Spark StreamingжҖҺд№ҲдҪҝз”Ё
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңSpark StreamingжҖҺд№ҲдҪҝз”ЁвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁSpark StreamingжҖҺд№ҲдҪҝз”Ёй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқSpark StreamingжҖҺд№ҲдҪҝз”ЁвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
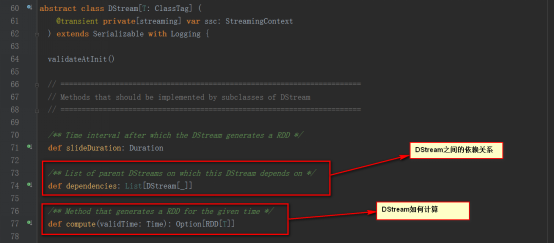
DStreamжҳҜйҖ»иҫ‘зә§еҲ«зҡ„пјҢиҖҢRDDжҳҜзү©зҗҶзә§еҲ«зҡ„гҖӮDStreamжҳҜйҡҸзқҖж—¶й—ҙзҡ„жөҒеҠЁеҶ…йғЁе°ҶйӣҶеҗҲе°ҒиЈ…RDDгҖӮеҜ№DStreamзҡ„ж“ҚдҪңпјҢиҪ¬иҝҮжқҘеҜ№е…¶еҶ…йғЁзҡ„RDDж“ҚдҪңгҖӮ
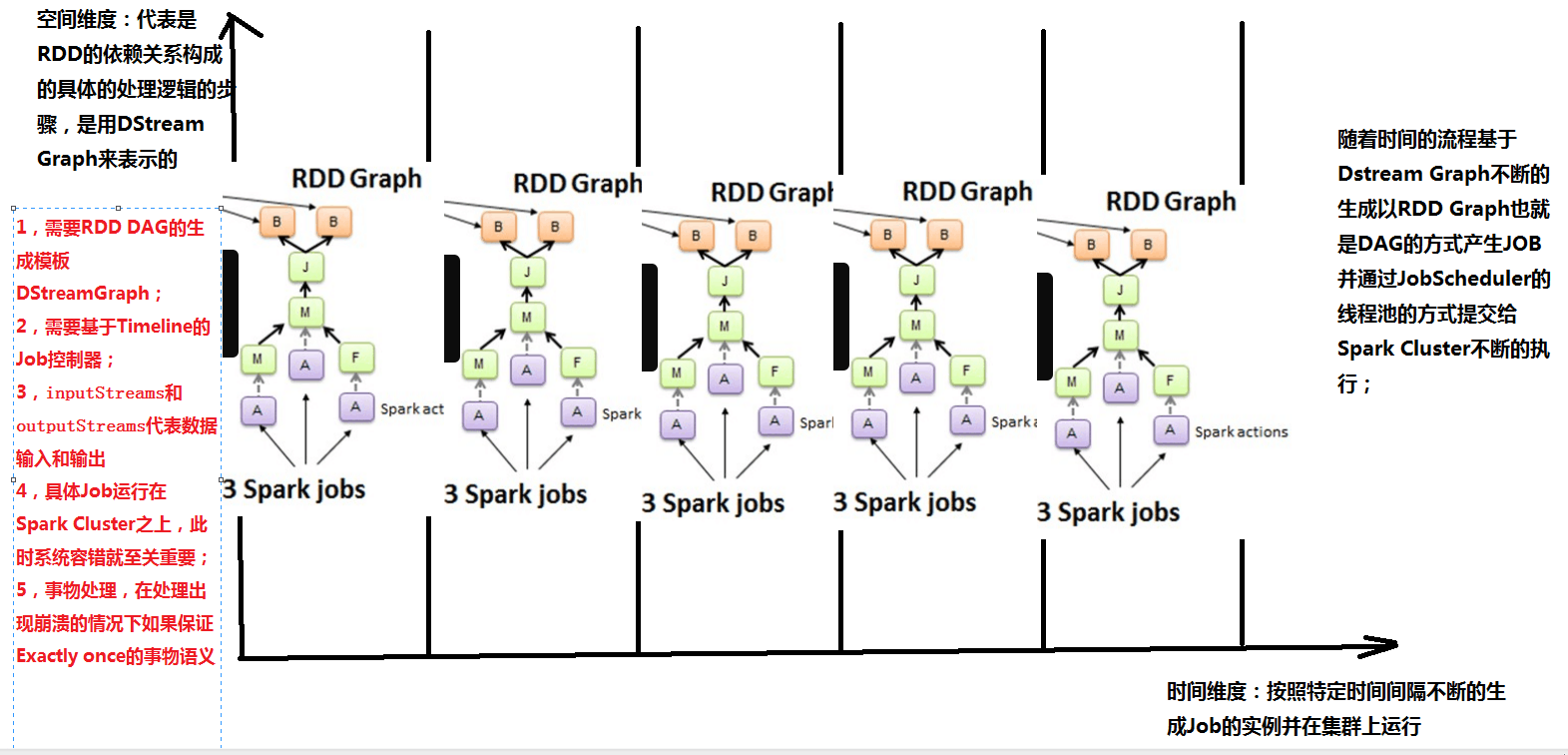
зәөиҪҙдёәз©әй—ҙз»ҙеәҰпјҡд»ЈиЎЁзҡ„жҳҜRDDзҡ„дҫқиө–е…ізі»жһ„жҲҗзҡ„е…·дҪ“зҡ„еӨ„зҗҶйҖ»иҫ‘зҡ„жӯҘйӘӨпјҢжҳҜз”ЁDStreamжқҘиЎЁзӨәзҡ„гҖӮ
жЁӘиҪҙдёәж—¶й—ҙз»ҙеәҰпјҡжҢүз…§зү№е®ҡзҡ„ж—¶й—ҙй—ҙйҡ”дёҚж–ӯең°з”ҹжҲҗjobеҜ№иұЎпјҢ并еңЁйӣҶзҫӨдёҠиҝҗиЎҢгҖӮ
