这篇文章主要介绍了openstack出错怎么办,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
控制节点:
查看云主机: nova list
详细查看单个云主机: nova show [name]
查看各个节点状态:nova-manage service list
计算节点:
查看节点状态: service openstack-nova-compute status
重启节点: service openstack-nova-compute restart
1.
虚拟机建立不起来的时候,有可能是,计算节点上的openstack服务down掉了,在控制节点上重启openstack服务即可。
[root@controlNode01 network-scripts]# nova service-list
| 6 | nova-compute | computeNode01 | nova | enabled | down | 2016-02-26T06:47:45.000000 | None |
[root@controlNode01 network-scripts(keystone_ALUvRAN)]#openstack-service restart
2.
虚拟机删掉了,但是volume还显示in-use状态,需要从数据库里面重置volume的状态。
[root@controlNode01]# mysql cinder
MariaDB [cinder]> SELECT id,status,attach_status,mountpoint,instance_uuid from volumes;
MariaDB [cinder]> UPDATE volumes SET status="available", attach_status="detached", mountpoint=NULL, instance_uuid=NULL WHERE id="336d3e1c-298e-437d-a469-c2872cbe1a3a";
3.
有时候碰到硬盘太大,比如需要创建80G的虚拟机,则会创建失败,需要修改nova里面的vif超时参数。
vif_plugging_timeout=10
vif_plugging_is_fatal=False
4.
在运行“/etc/init.d/network restart”命令时,出现错误“Job for network.service failed. See 'systemctl status network.service' and 'journalctl -xn' for deta”,运行“cat /var/log/messages | grep network”命令查看日志中出现的与network相关的信息
我出现的错误,是由于外网的物理地址与eth0不一样。后来将pub网指向eth0即可
7.14.2016
问题1:
控制节点与计算节点之间的时间不同步:
nova-manage service list检测服务状态原理:
最近更新时间,或者第一次创建时间与当前时间间隔少于CONF.service_down_time(60秒),则认为服务alive
从这里也可以得知为什么控制节点和计算节点的时间要一致。
http://blog.csdn.net/tantexian/article/details/39204993
问题 2:
Nova scheduler :Host has more disk space than database expected
原理:
宿主机 RAM 和 DISK 的使用率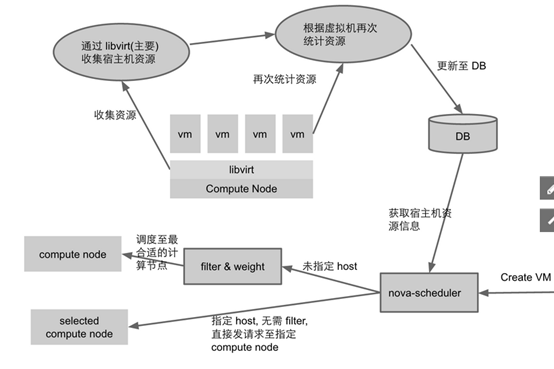 往往要小于虚拟机理论使用的 RAM 和 DISK,在剩余资源充足的条件下,libvirt 将成功创建虚拟机。
往往要小于虚拟机理论使用的 RAM 和 DISK,在剩余资源充足的条件下,libvirt 将成功创建虚拟机。
随想:内存和磁盘超配虽然能提供更多数量的虚拟机,当该宿主机上大量虚拟机的负载都很高时,轻着影响虚拟机性能,重则引起 qemu-kvm 相关进程被杀,即虚拟机被关机。因此对于线上稳定性要求高的业务,建议不要超配 RAM 和 DISK,但可适当超配 CPU。建议这几个参数设置为:
CPU: CONF.cpu_allocation_ratio = 4
RAM: CONF.ram_allocation_ratio = 1.0
DISK: CONF.disk_allocation_ratio = 1.0
RAM-Reserve: CONF.reserved_host_memory_mb = 2048
DISK-Reserve: CONF.reserved_host_disk_mb = 20480
http://blog.csdn.net/wsfdl/article/details/45418727
问题 3:
在nova-all.log日志中发现MessagingTimeout: Timed out waiting for a reply to message ID问题
日志中时不时出现”MessagingTimeout: Timed out waiting for a reply to message“, 来点绝的, 直接修改nova.conf文件,添加:
[conductor]
use_local=true
如果计算节点宕机了,但没有在nova里将这个host disable掉,在 service_down_time and report_interval setting时间内nova-schedule会误认为这个host仍然是alive的,从而出问题了。 另外也可能是olso的bug, https://bugs.launchpad.net/oslo.messaging/+bug/1338732
或者去掉RetryFilter,
scheduler_default_filters=AvailabilityZoneFilter,RamFilter,ComputeFilter,ComputeCapabilitiesFilter,Image
在neutron openswitch-agent .log 中发现
MessagingTimeout: Timed out waiting for a reply to message ID
neutron在同步路由信息时,会从neutron-server获取所有router的信息,这个过程会比较长(130s左右,和网络资源的多少有关系),而 在/etc/neutron/neutron.conf中会有一个配置项“rpc_response_timeout”,它用来配置RPC的超时时间,默认为60s,所以导致超时异常.解决方法为设置rpc_response_timeout=180.
延时是解决各种问题的大招啊。。。
感谢你能够认真阅读完这篇文章,希望小编分享的“openstack出错怎么办”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/guoba/blog/787883



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



