如何使用spark-sql-perf,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
刀片机:1台 126G内存 64核心 centos 7.2
virtualbox安装四台虚拟机(centos 7.2,16G内存,4核):master,worker1,worker2,worker3(centos下)
spark版本:2.0
hadoop版本:2.6
安装请参考:hadoop安装或者Spark On Yarn安装
安装后的截图
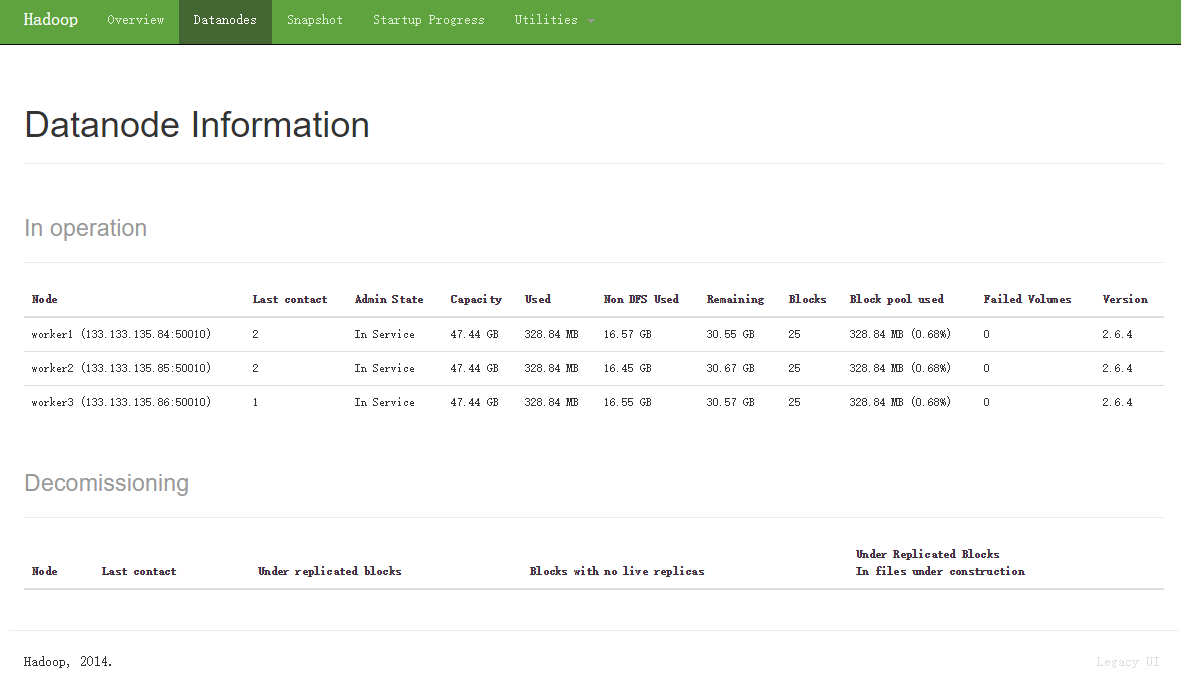
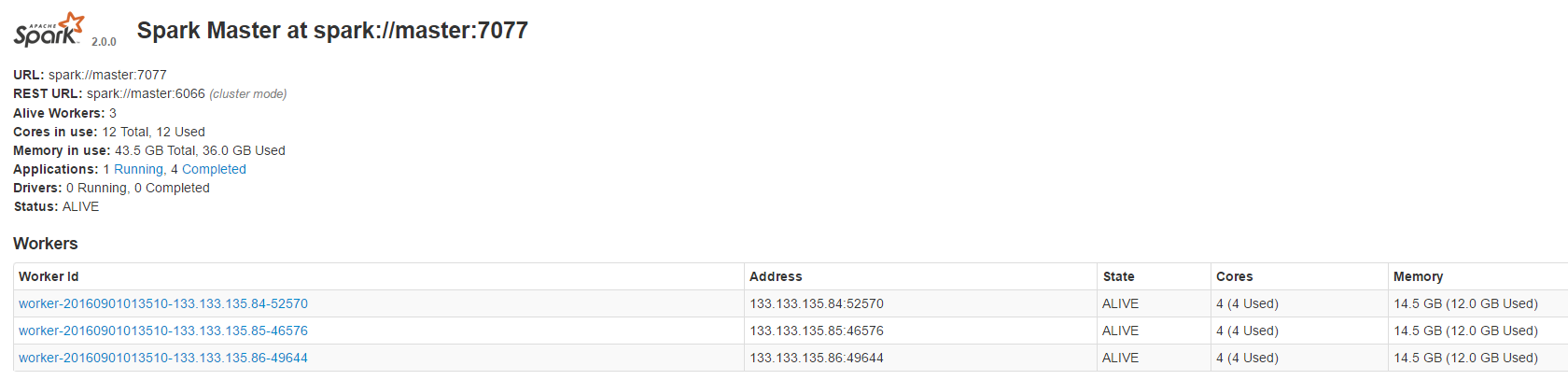
davies/tpcds-kit是用来生成测试数据的工具
git clone https://github.com/davies/tpcds-kit.git
任选一台机器(这里我们选择master)安装以下编译工具(默认软件里没有编译工具)
yum install gcc gcc-c++ bison flex cmake ncurses-devel
cd tpcds-kit/tools
cp Makefile.suite Makefile #复制Makefile.suite为Makefile
make #运行make命令接下来,拷贝tpcds-kit到所有机器的相同目录下(重要)
scp -r /目录/tpcds-kit root@worker1:/目录/tpcds-kit #执行三次该命令复制到worker1,worker2,worker3git clone https://github.com/databricks/spark-sql-perf.git
