本篇文章为大家展示了如何实现zookeepr分析,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
zk 一个分布式应用协调服务
zk是一个分布式,开源的,分布式协调服务,他提供了一组简单的原生接口,分布式应用可以基于它实现,高水准的同步,集群,配置管理和命名服务。它基于开发,使用简单的原则而设计。使用类似于文件系统目录树结构的数据模型。它基于java实现,可以为c和java应用服务。
协调是个臭名昭著的活儿。很容易产生资源竞争和死锁的问题。zk的实现动机就是缓解分布式应用在解决彼此斜体问题而产生的抓狂行为。
zk的设计目标
zk 是个简单的玩意儿。zk通过分布式的处理流程来协调应用彼此,它是使用的是一种类似文件系统的分层名字空间。这些名字空间里,包含了数据的注册者,用zk的叫法,称之为znodes.它类似于文件和目录。不像传统的文件系统,是用来存储的,zk的数据都在内存中,所以意味着,zk的高吞吐量和底延时。zk 实现了一个优质的,高新能,高可用,严格访问顺序的服务。从zk的表现来看,它完全可以使用,大型,分布式系统。在可用上,也使它不会碰到单点故障的问题,严格的顺序性,也意味着可以在客户单实现非常复杂的同步操作。
zk 是可复制的。像它协调的应用一样,zk自身也复制到一系列主机上。他们是一个整体。如图 zk server
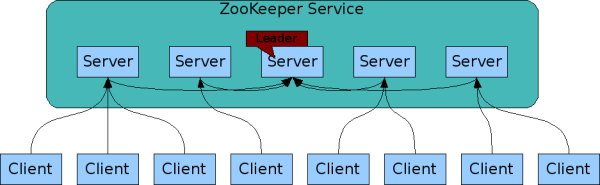
所有组成zk server的 severs 必须彼此能感知对方。他们在内存里维护一个所有机器的状态图,在磁盘里保存有实务日志和快照。只要大多数服务器可用。zk服务就可用。
客户端连接到单一的服务器,通过tcp协议,发送请求,获得反馈,获得监听事件,发送心跳包。如果连接的服务器挂掉,客户端会连接其他的服务机器。
zk 是顺序的。zk的每次更新都会用一个数字做标签,这个数字,代表了全部的zk事务顺序,接下来的操作用这个顺序来实现高水平的抽象,比如同步操作。
zk 是快速的。zk 在读为主的操作中,显得特别的快。zk 运行在上千台机器上,当读操作为主的请求中,表现会更好。读写比为10:1。
数据模型和命名层次
zk 提供的命名空间像一个标准的文件系统。一个名字,就是它的路径以(/)分隔的组合,在zk中每个节点,都已路径来唯一标识。zk的层次命名结构如图
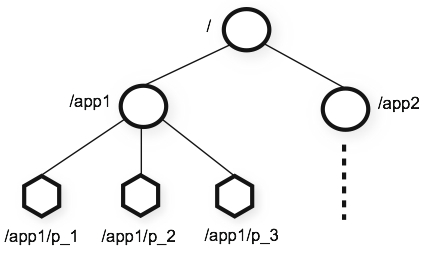
Nodes 和短命的nodes
不像传统的文件系统,在zk里每个node和它的孩子node,都有数据和他们关联。他们像个这样一个文件系统,即每个文件也是目录。(zk节点里存储的数据,包括状态信息,配置,本地信息等,所以数据量都不大通常只有几字节或者几千字节),为了说清楚zk node.我们把它称作znode,znode 维护这一个数据结构,包括状态更改的版本号,acl 更改的信息和时间戳去用和套东西区验证和协调的更新。如果以个node的数据发生变化,它的版本号也会变化。比如一个客户端读取一个node数据,也会得到它的版本号。存储在node里的数据读写都是原子的。读会读所有关联的数据,写也会替换所有的数据,不会半途而废。每个节点都有个访问控制列表(acl),严格限制谁能干什么!
