这期内容当中小编将会给大家带来有关hadoop的运行原理是怎么样的,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
hadoop主要由三方面组成:
1、HDFS
2、MapReduce
3、Hbase
Hadoop框架中最核心的设计就是:MapReduce和HDFS。MapReduce的思想是由Google的一篇论文所提及而被广为流传的, 简单的一句话解释MapReduce就是“任务的分解与结果的汇总”。HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写 ,为分布式计算存储提供了底层支持。
MapReduce从它名字上来看就大致可以看出个缘由,两个动词Map和Reduce,“Map(展开)”就是将一个任务分解成为多个任 务,“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。这不是什么新思想,其实在前面提到的多线程,多任务的设计就可以找到这 种思想的影子。不论是现实社会,还是在程序设计中,一项工作往往可以被拆分成为多个任务,任务之间的关系可以分为两种:一种是不相关的任务,可以并行执 行;另一种是任务之间有相互的依赖,先后顺序不能够颠倒,这类任务是无法并行处理的。回到大学时期,教授上课时让大家去分析关键路径,无非就是找最省时的 任务分解执行方式。在分布式系统中,机器集群就可以看作硬件资源池,将并行的任务拆分,然后交由每一个空闲机器资源去处理,能够极大地提高计算效率,同时 这种资源无关性,对于计算集群的扩展无疑提供了最好的设计保证。(其实我一直认为Hadoop的卡通图标不应该是一个小象,应该是蚂蚁,分布式计算就好比 蚂蚁吃大象,廉价的机器群可以匹敌任何高性能的计算机,纵向扩展的曲线始终敌不过横向扩展的斜线)。任务分解处理以后,那就需要将处理以后的结果再汇总起 来,这就是Reduce要做的工作。
下面这个图很经典:
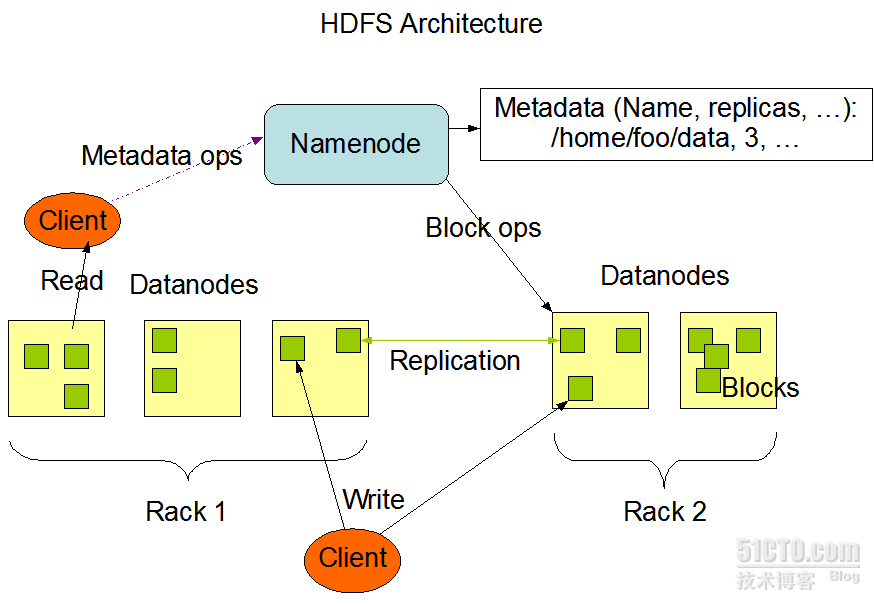
上图中展现了整个HDFS三个重要角色:NameNode、DataNode和 Client。NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode 会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。 DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的 Block信息发送给NameNode。Client就是需要获取分布式文件系统文件的应用程序。这里通过三个操作来说明他们之间的交互关系。
文件写入:
a):Client向NameNode发起文件写入的请求。
b):NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
c):Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
文件读取:
a):Client向NameNode发起文件读取的请求。
b):NameNode返回文件存储的DataNode的信息。
c):Client读取文件信息。
文件Block复制:
a):NameNode发现部分文件的Block不符合最小复制数或者部分DataNode失效。
b):通知DataNode相互复制Block。
c):DataNode开始直接相互复制.
下面综合MapReduce和HDFS来看Hadoop的结构:
Hadoop结构示意图
在Hadoop的系统中,会有一台Master,主要负责NameNode的工作以及JobTracker的工作。JobTracker的主要职责 就是启动、跟踪和调度各个Slave的任务执行。还会有多台Slave,每一台Slave通常具有DataNode的功能并负责TaskTracker的 工作。TaskTracker根据应用要求来结合本地数据执行Map任务以及Reduce任务。
把自己平时工作当中的代码贴出来解释下可能会更好的理解:
FileInputFormat.setInputPaths(tempJob, hdfsHome); // 把本地的文件读入到HDFS中
LOG.info(tempJobName + " data start .....");
tempJob.setJarByClass(tempMain.class); //设置这个Job运行是那个类
tempJob.setMapperClass(MultithreadedMapper.class); //设置这个job运行的map,这里面使用了本身map自带的多线程实 现机制,这一点很重要,可以帮助我们提高运行的效率。
MultithreadedMapper.setMapperClass(tempJob,tempMapper.class); //设置这个job运行的map
MultithreadedMapper.setNumberOfThreads(tempJob, Integer.parseInt(tempThread));//设置多线程运行几个线程
tempJob.setMapOutputKeyClass(LongWritable.class);// 设置map所输出的key
tempJob.setMapOutputValueClass(StringArrayWritable.class); // 设置map所输出的value
...... //下面还有reduce的一些,我这里的业务没有涉及到,这里就不列出来了。
long start = System.currentTimeMillis();
boolean result = tempJob.waitForCompletion(true); //启动一个job运行
long end = System.currentTimeMillis();
上述就是小编为大家分享的hadoop的运行原理是怎么样的了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