使用sbt package打包的jar在使用时会出现依赖找不到情况,我们使用Intellij Idea导入该工程
修改sbt.build,更改scala版本为2.11.8 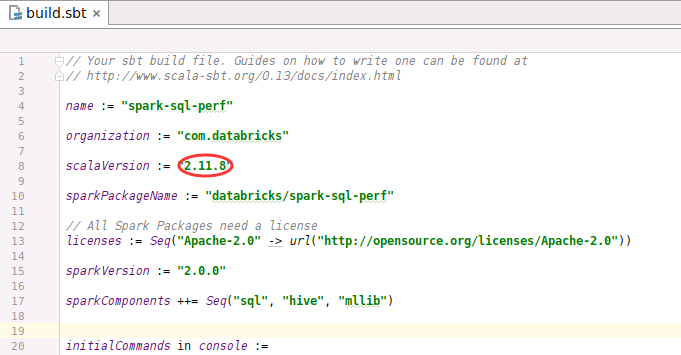
打包成jar包
设置Project Structure
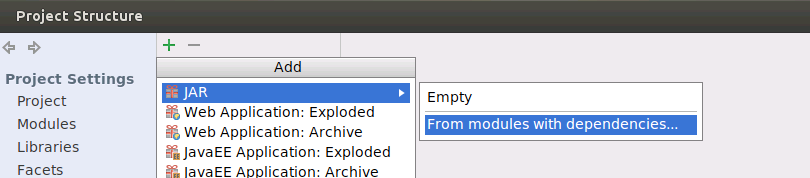
设置Artifacts
Build

jar包不需要每个节点都有
SPARK_DRIVER_MEMORY=8G #依具体情况而定
cd spark-2.0.0-bin-hadoop2.6
./bin/spark-shell --jars /jar包目录/spark-sql-perf.jar --num-executors 20 --executor-cores 2 --executor-memory 8G --master spark://master:7077 // 创建sqlContext
val sqlContext=new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
// 生成数据 参数1:sqlContext 参数2:tpcds-kit目录 参数3:生成的数据量(GB)
val tables=new Tables(sqlCotext,"/目录/tpcds-kit/tools",1)
tables.genData("hdfs://master:8020:tpctest","parquet",true,false,false,false,false);