йҡҸзқҖж—¶й—ҙзҡ„жҺЁз§»пјҢеҹәдәҺDStream Graph дёҚж–ӯз”ҹжҲҗRDD Graph ,д№ҹеҚіDAGзҡ„ж–№ејҸз”ҹжҲҗjob,并йҖҡиҝҮJob Schedulerзҡ„зәҝзЁӢжұ зҡ„ж–№ејҸжҸҗдәӨз»ҷspark clusterдёҚж–ӯзҡ„жү§иЎҢгҖӮ
з”ұдёҠеҸҜзҹҘпјҢRDD дёҺ DStreamзҡ„е…ізі»еҰӮдёӢ
RDDжҳҜзү©зҗҶзә§еҲ«зҡ„пјҢиҖҢ DStream жҳҜйҖ»иҫ‘зә§еҲ«зҡ„
DStreamжҳҜRDDзҡ„е°ҒиЈ…зұ»пјҢжҳҜRDDиҝӣдёҖжӯҘзҡ„жҠҪиұЎ
DStream жҳҜRDDзҡ„жЁЎжқҝгҖӮDStreamиҰҒдҫқиө–RDDиҝӣиЎҢе…·дҪ“зҡ„ж•°жҚ®и®Ўз®—
жіЁж„ҸпјҡзәөиҪҙз»ҙеәҰйңҖиҰҒRDD,DAGзҡ„з”ҹжҲҗжЁЎжқҝпјҢйңҖиҰҒTimeLineзҡ„jobжҺ§еҲ¶еҷЁ
жЁӘиҪҙз»ҙеәҰпјҲж—¶й—ҙз»ҙеәҰпјүеҢ…еҗ«batch interval,зӘ—еҸЈй•ҝеәҰпјҢзӘ—еҸЈж»‘еҠЁж—¶й—ҙзӯүгҖӮ
3пјҢSpark Streamingжәҗз Ғи§Јжһҗ
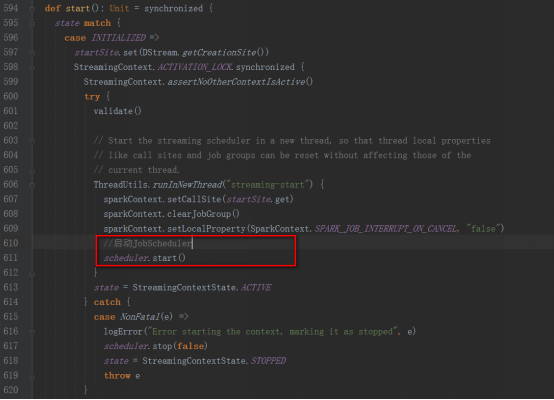
StreamingContextж–№жі•дёӯи°ғз”ЁJobSchedulerзҡ„startж–№жі•
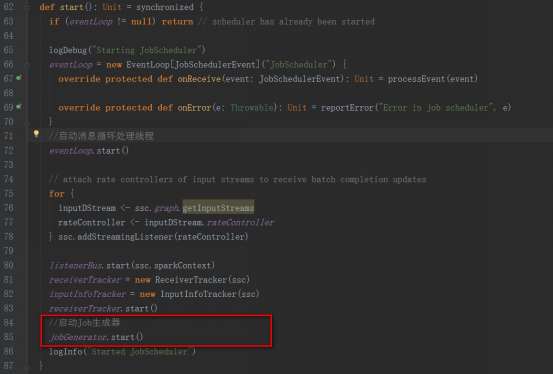
JobGeneratorзҡ„startж–№жі•дёӯпјҢи°ғз”ЁstartFirstTimeж–№жі•пјҢжқҘејҖеҗҜе®ҡж—¶з”ҹжҲҗJobзҡ„е®ҡж—¶еҷЁ
