一、初识Flink
官网:https://flink.apache.org/
Apache Flink是一款分布式、高性能、高可用、高精确的为数据流应用而生的开源流式处理框架。在 2014 被 Apache 孵化器所接受,然后迅速地成为了 ASF(Apache Software Foundation)的顶级项目之一。
Flink核心是用Java和Scala编写的一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能。
可对无限数据流(实时流)和有限数据流(批处理)和进行有状态计算。可部署在各种集群环境,对各种大小的数据规模进行快速计算。
Flink原生支持了迭代计算、内存管理和程序优化。
二、Flink基本架构介绍

具体组件:
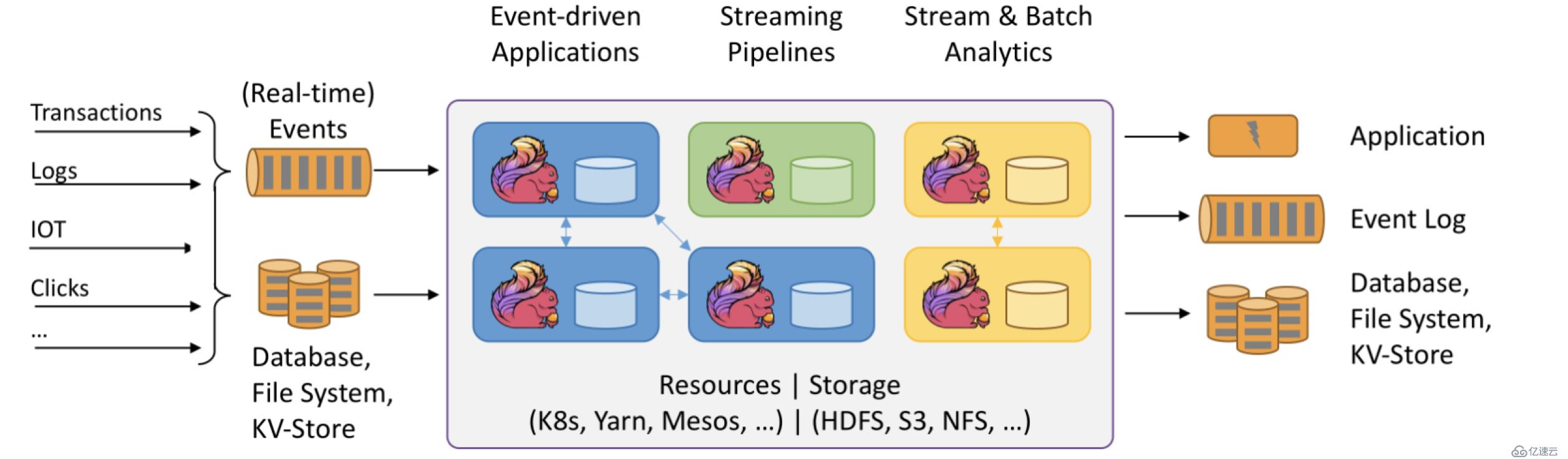
上图大致可以分为三块内容:左边为数据输入、右边为数据输出、中间为Flink数据处理。
Flink支持消息队列的Events(支持实时的事件)的输入,上游源源不断产生数据放入消息队列,Flink不断消费、处理消息队列中的数据,处理完成之后数据写入下游系统,这个过程是不断持续的进行。
数据源:
1.Transactions:即交易数据。比如各种电商平台用户下单,这个数据源源不断写入消息队列
