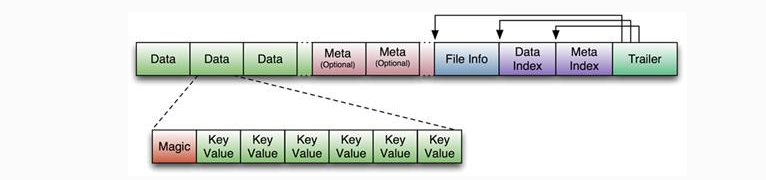
Data Block段用来保存表中的数据,这部分可以被压缩。 Meta Block段(可选的)用来保存用户自定义的kv段,可以被压缩。 FileInfo段用来保存HFile的元信息,不能被压缩,用户也可以在这一部分添加自己的元信息。 Data Block Index段(可选的)用来保存Meta Blcok的索引。 Trailer这一段是定长的。保存了每一段的偏移量,读取一个HFile时,会首先读取Trailer,Trailer保存了每个段的起始位置(段的Magic Number用来做安全check),然后,DataBlock Index会被读取到内存中,这样,当检索某个key时,不需要扫描整个HFile,而只需从内存中找到key所在的block,通过一次磁盘io将整个 block读取到内存中,再找到需要的key。DataBlock Index采用LRU机制淘汰。 HFile的Data Block,Meta Block通常采用压缩方式存储,压缩之后可以大大减少网络IO和磁盘IO,随之而来的开销当然是需要花费cpu进行压缩和解压缩。目标HFile的压缩支持两种方式:gzip、lzo。
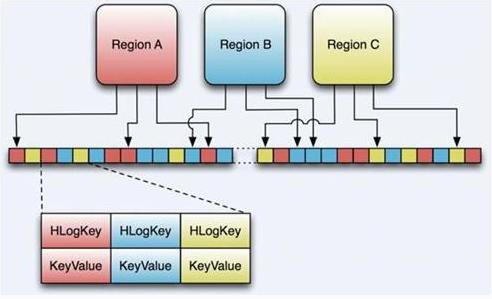
HLog(WAL log):WAL意为write ahead log,用来做灾难恢复使用,HLog记录数据的所有变更,一旦region server 宕机,就可以从log中进行恢复。
前面提到,数据以KeyValue形式到达HRegionServer,将写入WAL之后,写入一个SequenceFile。看过去没问题,但是因为数据流在写入文件系统时,经常会缓存以提高性能。这样,有些本以为在日志文件中的数据实际在内存中。这里,我们提供了一个LogFlusher的类。它调用HLog.optionalSync(),后者根据 hbase.regionserver.optionallogflushinterval (默认是10秒),定期调用Hlog.sync()。另外,HLog.doWrite()也会根据 hbase.regionserver.flushlogentries (默认100秒)定期调用Hlog.sync()。Sync() 本身调用HLog.Writer.sync(),它由SequenceFileLogWriter实现。
Log的大小通过$HBASE_HOME/conf/hbase-site.xml 的 hbase.regionserver.logroll.period 限制,默认是一个小时。所以每60分钟,会打开一个新的log文件。久而久之,会有一大堆的文件需要维护。首先,LogRoller调用HLog.rollWriter(),定时滚动日志,之后,利用HLog.cleanOldLogs()可以清除旧的日志。它首先取得存储文件中的最大的sequence number,之后检查是否存在一个log所有的条目的“sequence number”均低于这个值,如果存在,将删除这个log。 每个region server维护一个HLog,而不是每一个region一个,这样不同region(来自不同的table)的日志会混在一起,这样做的目的是不断追加单个文件相对于同时写多个文件而言,可以减少磁盘寻址次数,因此可以提高table的写性能。带来麻烦的时,如果一个region server下线,为了恢复其上的region,需要将region server上的log进行拆分,然后分发到其他region server上进行恢复。
“hbase存储结构是怎样的”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