// 创建表结构(外部表或者临时表)
// talbles.createExternalTables("hdfs://master:8020:tpctest","parquet","mytest",false)
talbles.createTemporaryTables("hdfs://master:8020:tpctest","parquet")
import com.databricks.spark.sql.perf.tpcds.TPCDS
val tpcds=new TPCDS(sqlContext=sqlContext)
//运行测试
val experiment=tpcds.runExperiment(tpcds.tpcds1_4Queries)在spark-shell中我们可以调用 _experiment.html_查看执行状态
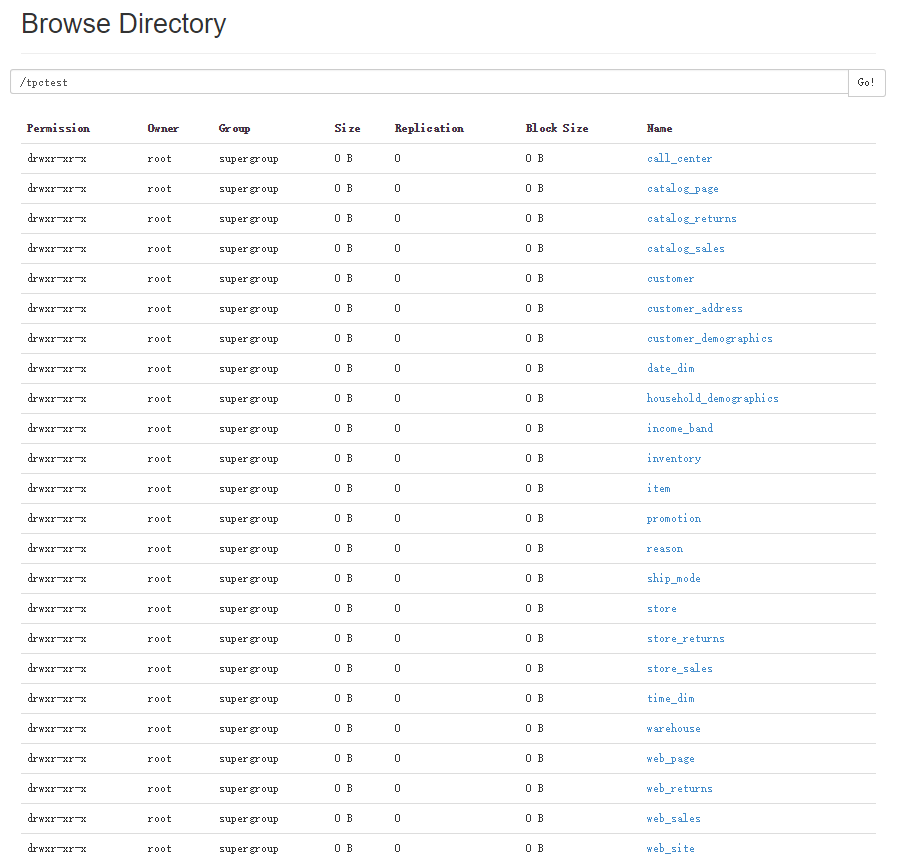
HDFS上生成的数据截图
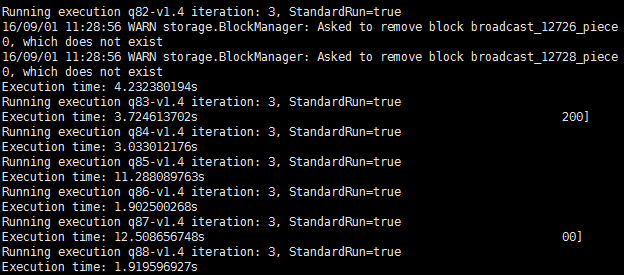
运行截图
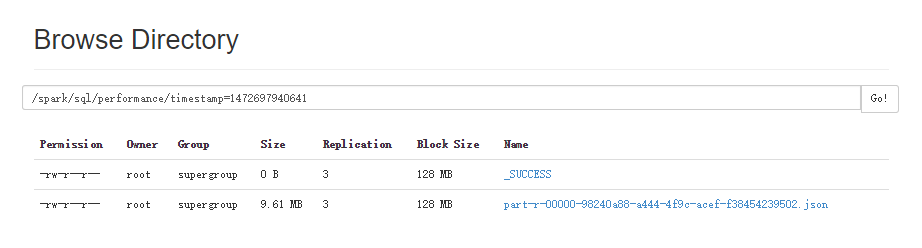
运行结果保存在spark/performance目录下
HDFS上的评测结果截图
关于如何使用spark-sql-perf问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/697744/blog/805428



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