2.Logs:比如web应用运行过程中产生的错误日志信息,源源不断发送到消息队列中,后续Flink处理为运维部门提供监控依据。
3.IOT:即物联网,英文全称为Internet of things。物联网的终端设备,比如华为手环、小米手环,源源不断的产生数据写入消息队列,后续Flink处理提供健康报告
4.Clicks:即点击流,比如打开淘宝网站,淘宝网站页面上埋有很多数据采集点或者探针,当用户点击淘宝页面的时候,它会采集用户点击行为的详细信息,这些用户的点击行为产生的数据流我们称为点击流。
数据输入系统:
Flink既支持实时(Real-time)流处理,又支持批处理。实时流消息系统,比如Kafka。批处理系统有很多,DataBase(比如传统MySQL、Oracle数据库),KV-Store(比如HBase、MongoDB数据库),File System(比如本地文件系统、分布式文件系统HDFS)。
Flink数据处理:
Flink在数据处理过程中,资源管理调度可以使用K8s(Kubernetes 简称K8s,是Google开源的一个容器编排引擎)、YARN、Mesos,中间数据存储可以使用HDFS、S3、NFS等
数据输出:
Flink可以将处理后的数据输出下游的应用(Application),也可以将处理过后的数据写入消息队列(比如Kafka),还可以将处理后的输入写入Database、File System和KV-Store。
