这篇文章将为大家详细讲解有关Hadoop2.6.0上的spark1.5.2集群如何搭建,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
一、Spark安装前提
安装Spark之前需要先安装Hadoop集群,因为之前已经安装了hadoop,所以我直接在之前的hadoop集群上安装spark,但是因为机器内存不够,我只选择master以及slave01安装spark集群,而不要slave02了。
二、Spark安装步骤:
1.下载scala-2.11.7.tgz
http://www.scala-lang.org/download/2.11.7.html
2.下载spark-1.5.2-bin-hadoop2.6.tgz(之前安装的hadoop是2.6.0的)
http://www.apache.org/dyn/closer.lua/spark/spark-1.5.2/spark-1.5.2-bin-hadoop2.6.tgz
3.安装Scala(在master上):
mkdir /application/scala
cp /root/scala-2.11.7.tgz /application/scala/
cd /application/scala/
tar -zxvf scala-2.11.7.tgz
创建软链接:
ln -s /application/scala/scala-2.11.7 /application/scala/scala
修改环境变量,添加SCALA_HOME,并修改PATH即可:
vi /etc/profile.d/java.sh
export SCALA_HOME=/application/scala/scala-2.11.7
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$SCALA_HOME/bin:$PATH
使配置立即生效:
source /etc/profile
验证是否安装成功
scala –version
显示如下:

4.将/application/scala从master复制到另外一台机器slave01上。
scp -r /application/scala root@slave01:/application/
5.将/etc/profile.d/java.sh 也复制到slave01上。
再在slave01上进行以下命令操作,使配置生效:
source /etc/profile
6.安装Spark(在master上):
mkdir /application/spark
cp /root/spark-1.5.2-bin-hadoop2.6.tgz /application/spark/
tar -zxvf spark-1.5.2-bin-hadoop2.6.tgz
修改环境变量:将SPARK_HOME添加进去,并修改PATH即可。
vi /etc/profile.d/java.sh
export SPARK_HOME=/application/spark/spark-1.5.2-bin-hadoop2.6
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$PATH
是配置立即生效:
source /etc/profile
7.修改配置文件
7.1修改spark-env.sh配置文件:
cd /application/spark/spark-1.5.2-bin-hadoop2.6/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
在后面追加
###jdk dir
export JAVA_HOME=/usr/local/jdk
###scala dir
export SCALA_HOME=/application/scala/scala
###the ip of master node of spark
export SPARK_MASTER_IP=192.168.10.1
###the max memory size of worker
export SPARK_WORKER_MEMORY=512m
###hadoop configuration file dir
export HADOOP_CONF_DIR=/application/hadoop/hadoop/etc/hadoop7.2修改slaves文件
cp slaves.template slaves
vi slaves
添加如下(可能有默认localhost,将其改成master):
master
slave01
8.将/application/spark以及环境变量的配置文件复制到slave01,并通过source命令将文件立即生效
scp -r /application/spark root@slave01:/application/
scp -r /etc/profile.d/java.sh root@slave01:/etc/profile.d/java.sh
修改所属组和用户
chown -R hadoop:hadoop /application/spark
9.到此Spark集群搭建完毕。
10.启动Spark集群:
启动Spark之前需要先将hadoop的dfs以及yarn启动。
/application/spark/spark-1.5.2-bin-hadoop2.6/sbin/start-all.sh
启动所有服务之后,在命令行输入jps,显示如下:
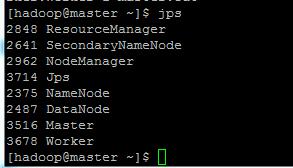
比hadoop集群启动时多了Master和worker
输入如下命令
/application/spark/spark-1.5.2-bin-hadoop2.6/bin/spark-shell.sh
出现scala>时说明成功。
在浏览器中输入192.168.10.1:8080时,会看到如下图,有两个Worker
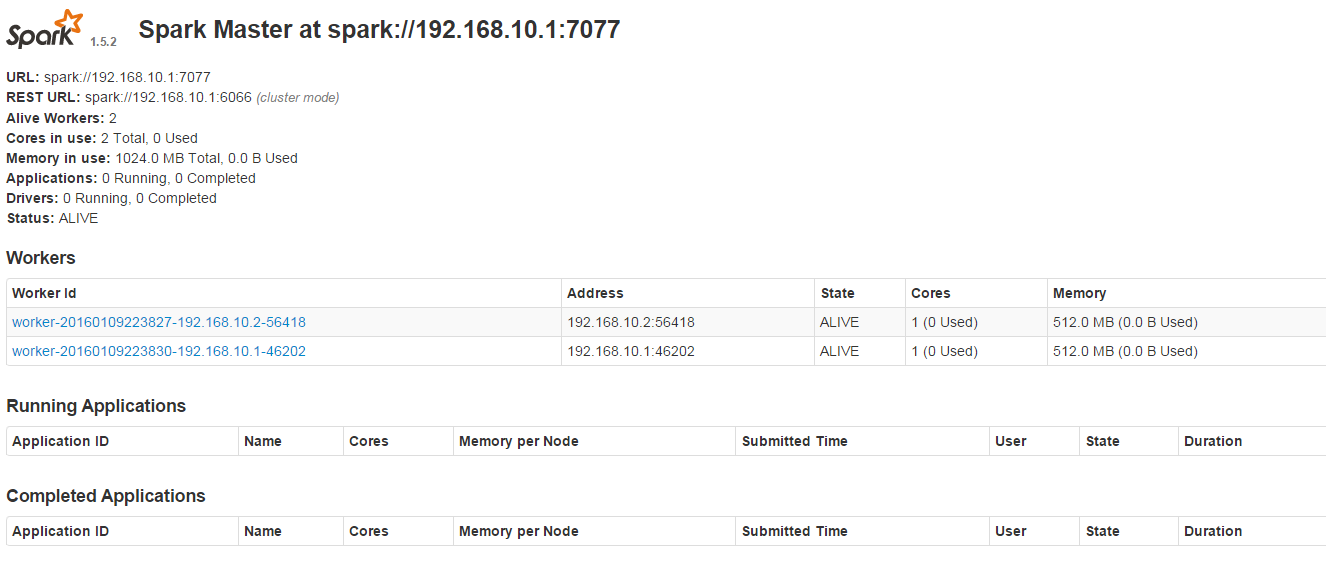
在浏览器中输入192.168.10.1:4040
出现如图:
三、运行实例wordcount实例:
scala>var textcount=sc.textFile("hdfs://master:9000/data/words2").filter(line=>line.contains("haha")).count()
显示结果如下:

关于“Hadoop2.6.0上的spark1.5.2集群如何搭建”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/amui/blog/610329



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



