本篇内容介绍了“RDD怎么向spark传递函数”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
RDD的转换操作都是惰性求值的。
惰性求值意味着我们对RDD调用转化操做(例如map操作)并不会立即执行,相反spark会在内部记录下所要求执行的操作的相关信息。
把数据读取到RDD的操作同样也是惰性的,因此我们调用sc.textFile()时数据没有立即读取进来,而是有必要时才会读取。和转化操作一样读取数据操作也有可能被多次执行。这在写代码时要特别注意。
关于惰性求值,对新手来说可能有与直觉相违背之处。有接触过函数式语言类如haskell的应该不会陌生。
在最初接触spark时,我们也会有这样的疑问。
也参与过这样的讨论:
val sc = new SparkContext("local[2]", "test")
val f:Int ⇒ Int = (x:Int) ⇒ x + 1
val g:Int ⇒ Int = (x:Int) ⇒ x + 1
val rdd = sc.parallelize(Seq(1,2,3,4),1)
//1
val res1 = rdd.map(x ⇒ g(f(x))).collect
//2
val res2 = rdd.map(g).map(f).collect第1和第2两种操作均能得到我们想要的结果,但那种操作更好呢?
直观上我们会觉得第1种操作更好,因为第一种操作可以仅仅需要一次迭代就能得到我们想要的结果。第二种操作需要两次迭代操作才能完成。
是我们想象的这样吗?让我们对函数f和g的调用加上打印。按照上面的假设。1和2的输出分别是这样的:
1: f g f g f g f g 2: g g g g f f f f
代码:
val sc = new SparkContext("local[2]", "test")
val f:Int ⇒ Int = (x:Int) ⇒ {
print("f\t")
x + 1
}
val g:Int ⇒ Int = (x:Int) ⇒ {
print("g\t")
x + 1
}
val rdd = sc.parallelize(Seq(1,2,3,4), 1
//1
val res1 = rdd.map(x ⇒ g(f(x))).collect()
//2
val res2 = rdd.map(f).map(g).collect()将上面的代码copy试着运行一下吧,我们在控制台得到的结果是这样的。
f g f g f g f g f g f g f g f g
是不是大大出乎我们的意料?这说明什么?说明spark是懒性求值的! 我们在调用map(f)时并不会真正去计算, map(f)只是告诉spark数据是怎么计算出来的。map(f).map(g)其实就是在告诉spark数据先通过f在通过g计算出来的。然后在collect()时,spark在一次迭代中先后对数据调用f、g。
继续回到我们最初的问题,既然两种调用方式,在性能上毫无差异,那种调用方式更好呢?我们更推荐第二种调用方式,除了api更加清晰之外。在调用链很长的情况下,我们可以利用spark的检查点机制,在中间添加检查点,这样数据恢复的代价更小。而第一种方式调用链一旦出错,数据只能从头计算。
那么spark到底施加了何种魔法,如此神奇?让我们来拨开spark的层层面纱。最好的方式当然是看源码了。以map为例:
RDD的map方法
/**
* Return a new RDD by applying a function to all elements of this RDD.