三、Flink核心组件栈
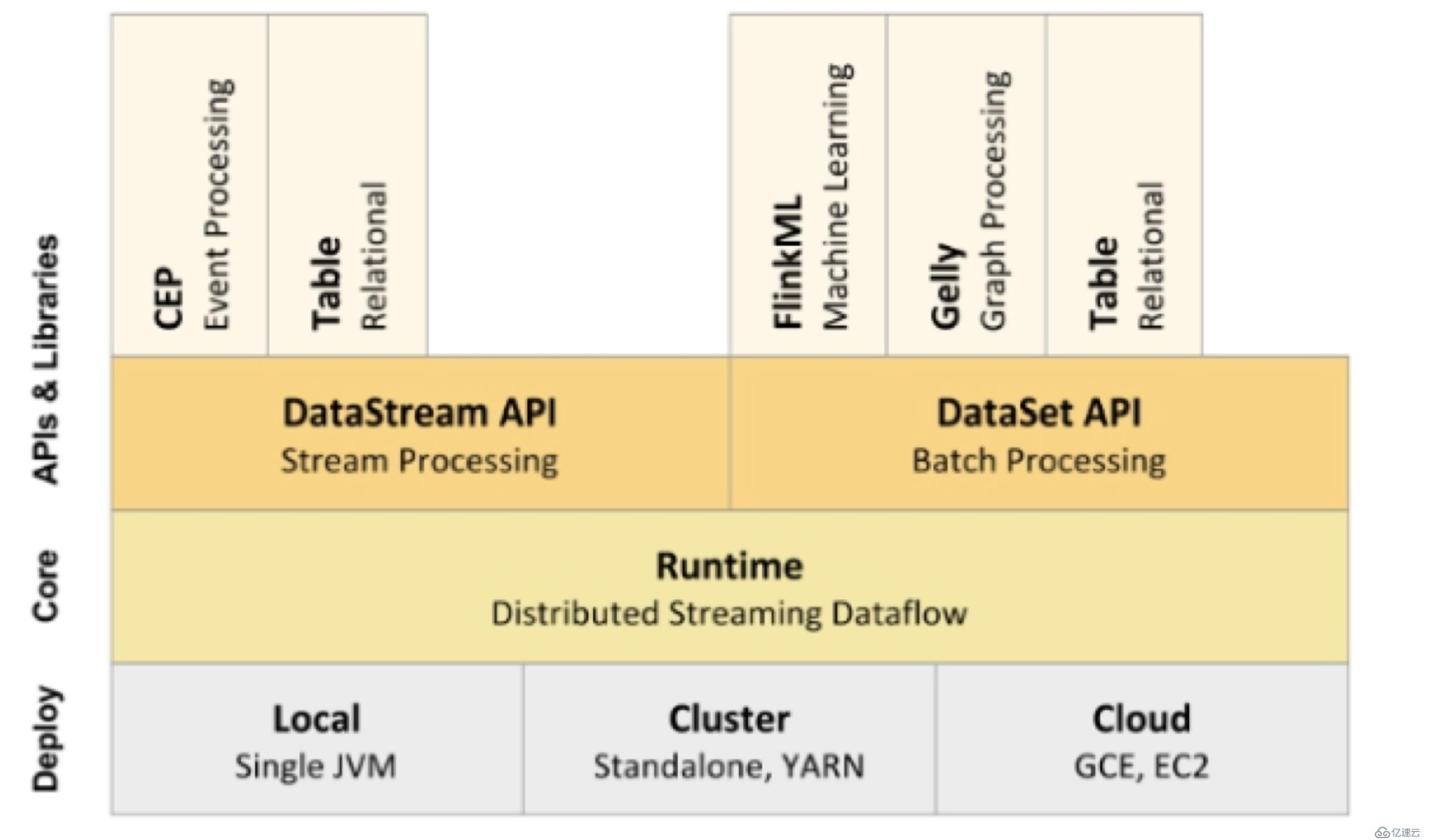
从上图可以看出Flink的底层是Deploy,Flink可以Local模式运行,启动单个 JVM。Flink也可以Standalone 集群模式运行,同时也支持Flink ON YARN,Flink应用直接提交到YARN上面运行。另外Flink还可以运行在GCE(谷歌云服务)和EC2(亚马逊云服务)。
Deploy的上层是Flink的核心(Core)部分Runtime。在Runtime之上提供了两套核心的API,DataStream API(流处理)和DataSet API(批处理)。在核心API之上又扩展了一些高阶的库和API,比如CEP流处理,Table API和SQL,Flink ML机器学习库,Gelly图计算。SQL既可以跑在DataStream API,又可以跑在DataSet API。
四、Flink的前世今生
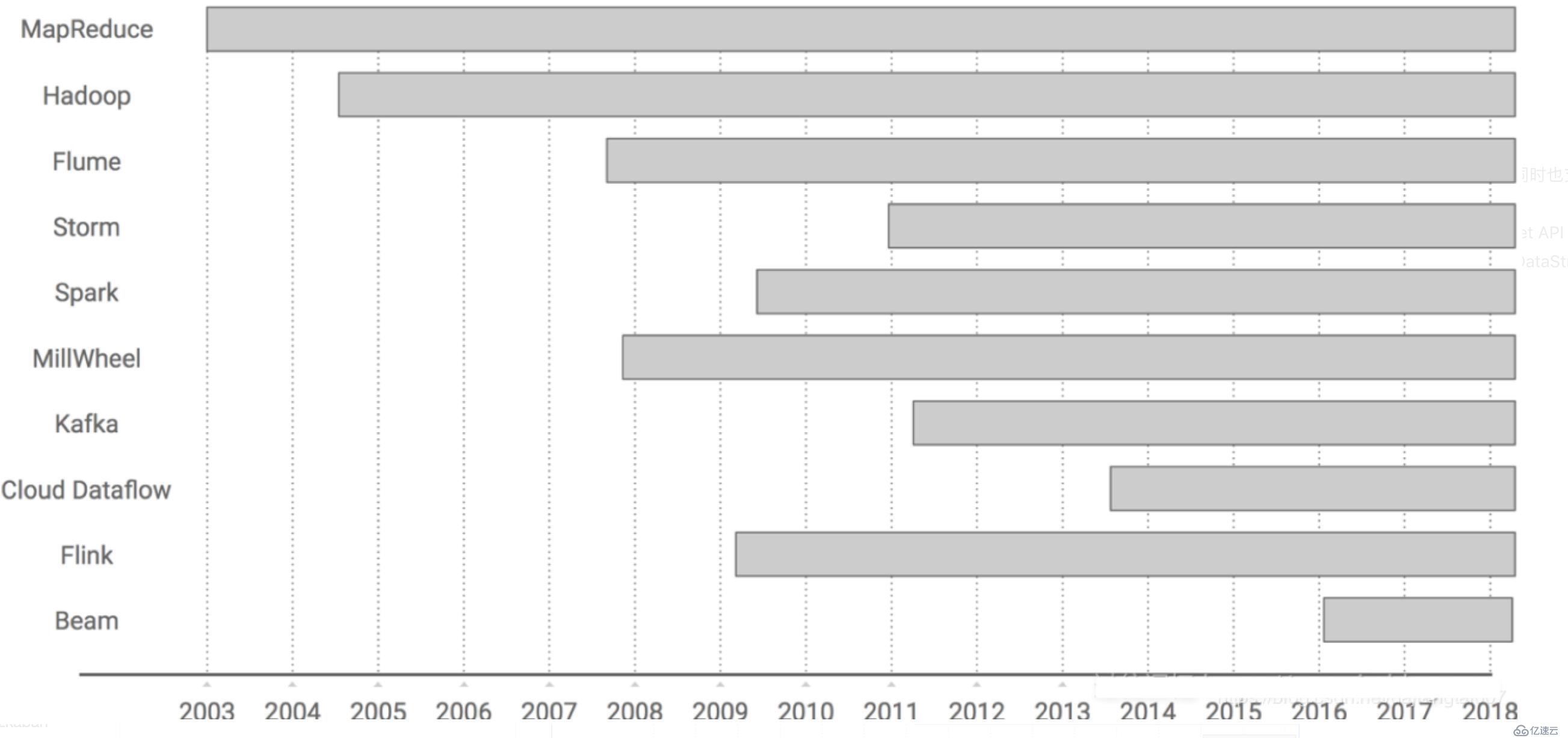
Flink在发展过程的关键时刻:
诞生于2009年,原来叫StratoSphere,是柏林工业大学的一个研究性项目,早期专注于批计算。
2014年孵化出Flink项目并捐给了Apache。
2015年开始引起大家注意,出现在大数据舞台。
2016年在阿里得到大规模应用。
五、为什么是Flink?
