自从公司使用大数据产品之后,就很少碰开源的东西了,集群出问题也是跟研发沟通,前些天有朋友问我,怎么能把hive底层的引擎换成spark,我想了想,是不是将hive的数据库共享给spark然后用spark-shell不就好了,后来查了查资料,原来不是这样的,这里面的操作还挺多了。哎,真的是,用了别人产品,开发是方便了,原理懂的就少了,小编一直还沉浸在用一条SQL底层就能转换的spark程序并行执行任务的幸福生活中。乘着周末,一个人享受着公司的WiFi和空调,把这个开源的hive引擎换成spark搞一搞,顺便分享给大家,最重要的是死肥宅到技术宅的转变。
由于资金有限,只能使用虚拟机给大家演示,这里小编把自己的搭建的hadoop的平台环境介绍一下,先带大家回顾一下hadoopHA模式下,有哪些进程需要启动:(hadoop是2.7.x版本的)
→Namenode:(active-standby):HDFS的主节点,用于元数据管理和管理从节点
→ Datanode:HDFS的从节点,用于存储数据
→ ResourceMananger:yarn的主节点,用于资源调度
→ Nodemanager:yarn的从节点,用于具体的执行任务
→ Zookeeper:服务协调(进程名QuorumPeerMain)
→ JournalNode:用于主备namenode的元数据的共享
→ DFSZKFailoverController:监控着namenode的生死,时刻准备主备切换。
大概就这么多吧,一个极为普通的hadoop平台,小编这里用了3台虚拟机:
每个节点上的服务:
hadoop01:
hadoop02:
hadoop03:
抱怨服务分配不均匀的小伙伴,停下你们的键盘,小编只是演示,匆匆忙忙的搭建的。
这里我在三台机器上都分发了hive的安装包:
执行命令启动hive:(怎么快怎么来,不用beeline了)
[hadoop@hadoop01 applications]$ hive
运行几个命令试试:
hive> use test; #进入数据库
hive> show tables; #查看有哪些表
hive> create external table `user`(id string,name string) row format delimited fields terminated by ',' location "/zy/test/user"; #建表
#导入数据
[hadoop@hadoop01 ~]$ for i in `seq 100` ;do echo "10$i,zy$i">> user.txt ;done ;
[hadoop@hadoop01 ~]$ hadoop fs -put user.txt /zy/test/user
hive> select * from `user`; OK,hive是没有问题的!
首先查看一下hive和spark版本的兼容: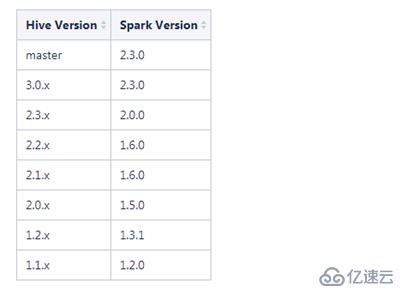
这里小编的spark是2.0.0,hive是2.3.2。
Spark下载地址:https://archive.apache.org/dist/spark/spark-2.0.0/
Hive的下载地址:http://hive.apache.org/downloads.html
这里有spark需要去hive模块编译,这里小编将编译好的spark提供给大家:
链接:https://pan.baidu.com/s/1tPu2a34JZgcjKAtJcAh-pQ 提取码:kqvs
至于hive嘛,官网的就可以
#hive配置(hive-site.xml:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop03:3306/hivedb?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
<!-- 如果 mysql 和 hive 在同一个服务器节点,那么请更改 hadoop02 位 localhost -->
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<!--指定hive数据仓库的数据存储在hdfs上的目录:-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<property>
<name>hive.enable.spark.execution.engine</name>
<value>true</value>
</property>
<!-- spark家目录-->
<property>
<name>spark.home</name>
<value>/applications/spark-2.0.0-bin-hadoop2-without-hive</value>
</property>
<!--也可以在spark default中设置-->
<property>
<name>spark.master</name>
<value>yarn</value>
</property>
<property>
<name>spark.eventLog.enabled</name>
<value>true</value>
</property>
<property>
<name>spark.eventLog.dir</name>
<value>hdfs://zy-hadoop:8020/spark-log</value>
<description>必须要有这个目录</description>
</property>
<property>
<name>spark.executor.memory</name>
<value>512m</value>
</property>
<property>
<name>spark.driver.memory</name>
<value>512m</value>
</property>
<property>
<name>spark.serializer</name>
<value>org.apache.spark.serializer.KryoSerializer</value>
</property>
<!--把spark jars下的jar包上传到hdfs上,yarn模式下减少集群间的分发-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://zy-hadoop:8020/spark-jars/*</value>
</property>
<property>
<name>hive.spark.client.server.connect.timeout</name>
<value>300000</value>
</property>
<!--下面的根据实际情况配置 -->
<property>
<name>spark.yarn.queue</name>
<value>default</value>
</property>
<property>
<name>spark.app.name</name>
<value>zyInceptor</value>
</property>
</configuration>