startFirstTimeж–№жі•пјҢйҰ–е…Ҳи°ғз”ЁDStreamGraphзҡ„startж–№жі•пјҢ然еҗҺеҶҚи°ғз”ЁRecurringTimerзҡ„startж–№жі•гҖӮ
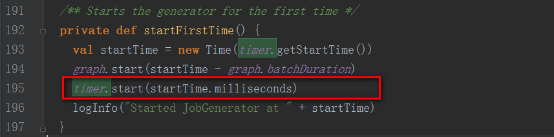
timerеҜ№иұЎдёәдёҖдёӘе®ҡж—¶еҷЁпјҢж №жҚ®batchIntervalж—¶й—ҙй—ҙйҡ”е®ҡжңҹеҗ‘EventLoopеҸ‘йҖҒGenerateJobsзҡ„ж¶ҲжҒҜгҖӮ

жҺҘ收еҲ°GenerateJobsж¶ҲжҒҜеҗҺпјҢдјҡеӣһи°ғgenerateJobsж–№жі•гҖӮ
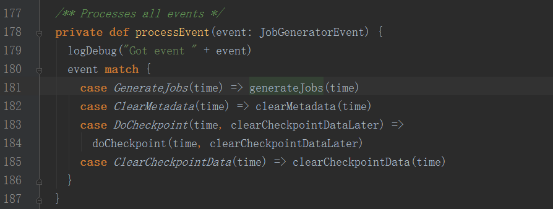
generateJobsж–№жі•еҶҚи°ғз”ЁDStreamGraphзҡ„generateJobsж–№жі•з”ҹжҲҗJob
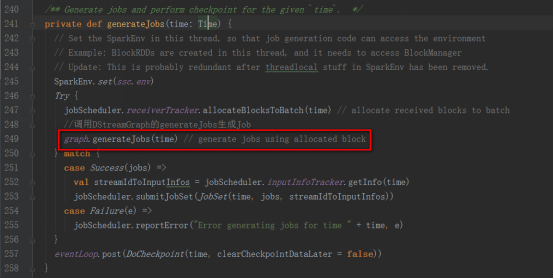
DStreamGraphзҡ„generateJobsж–№жі•
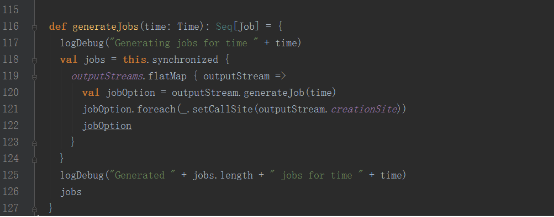
DStreamGraphзҡ„е®һдҫӢеҢ–жҳҜеңЁStreamingContextдёӯзҡ„

DStreamGraphзұ»дёӯдҝқеӯҳдәҶиҫ“е…ҘжөҒе’Ңиҫ“еҮәжөҒдҝЎжҒҜ
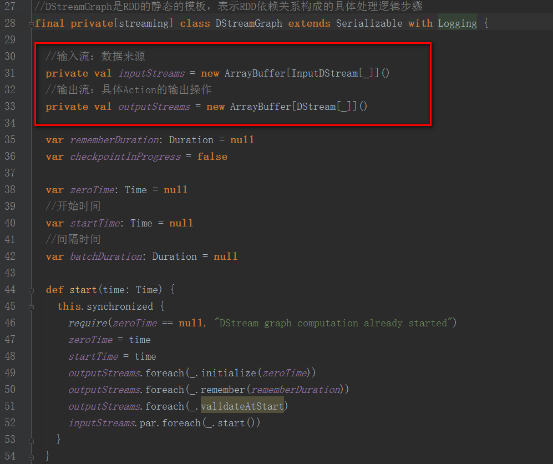
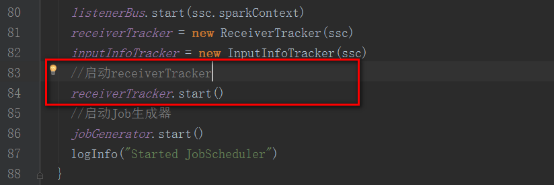
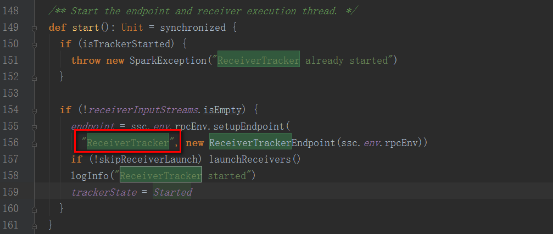
еӣһеҲ°JobGeneratorзҡ„startж–№жі•дёӯreceiverTracker.start()
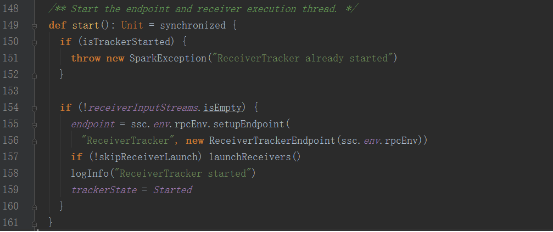
