这篇文章给大家介绍Spark 中怎么读取本地日志文件,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
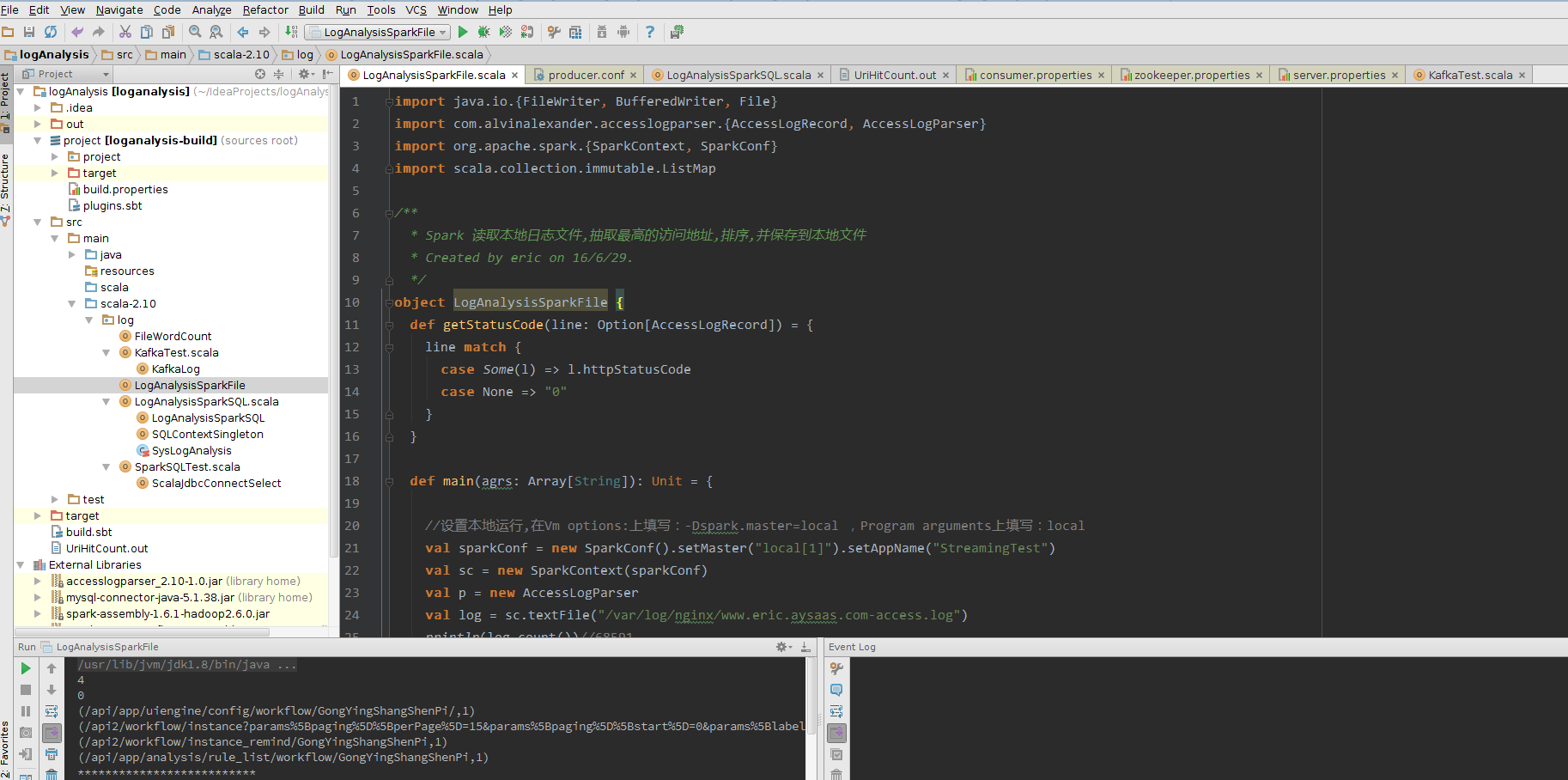
import java.io.{FileWriter, BufferedWriter, File}
import com.alvinalexander.accesslogparser.{AccessLogRecord, AccessLogParser}
import org.apache.spark.{SparkContext, SparkConf}
import scala.collection.immutable.ListMap
/**
* Spark 读取本地日志文件,抽取最高的访问地址,排序,并保存到本地文件
* Created by eric on 16/6/29.
*/
object LogAnalysisSparkFile {
def getStatusCode(line: Option[AccessLogRecord]) = {
line match {
case Some(l) => l.httpStatusCode
case None => "0"
}
}
def main(agrs: Array[String]): Unit = {
//设置本地运行,在Vm options:上填写:-Dspark.master=local ,Program arguments上填写:local
val sparkConf = new SparkConf().setMaster("local[1]").setAppName("StreamingTest")
val sc = new SparkContext(sparkConf)
val p = new AccessLogParser
val log = sc.textFile("/var/log/nginx/www.eric.aysaas.com-access.log")
println(log.count())//68591
val log1 = log.filter(line => getStatusCode(p.parseRecord(line)) == "404").count()
println(log1)
val nullObject = AccessLogRecord("", "", "", "", "GET /foo HTTP/1.1", "", "", "", "")
val recs = log.filter(p.parseRecord(_).getOrElse(nullObject).httpStatusCode == "404")
.map(p.parseRecord(_).getOrElse(nullObject).request)
val wordCounts = log.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey((a, b) => a + b)
val uriCounts = log.map(p.parseRecord(_).getOrElse(nullObject).request)
.map(_.split(" ")(1))
.map(uri => (uri, 1))
.reduceByKey((a, b) => a + b)
val uriToCount = uriCounts.collect // (/foo, 3), (/bar, 10), (/baz, 1) ...//无序
val uriHitCount = ListMap(uriToCount.toSeq.sortWith(_._2 > _._2):_*) // (/bar, 10), (/foo, 3), (/baz, 1),降序
uriCounts.take(10).foreach(println)
println("**************************")
val logSave = uriHitCount.take(10).foreach(println)
// this is a decent way to print some sample data
uriCounts.takeSample(false, 100, 1000)
//输出保存到本地文件,由于ListMap,导致 saveAsTextFile 不能用
// logSave.saveAsTextFile("UriHitCount")
val file = new File("UriHitCount.out")
val bw = new BufferedWriter(new FileWriter(file))
for {
record <- uriHitCount
val uri = record._1
val count = record._2
} bw.write(s"$count => $uri\n")
bw.close
}
}
关于Spark 中怎么读取本地日志文件就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/sunmin/blog/704070



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