zk里还有个短命node的概念。这些node和创建这个节点的session生命一样长。当这个session关闭时,这个node也就自动删除了。短命node在你开发实现 【tbd】是很重要。
有条件的更新和监控
zk 支持监控的概念,客户端可以对一个节点进行监控,当这个节点发生变化时,监控被触发同时被删除,当监控被触发,客户端收到一个数据更改的数据包。还有当客户端和服务端连接断开,客户端也会收到一个通知。这个在【tbd】中很有用。
保证
zk 简单快速,就像他的开始的目标一样,是构造复杂系统的基础,比如,同步系统。实际上它有一下保证:
时序一致性:更新操作会以客户端发送的顺序被执行。
原子性:更新要么失败,要么成功没有部分成功的状态。
状态图统一:一个客户端无论它连接到哪个机器,所有机器图谱一致。
可靠性:一个更新被应用,就会一直有效,直到有新的数据覆盖。
时间线:客户端某个时间段内看到的系统状态图,保证是最新的。
更多这些方面的应用,可以参看【tbd】
简单的api
zk设计之初就是提供简单的程序接口,所以,它仅仅支持一下操作:
create :在节点树上,创建一个节点
delete:删除一个节点
exists:检查一个节点是否存在
get data:从一个节点获取数据
set data:向一个节点写数据
get children:获取一个节点的孩子节点
sync:等待数据传播同步
关于这方面的更深的技术讨论,和在构建高水平应用方面的实践,可以参考【tbd】
技术实现
下面是zk 服务组件图,处理请求处理器外,每个zk组件都有复制的多份。
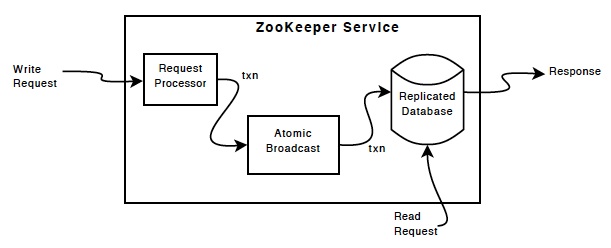
每个机器上的内存数据库,都包含整个数据,更新日志记录到磁盘,写操作被序列化到磁盘在它扩散同步到其他内存数据库之前。
每个zk 主机都对外提供服务,客户端连接某一个主机请求服务。读的服务从客户连接的机器本身内存里获取,写服务和改变服务状态的请求通过一个一致的协议处理。
这个一致的协议要求,所有写请求都统一发送到一个叫leader的主机。剩下的被称作followers的zk主机,通过leader 接收数据消息,消息层负责leaders的失败替换和leaders和followers之间的同步。
zk使用的是原子性的消息协议,因为消息是原子性的,所以能保证本地的信息与其他主机信息是一致没有分歧的。当leader收到一个写请求后,它会评估服务器状态,决定什么时候写,然后启动写事务,最后获取服务请的新状态。
应用
zk的使用接口尤其的简单,你可以通过他实现,顺序操作,比如同步,群组管理等,许多分布式应有使用它,想了解更多,关注【tbd】。
表现
zk被设计成高可用,是不是这样呢?在yahoo的开发组的调查说明了它是的。当读远大于写操作的时候,它表现的尤其的高性能,因为写操作要同步所有的服务器状态。(读远大于写是经典的协调服务案例),下图是zk读写比率变化的测试结果图表
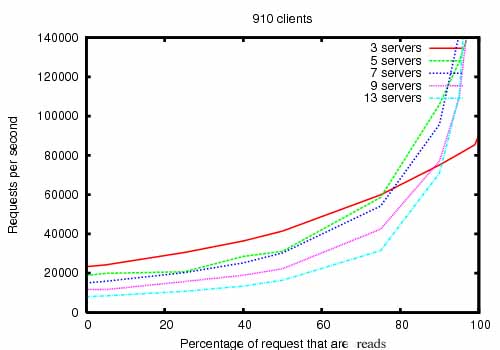
这个图表的测试数据是,3.2版本的zk 运行在双核2Ghz Xeon处理器和两个15k转速的sata设备上的测试数据,一个磁盘专门做zk日志,一个写写数据快照,读写操作都是1k大小,servers 表示zk服务,组成主机数目,接近30个其他主机模拟客户机,zk服务被配置成,leader不允许从客户端连接。另外说明下,3.2读写性能是3.1版本的两倍。
测试结果也说明了zk的可靠性,下图显示了在各种错误下服务器的表现,这些错误包含以下几种:
1,follower 机器的当掉和恢复。
2,另外一个follower的当掉和恢复。
3,leader的当掉。
4,两个follower同时当掉。
5,另外一个leader的当掉。
可用性
这个图里显示了,我们有7个主机组成的zk服务器,在一段时间内我们注入错误的系统表现。这次测试我们和以前跑同样的访问饱和度,有一点们把写的比率维持在30%,这也是我们比较保守负载比例。
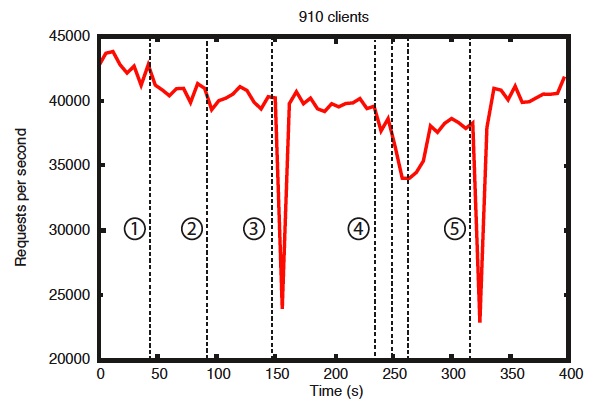
从张图里,可以看出一下重要的几点,当followers 挂掉并很快恢复是,zk能保持很高的吞吐量。更重要是,leader选举算法能让系统很快恢复,以保持它的高吞吐量。可以看到zk花了不到200ms选举新的leader.第三点,当follower恢复处理能力是,zk的吞吐量又开始维持在高水平。
zookeepr 项目
zk 已经成功的在多个工业系统中应用。比如在yahoo.它负责协调yahoo的失败恢复。上千个主题订阅高扩展的信使服务,和数据传输。yahoo的获取服务,crawler,也负责它的失败恢复协调。作为yahoo的一员,广告也是通过zk实现高可用性。
上述内容就是如何实现zookeepr分析,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/146130/blog/608079



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