е…¶дёӯReceiverTrackerEndpointеҜ№иұЎдёәдёҖдёӘж¶ҲжҒҜеҫӘзҺҜдҪ“
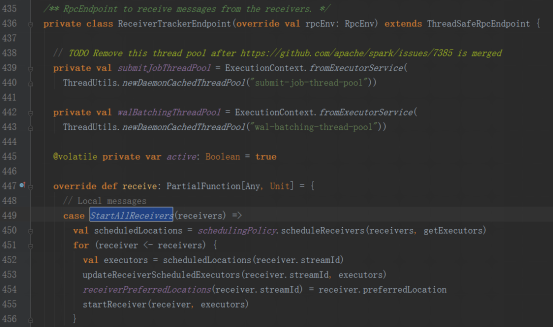
launchReceiversж–№жі•дёӯеҸ‘йҖҒStartAllReceiversж¶ҲжҒҜ
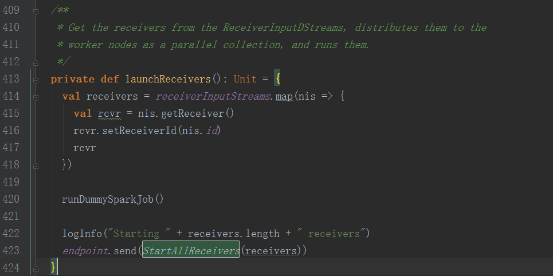
жҺҘ收еҲ°StartAllReceiversж¶ҲжҒҜеҗҺпјҢиҝӣиЎҢеҰӮдёӢеӨ„зҗҶ
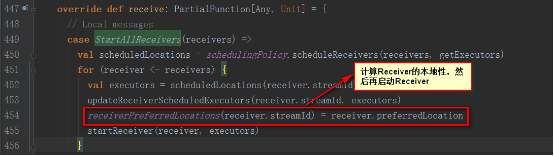
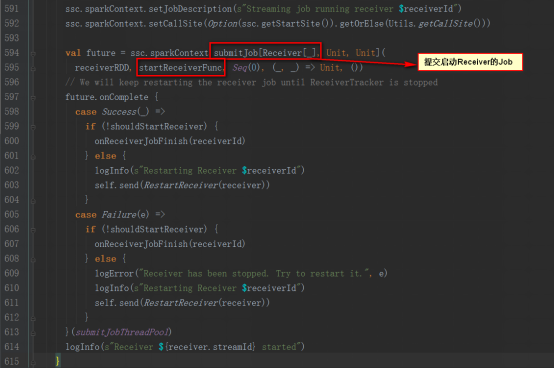
StartReceiverFuncж–№жі•еҰӮдёӢпјҢе®һдҫӢеҢ–Receiverзӣ‘жҺ§иҖ…пјҢејҖеҗҜ并зӯүеҫ…йҖҖеҮә
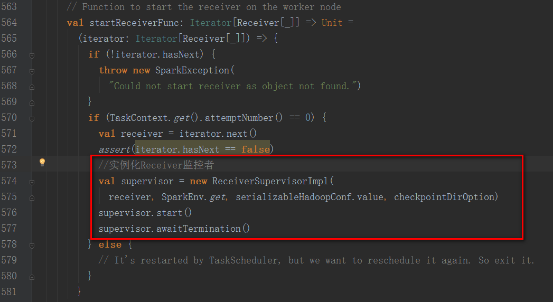
supervisorзҡ„startж–№жі•дёӯи°ғз”ЁstartReceiverж–№жі•

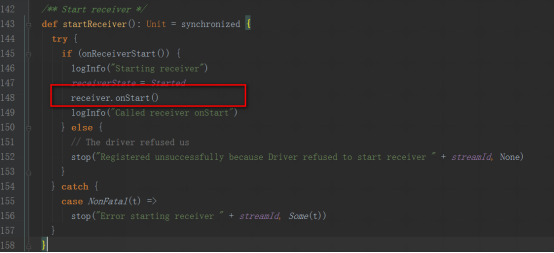
жҲ‘们д»ҘsocketTextStreamдёәдҫӢпјҢе…¶еҗҜеҠЁзҡ„жҳҜSocketReceiverпјҢеҶ…йғЁејҖеҗҜдёҖдёӘзәҝзЁӢпјҢжқҘжҺҘ收数жҚ®гҖӮ
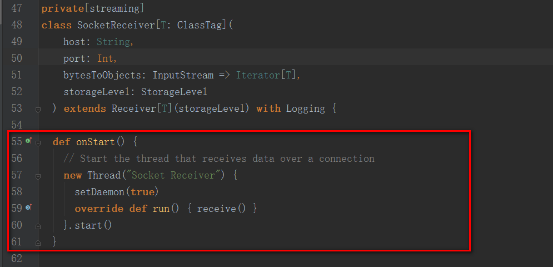
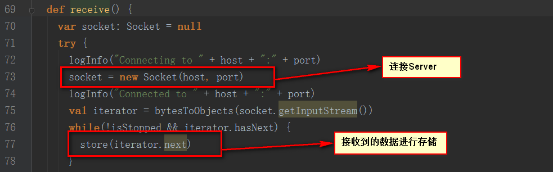
еҶ…йғЁи°ғз”Ёsupervisorзҡ„pushSingleж–№жі•пјҢе°Ҷж•°жҚ®иҒҡйӣҶеҗҺеӯҳж”ҫеңЁеҶ…еӯҳдёӯ
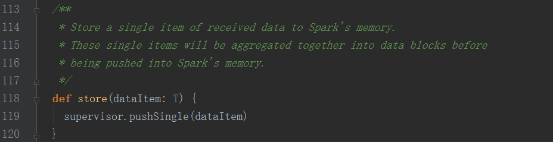