*/
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}和MapPartitionsRDD的compute方法
override def compute(split: Partition, context: TaskContext): Iterator[U] = f(context, split.index, firstParent[T].iterator(split, context))
关键是这个 iter.map(cleanF)),我们调用一个map方法其实是在iter对象上调用一个map方法。iter对象是scala.collection.Iterator的一个实例。
在看一下Iterator的map方法
def map[B](f: A => B): Iterator[B]=
new AbstractIterator[B] {
def hasNext = self.hasNext
def next() = f(self.next())
}联想到我们刚才说的我们在RDD上调用一个map方法只是告诉spark数据是怎么计算出来的,并不会真正计算。是不是恍然大悟了。
我们可以把定义好的内联函数、方法的引用或静态方法传递给spark。就像scala的其它函数式API一样。我们还要考虑一些细节,比如传递的函数及其引用的变量是可序列话的(实现了java的Serializable接口)。除此之外传递一个对象的方法或字段时,会包含对整个对象的引用。我们可以把该字段放到一个局部变量中,来避免传递包含该字段的整个对象。
scala中的函数传递
class SearchFunctions(val query:String){
def isMatch(s:String) = s.contains(query)
def getMatchFuncRef(rdd:RDD[String])
:RDD[String]= {
//isMatch 代表this.isMatch因此我们要传递整个this
rdd.map(isMatch)
}
def getMatchFieldRef(rdd:RDD[String])={
//query表示this.query因此我们要传递整个this
rdd.map(x=>x.split(query))
}
def getMatchsNoRef(rdd:RDD[String])={
//安全只要把我们需要的字段放到局部变量中
val q = this.query
rdd.map(x=>x.split(query))
}
}如果在scala中出现了NotSerializableException,通常问题就在我们传递了一个不可序列化类中的函数或字段。传递局部可序列变量或顶级对象中的函数始终是安全的。
如前所述,spark的RDD是惰性求值的,有时我们希望能过多次使用同一个RDD。如果只是简单的对RDD调用行动操作,spark每次都会重算RDD和它的依赖。这在迭代算法中消耗巨大。 可以使用RDD.persist()让spark把RDD缓存下来。
让我们来看看两种workCount的方式,一种使用reduceByKey,另一种使用groupByKey。
val words = Array("one", "two", "two", "three", "three", "three")
val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
val wordCountsWithReduce = wordPairsRDD
.reduceByKey(_ + _)
.collect()
val wordCountsWithGroup = wordPairsRDD
.groupByKey()
.map(t => (t._1, t._2.sum))
.collect()虽然两种方式都能产生正确的结果,但reduceByKey在大数据集时工作的更好。这时因为spark会在shuffling数据之前,为每一个分区添加一个combine操作。这将大大减少shuffling前的数据。
看下图来理解 reduceBykey的过程
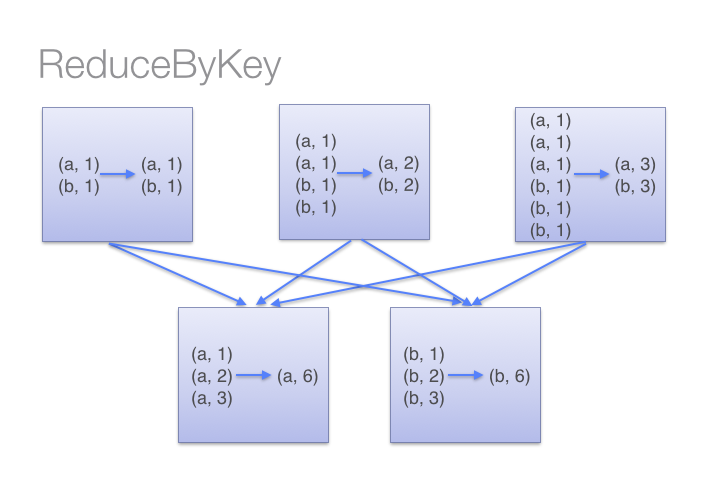
而groupBykey会shuff所有的数据,这大大加重了网络传输的数据量。另外如果一个key对应很多value,这样也可能引起out of memory。
如图,groupby的过程
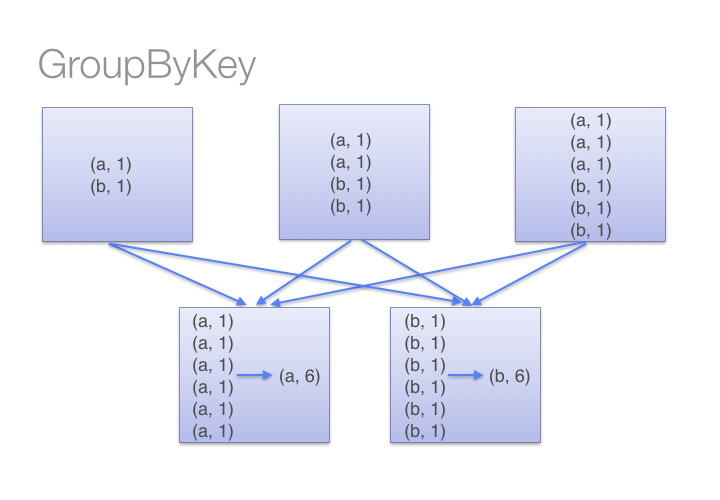
“RDD怎么向spark传递函数”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





