这篇文章主要介绍“怎么理解RGW中request的处理流程”,在日常操作中,相信很多人在怎么理解RGW中request的处理流程问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”怎么理解RGW中request的处理流程”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
以civetweb为例

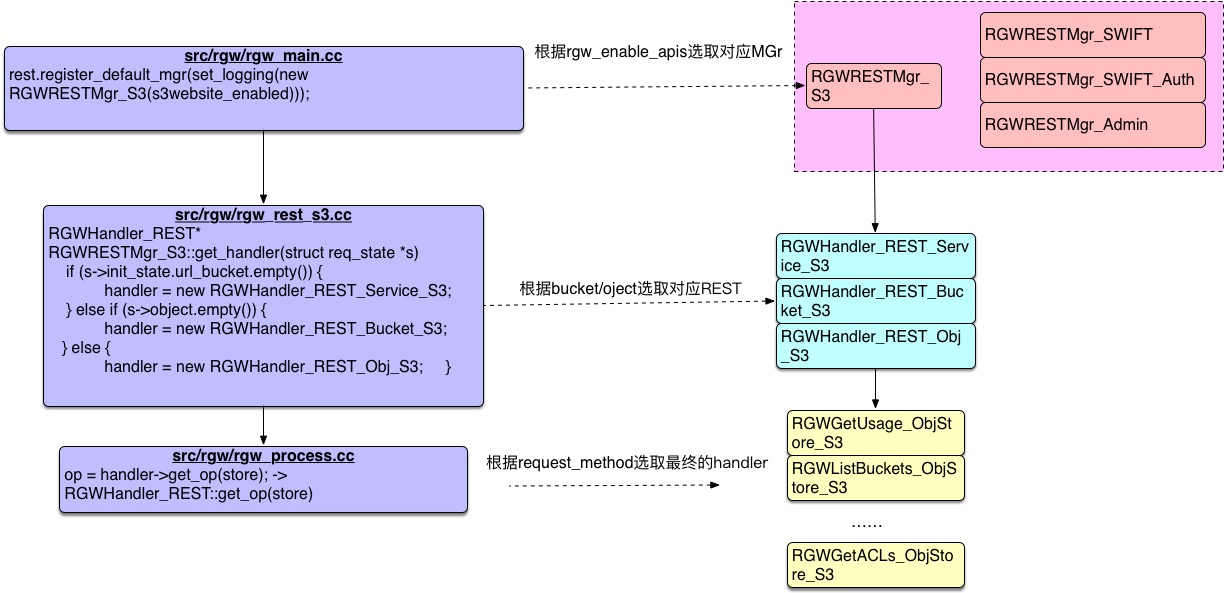
rgw_main.cc为整个radosgw服务的入口,main()函数中根据在ceph.conf的rgw frontends参数设置来选择不同的前端类型,之后执行相应的run()方法实现整个frontend服务的启动。注意这里会根据ceph.conf中rgw_enable_apis的设置,实现s3、swift、admin等多种类型的接口生成不同的handler,具体代码如下
#src/rgw/rgw_main.cc
get_str_list(g_conf->rgw_enable_apis, apis); #获取接口类型列表
map<string, bool> apis_map;
for (list<string>::iterator li = apis.begin(); li != apis.end(); ++li) {
apis_map[*li] = true;
}
...
if (apis_map.count("s3") > 0 || s3website_enabled) {
if (! swift_at_root) {
rest.register_default_mgr(set_logging(new RGWRESTMgr_S3(s3website_enabled))); #设置S3接口默认handler为RGWRESTMgr_S3
...
if (apis_map.count("swift") > 0) {
do_swift = true;
swift_init(g_ceph_context);
RGWRESTMgr_SWIFT* const swift_resource = new RGWRESTMgr_SWIFT;#设置swift接口默认handler为RGWRESTMgr_SWIFT
...之后在对应的rgw_civetweb_fronted.cc中,根据之前介绍的civetweb启动流程,设置相应启动参数,之后使用mg_start()完成civetweb的启动。(注意参数中callback设置的是civetweb_callback)
#src/rgw/rgw_civetweb_frontend.cc
int RGWMongooseFrontend::run() {
char thread_pool_buf[32];
snprintf(thread_pool_buf, sizeof(thread_pool_buf), "%d",
(int)g_conf->rgw_thread_pool_size);
string port_str;
map<string, string> conf_map = conf->get_config_map();
conf->get_val("port", "80", &port_str);
conf_map.erase("port");
std::replace(port_str.begin(), port_str.end(), '+', ',');
conf_map["listening_ports"] = port_str; #civetweb默认启动监听端口
set_conf_default(conf_map, "enable_keep_alive", "yes"); #keep_alive参数设置
set_conf_default(conf_map, "num_threads", thread_pool_buf); #默认threads设置
set_conf_default(conf_map, "decode_url", "no");
...