supervisorзҡ„pushSingleж–№жі•еҰӮдёӢпјҢе°Ҷж•°жҚ®ж”ҫе…ҘеҲ°defaultBlockGeneratorдёӯпјҢdefaultBlockGeneratorдёәBlockGeneratorпјҢдҝқеӯҳSocketжҺҘ收еҲ°зҡ„ж•°жҚ®

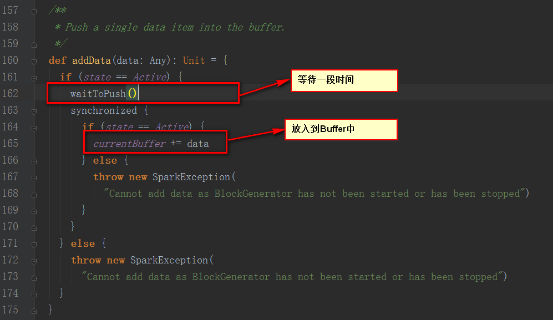
BlockGeneratorеҜ№иұЎдёӯжңүдёҖдёӘе®ҡж—¶еҷЁпјҢжқҘжӣҙж–°еҪ“еүҚзҡ„Buffer


BlockGeneratorеҜ№иұЎдёӯжңүдёҖдёӘзәҝзЁӢпјҢжқҘд»Һйҳ»еЎһйҳҹеҲ—дёӯеҸ–еҮәж•°жҚ®

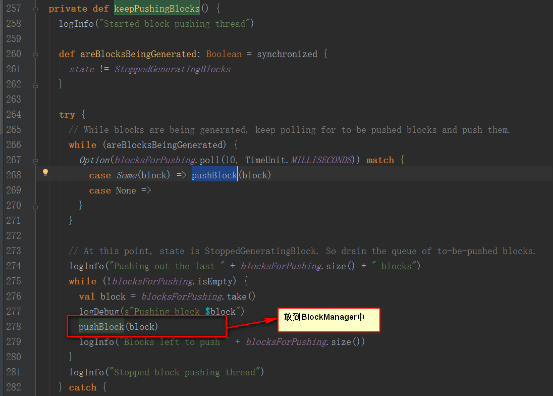

и°ғз”ЁReceiverSupervisorImplзұ»дёӯзҡ„继жүҝBlockGeneratorListenerзҡ„еҢҝеҗҚзұ»дёӯзҡ„onPushBlockж–№жі•гҖӮ
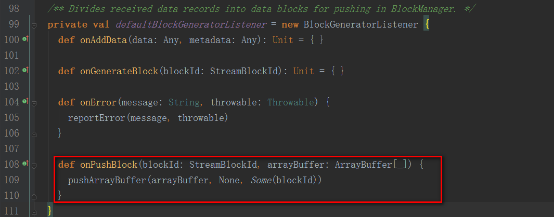
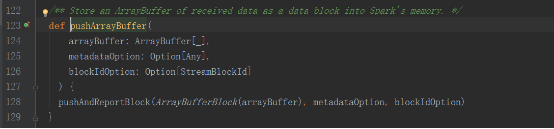
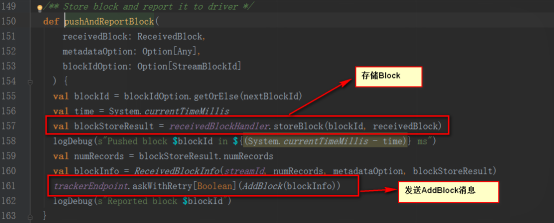
receivedBlockHandlerеҜ№иұЎеҰӮдёӢ
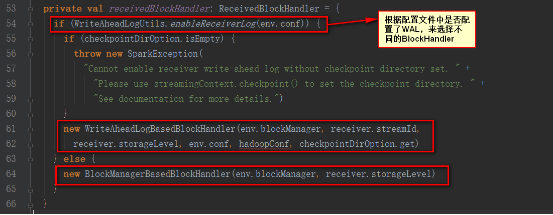
иҝҷйҮҢжҲ‘们讲解BlockManagerBasedBlockHandlerзҡ„ж–№ејҸ
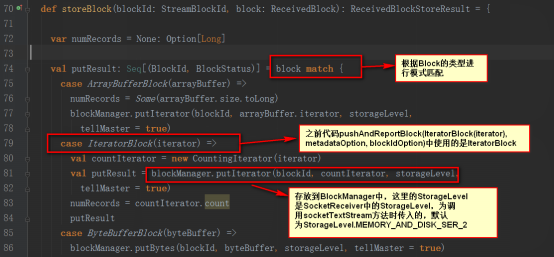
trackerEndpointеҰӮдёӢ

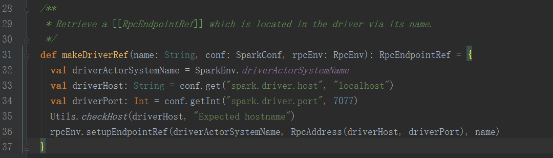