这里需要注意的一点是,hadoop是HA模式,所以hdfs的路径应该写为:
hdfs://cluster_name:8020/path
#spark的配置(spark-env.sh)
#!/usr/bin/env bash
export JAVA_HOME=/applications/jdk1.8.0_73
export SCALA_HOME=/applications/scala-2.11.8
export HADOOP_HOME=/applications/hadoop-2.8.4
export HADOOP_CONF_DIR=/applications/hadoop-2.8.4/etc/hadoop
export HADOOP_YARN_CONF_DIR=/applications/hadoop-2.8.4/etc/hadoop
export SPARK_HOME=/applications/spark-2.0.0-bin-hadoop2-without-hive
export SPARK_WORKER_MEMORY=512m
export SPARK_EXECUTOR_MEMORY=512m
export SPARK_DRIVER_MEMORY=512m
export SPARK_DIST_CLASSPATH=$(/applications/hadoop-2.8.4/bin/hadoop classpath)① 在hive lib找到以下jar包拷贝到spark jars目录下:
hive-beeline-2.3.3.jar
hive-cli-2.3.3.jar
hive-exec-2.3.3.jar
hive-jdbc-2.3.3.jar
hive-metastore-2.3.3.jar
[hadoop@hadoop01 lib]$ cp hive-beeline-2.3.2.jar hive-cli-2.3.2.jar hive-exec-2.3.2.jar hive-jdbc-2.3.2.jar hive-metastore-2.3.2.jar /applications/spark-2.0.0-bin-hadoop2.7/jars/② 在spark jars中找到以下jar包拷贝到hive lib目录下:
spark-network-common_2.11-2.0.0.jar
spark-core_2.11-2.0.0.jar
scala-library-2.11.8.jar
chill-java,
chill
jackson-module-paranamer,
jackson-module-scala,
jersey-container-servlet-core
jersey-server,
json4s-ast ,
kryo-shaded,
minlog,
scala-xml,
spark-launcher
spark-network-shuffle,
spark-unsafe ,
xbean-asm5-shaded
[hadoop@hadoop01 jars]$ cp spark-network-common_2.11-2.0.0.jar spark-core_2.11-2.0.0.jar scala-library-2.11.8.jar chill-java-0.8.0.jar chill_2.11-0.8.0.jar jackson-module-paranamer-2.6.5.jar jackson-module-scala_2.11-2.6.5.jar jersey-container-servlet-core-2.22.2.jar jersey-server-2.22.2.jar json4s-ast_2.11-3.2.11.jar kryo-shaded-3.0.3.jar minlog-1.3.0.jar scala-xml_2.11-1.0.2.jar spark-launcher_2.11-2.0.0.jar spark-network-shuffle_2.11-2.0.0.jar spark-unsafe_2.11-2.0.0.jar xbean-asm5-shaded-4.4.jar /applications/hive-2.3.2-bin/lib/③ 配置文件的分发
将hadoop中的yarn-site.xml、hdfs-site.xml 放入spark的conf中
将hive-site.xml也放入spark的conf中
④ 分发jar包
在hive-site.xml配置了:spark.yarn.jars
这里我们先在hdfs中创建这个目录:
[hadoop@hadoop01 conf]$ hadoop fs -mkdir /spark-jars将spark的jars中的所有jar包放入这个目录中:
[hadoop@hadoop01 jars]$ hadoop -put ./jars/*.jar /spark-jars⑤ 启动spark
[hadoop@hadoop01 jars]$ /applications/spark-2.0.0-bin-hadoop2-without-hive/sbin/start-all.sh此时这个节点中会出现这几个进程: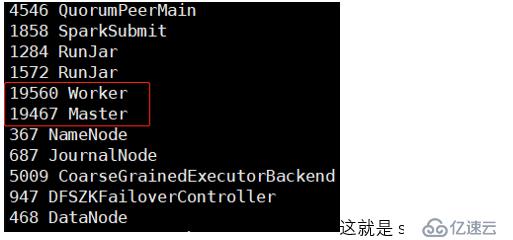
测试,在hive中运行一个SQL:
测试,在hive中运行一个SQL:
这里一般使用select count(1) from table; 来检测!
Spark界面会出现:
Yarn的界面会有:
出现以上界面,表示hive on spark安装成功!!

原因:spark中不能含有hive的依赖,去掉-Phive进行编译spark。
解决:编译spark
下面是hive官网给出的教程:
#Prior to Spark 2.0.0:(他说的是优先在spark2.0.0上,其实就是spark1.6版本的编译)
./make-distribution.sh --name "hadoop2-without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.4,parquet-provided"
#Since Spark 2.0.0:
./dev/make-distribution.sh --name "hadoop2-without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.7,parquet-provided"
#Since Spark 2.3.0:
./dev/make-distribution.sh --name "hadoop2-without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.7,parquet-provided,orc-provided"编译成功之后,在执行前面的内容即可。
这里小编也有编译好之后的spark:
链接:https://pan.baidu.com/s/1tPu2a34JZgcjKAtJcAh-pQ 提取码:kqvs
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





