本篇文章给大家分享的是有关如何进行JobScheduler内幕实现,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
在spark stream程序中的一条关键的语句就是:ssc.start()
1,跟踪进入StreamingContext的start 方法,有一句非常关键的语句scheduler.start(),是个JobScheduler(spark stream用来job调度的)
进行job调度的入口!
2,计入JobScheduler 的start方法。
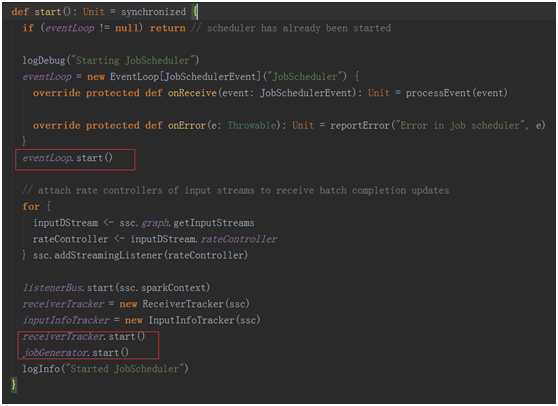
在这个方法中几个关键的点是:
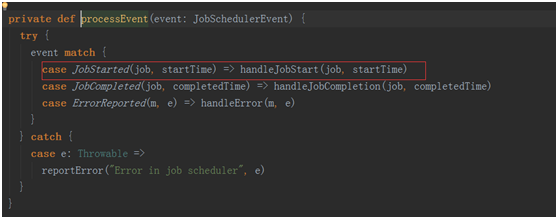
eventLoop.start() 一个事件循环器,用于响应其它组件发来的事件(包括job的启动,完成,以及错误报告)。
 receiverTracker.start() 控制了整个receiver的生成,与数据的接受
receiverTracker.start() 控制了整个receiver的生成,与数据的接受
jobGenerator.start() 真正开始进行job的生成
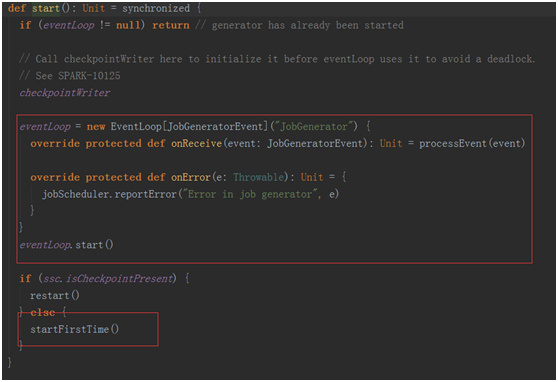 在这个方法中也维护了一个事件处理的循环器eventLoop,用于处理各种事件
在这个方法中也维护了一个事件处理的循环器eventLoop,用于处理各种事件
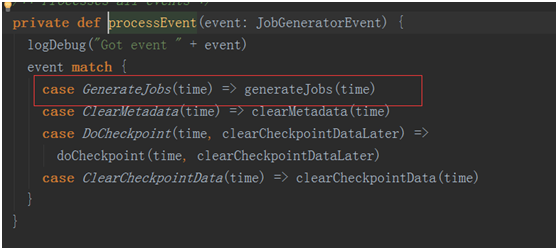 其中最为关键的事件是GenerateJobs(time),这个事件是进行生成job的事件!!
其中最为关键的事件是GenerateJobs(time),这个事件是进行生成job的事件!!
跟踪计入generateJobs(time)
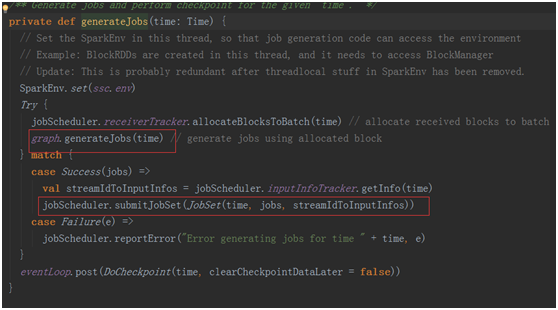
jobScheduler.receiverTracker.allocateBlocksToBatch(time) 为当前的bath分发收到的数据Blocks。
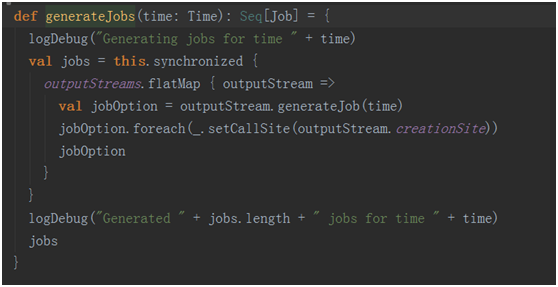
graph.generateJobs(time):根据当前编写的程序的output动作生成相应的job并封装进入集合中。
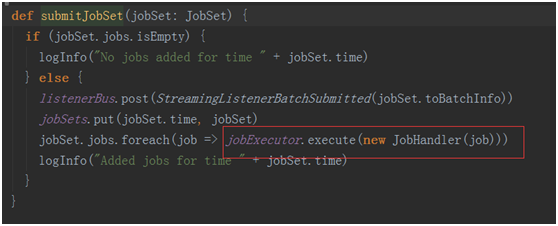
最终通过
 提交作业到executor
提交作业到executor
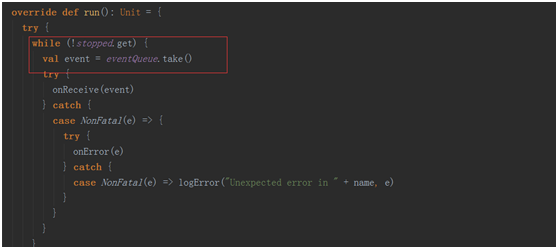
在回去看看jobGenerator.start()中的startFirstTime()
private def startFirstTime() {
val startTime = new Time(timer.getStartTime())
graph.start(startTime - graph.batchDuration)
timer.start(startTime.milliseconds)
logInfo("Started JobGenerator at " + startTime)
}第一次启动会启动一个定时器,该定时器会根基duration bath 不断的的给jobGenerator中的消息循环体!
在jobGenerator中的消息循环体就会不断的去除消息进行处理
以上就是如何进行JobScheduler内幕实现,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/jfld/blog/675297



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