е…¶е®һжҳҜеҸ‘йҖҒз»ҷReceiverTrackerEndpointзұ»пјҢ
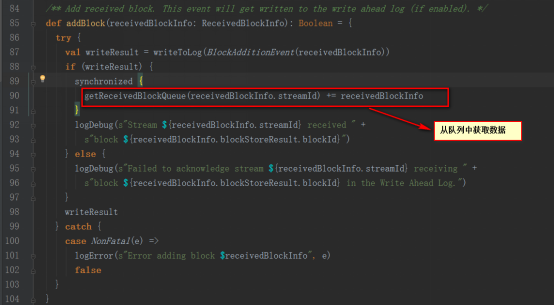
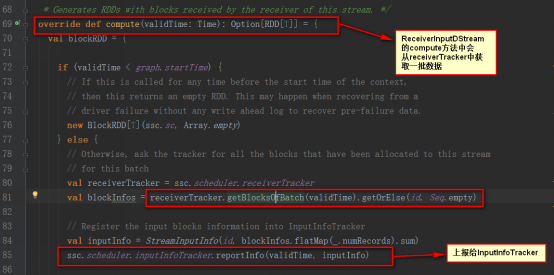
InputInfoTrackerзұ»зҡ„reportInfoж–№жі•еҸӘжҳҜеҜ№ж•°жҚ®иҝӣиЎҢи®°еҪ•з»ҹи®Ў
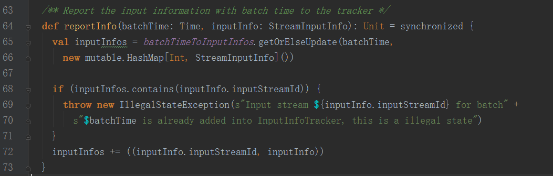
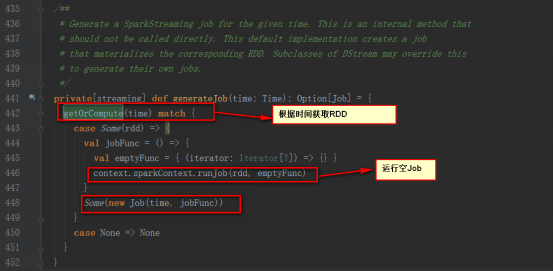
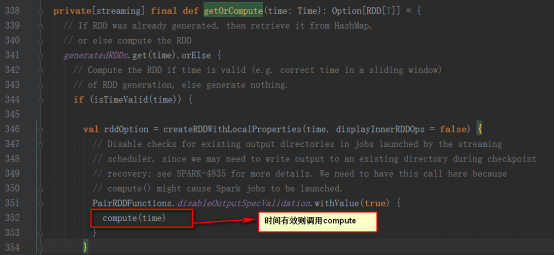
е…¶generateJobж–№жі•жҳҜиў«DStreamGraphи°ғз”Ё
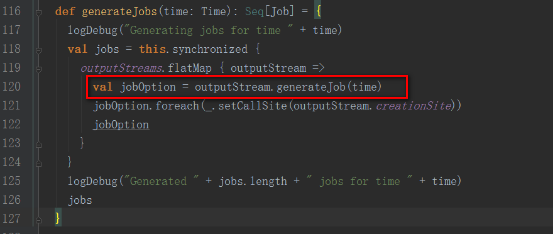
DStreamGraphзҡ„generateJobsж–№жі•жҳҜиў«JobGeneratorзұ»зҡ„generateJobsж–№жі•и°ғз”ЁгҖӮ
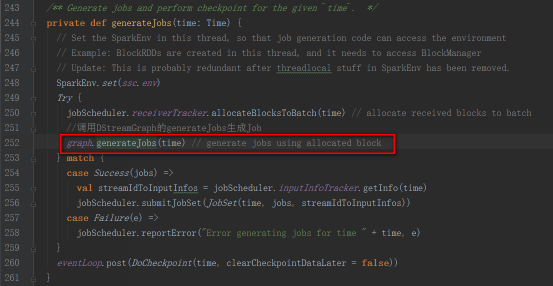
JobGeneratorзұ»дёӯжңүдёҖдёӘе®ҡж—¶еҷЁпјҢbatchIntervalеҸ‘йҖҒGenerateJobsж¶ҲжҒҜ

жҖ»з»“пјҡ
1пјҢеҪ“и°ғз”ЁStreamingContextзҡ„startж–№жі•ж—¶пјҢеҗҜеҠЁдәҶJobScheduler
2пјҢеҪ“JobSchedulerеҗҜеҠЁеҗҺдјҡе…ҲеҗҺеҗҜеҠЁReceiverTrackerе’ҢJobGenerator
3пјҢReceiverTrackerеҗҜеҠЁеҗҺдјҡеҲӣе»әReceiverTrackerEndpointиҝҷдёӘж¶ҲжҒҜеҫӘзҺҜдҪ“пјҢжқҘжҺҘ收иҝҗиЎҢеңЁExecutorдёҠзҡ„ReceiverеҸ‘йҖҒиҝҮжқҘзҡ„ж¶ҲжҒҜ
