今天就跟大家聊聊有关Spark Streaming结合Flume和Kafka的日志分析是怎样的,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
按照 http://my.oschina.net/sunmin/blog/692994
整合安装Flume+Kafka+SparkStreaming
将flume/conf/producer.conf将需要监控的日志输出文件修改为本地的log 路径:
/var/log/nginx/www.eric.aysaas.com-access.log(快捷键 Ctrl + Alt + Shift + s),点击Project Structure界面左侧的“Modules”显示下图界面
jar 包自己编译,或者去载 http://search.maven.org/#search|ga|1|g%3A%22org.apache.spark%22%20AND%20v%3A%221.6.1%22
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka.KafkaUtils
/**
* flume+kafka+SparkStreaming 实时 nginx 日志获取
* Created by eric on 16/6/29.
*/
object KafkaLog {
def main(agrs: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[1]").setAppName("StreamingTest")
val ssc = new StreamingContext(sparkConf, Seconds(20))//代表一个给定的秒数的实例
val topic = "HappyBirthDayToAnYuan"
val topicSet = topic.split(" ").toSet
//用 brokers and topics 创建 direct kafka stream
val kafkaParams = Map[String, String]("metadata.broker.list" -> "localhost:9092")
//直接从 kafka brokers 拉取信息,而不使用任何接收器.
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicSet
)
val lines = messages.map(_._2)
lines.print()
val words: DStream[String] = lines.flatMap(_.split("\n"))
words.count().print()
//启动
ssc.start()
ssc.awaitTermination()
}
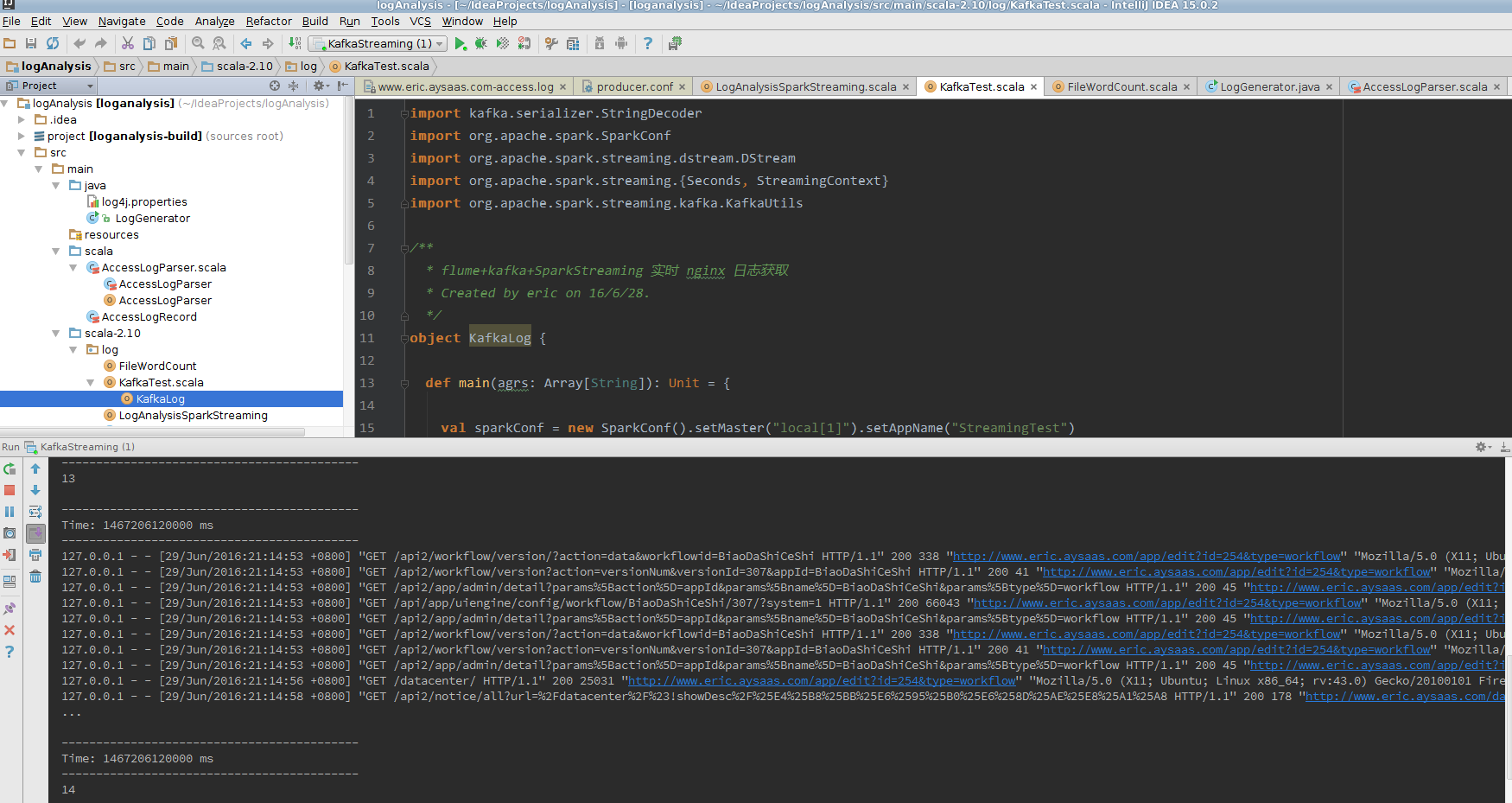
}访问本地页面产生日志 http://www.eric.aysaas.com/app/admin
在这20秒内总共产生的日志行数为:
看完上述内容,你们对Spark Streaming结合Flume和Kafka的日志分析是怎样的有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/sunmin/blog/699929



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