大数据生态圈很庞大,优秀的框架和组件,为何Flink如此受宠?
1. 从技术角度来说,目前大数据计算引擎中, 能够同时支持流处理和批处理的计算引擎,只有Spark和Flink(Storm只支持流处理)。其中Spark的技术理念是基于微批处理来模拟流的计算。而Flink则完全相反,它采用的是基于流计算来模拟批计算。从技术发展方向看,用批来模拟流有一定的技术局限性,并且这个局限性可能很难突破。而Flink基于流来模拟批,在技术上有更好的扩展性。
2. 从语言方面来说,提供友好且优雅流畅的java和scala api和支持,java用户众多也是一个重要原因。
3. 大公司的风向标作用, 阿里全面转向Flink无疑是一个催化剂。目前,阿里巴巴所有的业务,包括阿里巴巴所有子公司都采用了基于Flink搭建的实时计算平台。
阿里巴巴计算平台事业部资深技术专家莫问在云栖大会的演讲内容 —— 阿里巴巴为什么选择Apache Flink?这个框架的性能表现确实很优秀, Flink最初上线阿里巴巴只有数百台服务器,目前规模已达上万台,此等规模在全球范围内也是屈指可数;基于Flink,阿里内部积累起来的状态数据已经是PB级别规模;如今每天在阿里Flink的计算平台上,处理的数据已经超过万亿条;在峰值期间可以承担每秒超过4.72亿次的访问,最典型的应用场景是阿里巴巴双11大屏。
其实不光阿里,国内很多一线的公司都投入很多人力和财力在Flink实时计算上。

六、流式计算的代表:Flink、Spark Streaming、Storm对比
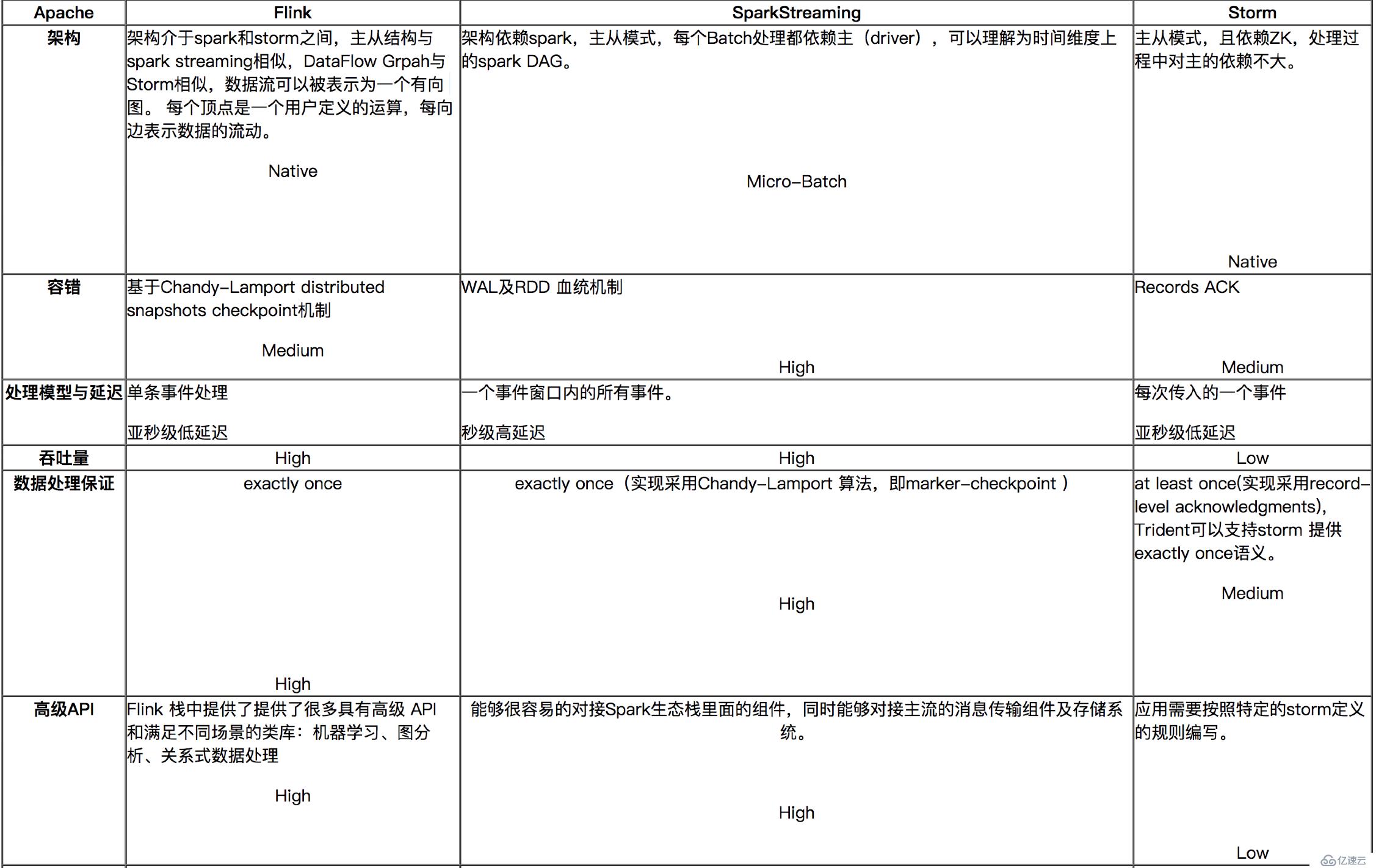
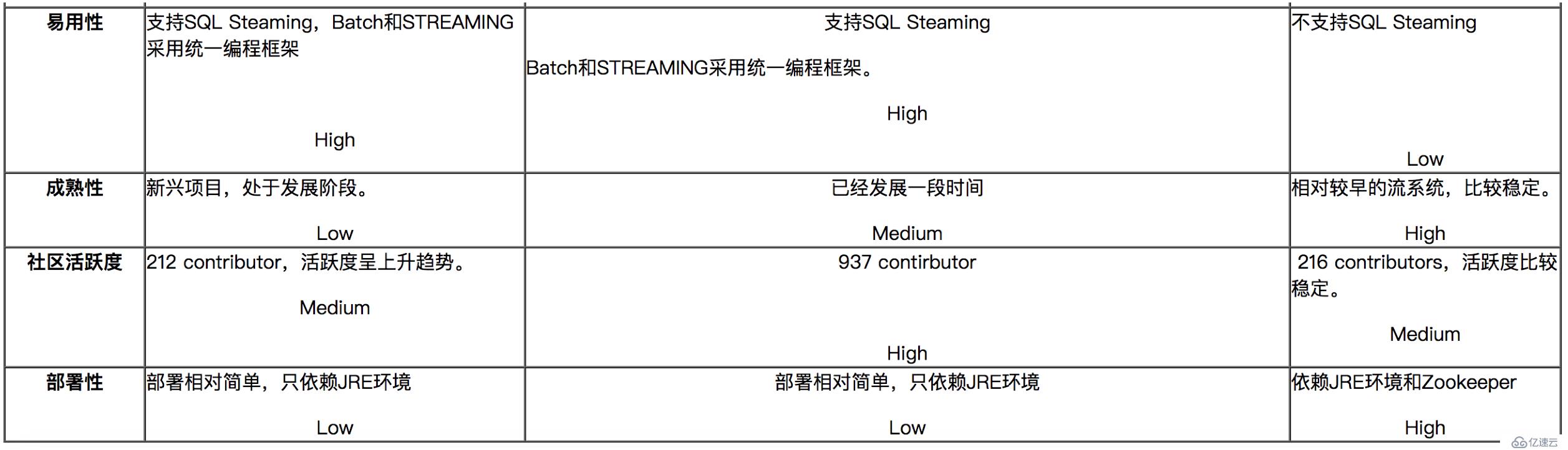
对比分析与建议:
如果对延迟要求不高的情况下,建议使用Spark Streaming,丰富的高级,使用简单,天然对接Spark生态栈中的其他组件,吞吐量大,部署简单,UI界面也做的更加智能,社区活跃度较高,有问题响应速度也是比较快的,比较适合做流式的ETL,而且Spark的发展势头也是有目共睹的,相信未来性能和功能将会更加完善。
如果对延迟性要求比较高的话,建议可以尝试下Flink,Flink是目前发展比较火的一个流系统,采用原生的流处理系统,保证了低延迟性,在和容错上也是做的比较完善,使用起来相对来说也是比较简单的,部署容易,而且发展势头也越来越好,相信后面社区问题的响应速度应该也是比较快的。
七、案例演示(java&scala)
1、maven依赖导入
<dependencies>
<!--java-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.8.0</version>
</dependency>