4пјҢReceiverTrackerеңЁеҗҜеҠЁж—¶дјҡз»ҷиҮӘе·ұеҸ‘йҖҒStartAllReceiversж¶ҲжҒҜпјҢиҮӘе·ұжҺҘ收еҲ°ж¶ҲжҒҜеҗҺпјҢеҗ‘SparkжҸҗдәӨstartReceiverFuncзҡ„Job
5пјҢstartReceiverFuncж–№жі•дёӯеңЁExecutorдёҠеҗҜеҠЁReceiverпјҢ并е®һдҫӢеҢ–ReceiverSupervisorImplеҜ№иұЎпјҢжқҘзӣ‘жҺ§Receiverзҡ„иҝҗиЎҢ
6пјҢReceiverSupervisorImplеҜ№иұЎдјҡи°ғз”ЁReceiverзҡ„onStartж–№жі•пјҢжҲ‘们д»ҘSocketReceiverдёәдҫӢпјҢеҗҜеҠЁдёҖдёӘзәҝзЁӢпјҢиҝһжҺҘServerпјҢиҜ»еҸ–зҪ‘з»ңж•°жҚ®е…Ҳи°ғз”ЁReceiverSupervisorImplзҡ„pushSingleж–№жі•пјҢ
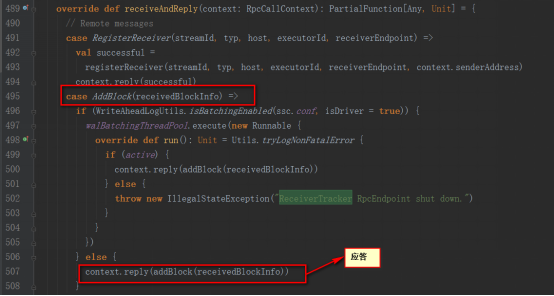
дҝқеӯҳеңЁBlockGeneratorеҜ№иұЎдёӯпјҢиҜҘеҜ№иұЎеҶ…йғЁжңүдёӘе®ҡж—¶еҷЁпјҢж”ҫеҲ°йҳ»еЎһйҳҹеҲ—blocksForPushingпјҢзӯүеҫ…еҶ…йғЁзәҝзЁӢеҸ–еҮәж•°жҚ®ж”ҫеҲ°BlockManagerдёӯпјҢ并еҸ‘AddBlockж¶ҲжҒҜз»ҷReceiverTrackerEndpointгҖӮ
ReceiverTrackerEndpointдёәReceiverTrackerзҡ„еҶ…йғЁзұ»пјҢеңЁжҺҘ收еҲ°addBlockж¶ҲжҒҜеҗҺе°ҶstreamIdеҜ№еә”зҡ„ж•°жҚ®йҳ»еЎһйҳҹеҲ—streamIdToUnallocatedBlockQueuesдёӯ