struct mg_callbacks cb;
memset((void *)&cb, 0, sizeof(cb));
cb.begin_request = civetweb_callback; #回调函数设置
cb.log_message = rgw_civetweb_log_callback;
cb.log_access = rgw_civetweb_log_access_callback;
ctx = mg_start(&cb, &env, (const char **)&options); #启动服务
if (!ctx) {
return -EIO;
}
return 0;
} /* RGWMongooseFrontend::run */经过上一步的设置,在civetweb_callback中每一个request请求都需要经过process_request()进行处理,注意每个request请求都会绑定一组RGWRados(负责底层Librados的数据读写)/RGWREST(对应request和Response的处理)/OpsLogSocket(日志消息记录)
#src/rgw/rgw_civetweb_frontend.cc
static int civetweb_callback(struct mg_connection* conn) { struct mg_request_info* req_info = mg_get_request_info(conn); RGWMongooseEnv* pe = static_cast<RGWMongooseEnv *>(req_info->user_data);
{ // hold a read lock over access to pe->store for reconfiguration RWLock::RLocker lock(pe->mutex);
RGWRados* store = pe->store; RGWREST* rest = pe->rest; OpsLogSocket* olog = pe->olog;
RGWRequest req(store->get_new_req_id()); RGWMongoose client_io(conn);
int ret = process_request(pe->store, rest, &req, &client_io, olog); #每个request请求绑定一组前面的RGWRados、RGWREST、OpsLogSocket ... ```
之后调用rgw_process.cc中的process_request(),其中rest->get_handler根据请求的URL是否包含bucket、object信息,获取到对应的handler类型,之后调用handler->get_op(store)根据前面取得的handler对应request_method获取到最终的handler,之后触发handler对应的pre_exec()、execute()、complete()完整整个request请求的处理,代码如下:
#src/rgw/rgw_process.cc
int process_request(RGWRados* store, RGWREST* rest, RGWRequest* req,GWStreamIO* client_io, OpsLogSocket* olog)
{int ret = 0;
client_io->init(g_ceph_context);
...
RGWHandler_REST *handler = rest->get_handler(store, s, client_io, &mgr,&init_error); #这里根据URL里面是否包含bucket、Object字段会进一步获取到对应的handler类型
if (init_error != 0) {
abort_early(s, NULL, init_error, NULL);
goto done;
}
dout(10) << "handler=" << typeid(*handler).name() << dendl;
should_log = mgr->get_logging();
req->log_format(s, "getting op %d", s->op);
op = handler->get_op(store); #这里根据request_method获取到最终处理request请求的handler类型
...
req->log(s, "pre-executing");
op->pre_exec(); #请求预处理
req->log(s, "executing");
op->execute(); #具体请求的具体实现
req->log(s, "completing");
op->complete(); #完成请求处理#src/rgw/rgw_process.cc
RGWHandler_REST* RGWRESTMgr_S3::get_handler(struct req_state *s)
{
bool is_s3website = enable_s3website && (s->prot_flags & RGW_REST_WEBSITE);
int ret =
RGWHandler_REST_S3::init_from_header(s,
is_s3website ? RGW_FORMAT_HTML :
RGW_FORMAT_XML, true);
if (ret < 0)
return NULL;
RGWHandler_REST* handler;
// TODO: Make this more readable
if (is_s3website) {
if (s->init_state.url_bucket.empty()) {
handler = new RGWHandler_REST_Service_S3Website;
} else if (s->object.empty()) {
handler = new RGWHandler_REST_Bucket_S3Website;
} else {
handler = new RGWHandler_REST_Obj_S3Website;
}
} else {
if (s->init_state.url_bucket.empty()) {
handler = new RGWHandler_REST_Service_S3; #bucket为空则切换到RGWHandler_REST_Service_S3
} else if (s->object.empty()) {
handler = new RGWHandler_REST_Bucket_S3; #obj为空则切换RGWHandler_REST_Bucket_S3
} else {
handler = new RGWHandler_REST_Obj_S3; #bucket和Object都不为空,则切换到RGWHandler_REST_Obj_S3
}
}
ldout(s->cct, 20) << __func__ << " handler=" << typeid(*handler).name()
<< dendl;
return handler;
}#src/rgw/rgw_rest.cc
RGWOp* RGWHandler_REST::get_op(RGWRados* store)
{
RGWOp *op;
switch (s->op) #这里s对应一个req_state的结构体
{ rest->op
case OP_GET:
op = op_get();
break;
case OP_PUT:
op = op_put();
break;
case OP_DELETE:
op = op_delete();
break;
case OP_HEAD:
op = op_head();
break;
case OP_POST:
op = op_post();
break;
case OP_COPY:
op = op_copy();
break;
case OP_OPTIONS:
op = op_options();
break;
default:
return NULL;
}
if (op) {
op->init(store, s, this);
}
return op;
} /* get_op */结构体定义
struct req_state {
CephContext *cct;
RGWClientIO *cio;
RGWRequest *req; /// XXX: re-remove??
http_op op; #对应一个枚举类型,具体如下
RGWOpType op_type;
...
enum http_op {
OP_GET,
OP_PUT,
OP_DELETE,
OP_HEAD,
OP_POST,
OP_COPY,
OP_OPTIONS,
OP_UNKNOWN,
};理解整个URL转换handler的过程,能够感觉request信息快速定位具体的op操作,方便debug,整个过程用下面一张图总结。
到此,关于“怎么理解RGW中request的处理流程”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