<!--scala-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.7</version>
</dependency>
</dependencies>
java代码:
package com.fwmagic.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* 使用flink对指定窗口内的数据进行实时统计,最终把结果打印出来
* 先在机器上执行nc -lk 9000
*/
public class StreamingWindowWordCountJava {
public static void main(String[] args) throws Exception {
//定义socket的端口号,默认9999
final int port;
try {
final ParameterTool parameterTool = ParameterTool.fromArgs(args);
port = parameterTool.getInt("port", 9999);
} catch (Exception e) {
System.err.println("No port specified. Please run 'SocketWindowWordCount --port <port>'");
return;
}
//获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//连接socket获取输入的数据
DataStreamSource<String> text = env.socketTextStream("localhost", port, "\n");
//计算数据
//拍平操作,把每行的单词转为<word,count>类型的数据
DataStream<WordWithCount> windowCount = text.flatMap(new FlatMapFunction<String, WordWithCount>() {
public void flatMap(String value, Collector<WordWithCount> out) {
String[] splits = value.split("\\s");
for (String word : splits) {
out.collect(new WordWithCount(word, 1L));
}
}
//针对相同的word数据进行分组
}).keyBy("word")
//指定计算数据的窗口大小和滑动窗口大小,每1秒计算一次最近5秒的结果
.timeWindow(Time.seconds(5),Time.seconds(1))
.sum("count");
windowCount.print().setParallelism(1);
//把数据打印到控制台,使用一个并行度
// windowCount.print().setParallelism(1);
//注意:因为flink是懒加载的,所以必须调用execute方法,上面的代码才会执行
env.execute("streaming word count");
}
/**
* 存储单词以及单词出现的次数
*/
public static class WordWithCount {
public String word;
public long count;
public WordWithCount() {
}
public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
}
@Override
public String toString() {
String date = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date());
return date + ":{" +
"word='" + word + '\'' +
", count=" + count +
'}';
}
}
}
scala代码:
package com.fwmagic.flink
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.scala._
object StreamingWWC {
def main(args: Array[String]): Unit = {
val parameterTool: ParameterTool = ParameterTool.fromArgs(args)
val port: Int = parameterTool.getInt("port",9999)
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val text: DataStream[String] = env.socketTextStream("localhost",port)
val wc: DataStream[WordCount] = text.flatMap(t => t.split(","))
.map(w => WordCount(w, 1))
.keyBy("word")
.timeWindow(Time.seconds(5), Time.seconds(1))
.reduce((a,b) => WordCount(a.word,a.count+b.count))
//.sum("count")
wc.print().setParallelism(1)
env.execute("word count streaming !")