7пјҢJobGeneratorеҗҜеҠЁеҗҺдјҡеҗҜеҠЁд»ҘbatchIntervalж—¶й—ҙй—ҙйҡ”еҸ‘йҖҒGenerateJobsж¶ҲжҒҜзҡ„е®ҡж—¶еҷЁ
8пјҢжҺҘ收еҲ°GenerateJobsж¶ҲжҒҜдјҡе…ҲеҗҺи§ҰеҸ‘ReceiverTrackerзҡ„allocateBlocksToBatchж–№жі•е’ҢDStreamGraphзҡ„generateJobsж–№жі•
9пјҢReceiverTrackerзҡ„allocateBlocksToBatchж–№жі•дјҡи°ғз”ЁgetReceivedBlockQueueж–№жі•д»Һйҳ»еЎһйҳҹеҲ—streamIdToUnallocatedBlockQueuesдёӯж №жҚ®streamIdиҺ·еҸ–ж•°жҚ®
10пјҢDStreamGraphзҡ„generateJobsж–№жі•пјҢ继иҖҢи°ғз”ЁеҸҳйҮҸеҗҚдёәoutputStreamsзҡ„DStreamйӣҶеҗҲзҡ„generateJobж–№жі•
11пјҢ继иҖҢи°ғз”ЁDStreamзҡ„getOrComputeжқҘи°ғз”Ёе…·дҪ“зҡ„DStreamзҡ„computeж–№жі•пјҢжҲ‘们д»ҘReceiverInputDStreamдёәдҫӢпјҢcomputeж–№жі•жҳҜд»ҺReceiverTrackerдёӯиҺ·еҸ–ж•°жҚ®
еҲ°жӯӨпјҢе…ідәҺвҖңSpark StreamingжҖҺд№ҲдҪҝз”ЁвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