}
}
case class WordCount(word:String,count:Long)八、Flink部署
以local部署模式为例,后续会介绍在yarn上部署:
下载:http://apache.website-solution.net/flink/flink-1.8.0/flink-1.8.0-bin-scala_2.11.tgz
解压:tar -zxvf flink-1.8.0-bin-scala_2.11.tgz
启动:bin/start-cluster.sh
查看页面:http://localhost:8081/
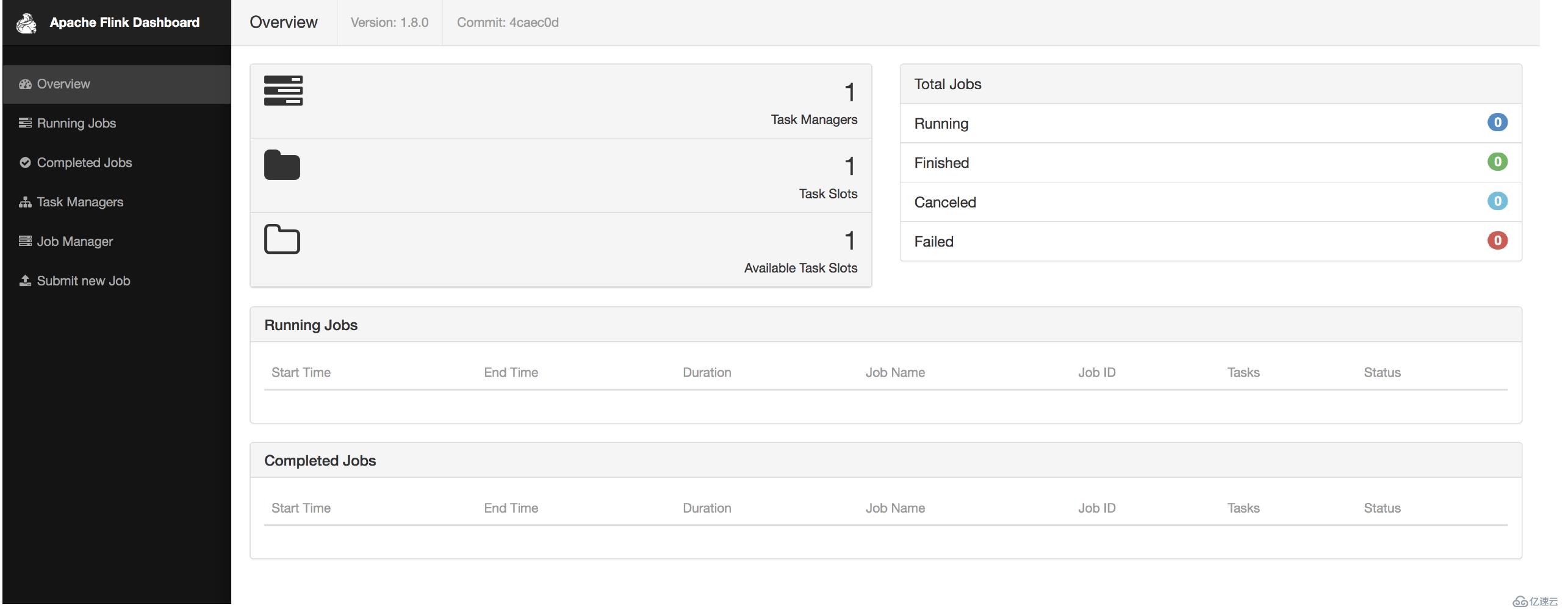
打包、提交任务:
mvn clean package
1、通过页面的Submit new Job来提交任务
2、通过命令行提交:bin/flink run -c com.fwmagic.flink.StreamingWindowWordCountJava examples/myjar/fwmagic-flink.jar --port 6666
注意:提交任务前先开启端口:nc -lk 6666
测试:
发送消息,在页面中查看日志:TaskManagers->点击任务->Stdout
或者在命令行查看日志:tail -f log/flink-*-taskexecutor-*.out

停止任务
1:web ui界面停止
2:命令行执行bin/flink cancel <job-id>
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务












