Apache Kafka框架是怎样的呢,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
下面将对Kafka做一个简单的描述。
Kafka是Apache下的一个用于处理数据流的分布式消息框架,它拥有水平扩展、容错、高效等特性,可以使用该框架来实现以下功能:
构建在系统间进行实时数据传输的通道。
构建对数据流行转换或响应的实时应用。
Kafka的整体结构与RabbitMQ类似,消息生产者向Kafka服务器发送消息,Kafak接收消息后,再投递给消费者。在Kafka中,生产者消息会被发送到Topic中,Topic保存着各类的数据,每一条数据都使用键、值进行保存。每一个Topic下都包含一个或多个物理分区(Partition),这些分区维护着消息的内容和索引,它们有可能被保存在不同的服务器上面。对于客户端来说,无须关心数据如何被保存,只需要关心将消息发往哪个Topic。
Kafka依赖了ZooKeeper,启动Kafka服务器前,要先启动ZooKeeper。本章所使用的ZooKeeper版本为3.4.8,Kafka版本为2.11。下载两个框架的压缩包后解压,分别得到zookeeper-3.4.8与kafka_2.11-0.11.0.0目录。
先进入zookeeper-3.4.8/conf目录,将zoo_sample.cfg文件复制一份,并重命名为zoo.cfg。使用命令行工具,进行zookeeper-3.4.8/bin目录,运行“zkServer”命令,如果正常启动,将会占用2181端口,命令行窗口不必关闭,接下来启动Kafka。
使用命令行工具,进行“kafka_2.11-0.11.0.0/bin/windows”目录,运行“kafka-server-start ../../config/server.properties”命令启动Kafka服务器,如果正常启动,将会占用9092端口。此处的Kafka就相当于前面章节中的RabbitMQ服务器,Kafka同样提供了API让我们编写客户端。接下来,我们按照同样的方式,使用Kafka的API来进行测试。
新建一个名称为“kafka-test”的Maven项目,加入以下依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.9</version>
</dependency>新建生产者的运行类,请见代码清单8-3。
代码清单8-3:codes\08\8.3\kafka-test\src\main\java\org\crazyit\cloud\ProducerMain.java
public class ProducerMain {
public static void main(String[] args) throws Exception {
// 配置信息
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
// 设置数据key的序列化处理类
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
// 设置数据value的序列化处理类
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
// 创建生产者实例
Producer<String, String> producer = new KafkaProducer<>(props);
// 创建一条新的记录,第一个参数为Topic名称
ProducerRecord record = new ProducerRecord<String, String>("my-topic", "userName", "Angus");
// 发送记录
producer.send(record);
producer.close();
}
}生产者的代码较RabbitMQ的简单,创建属性实例,直接使用配置实例创建Producer(生产者),再创建一个ProducerRecord(记录),最后直接发送。在创建记录时,指定了向“my-topic”投递消息,消息的key为“userName”,value为“Angus”。消息发送后,Kafka会在服务器上创建一个相应的Topic。运行代码清单8-3,将消息投递到Kafka服务器的Topic中,接下来可以使用命令查看服务器的Topic。
使用命令行工具进入kafka_2.11-0.11.0.0/bin/windows目录,输入命令“kafka-topics --list --zookeeper localhost:2181”,看到当前Kafka服务器的Topic,如图8-8所示。
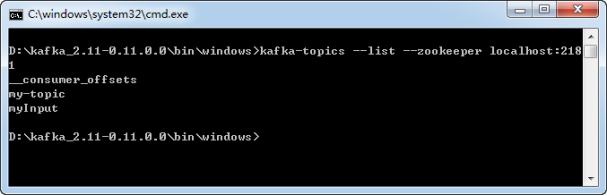
图8-8 查看Topic
如果想删除服务器上面的Topic,可使用“kafka-topics --delete --zookeeper localhost:2181 --topic my-topic”命令,但在默认情况下,执行该命令只是将Topic标记为删除,如果想真正删除Topic,需要修改config/server.properties文件,加入“delete.topic.enable=true”配置。
本例中生产者与消费同在一个项目,只是使用不同的启动类。前面小节在编写生产者时,指定消息发送到“my-topic”,消费者订阅该Topic,就可以获取到消息,详细请见代码清单8-4。
代码清单8-4:codes\08\8.3\kafka-test\src\main\java\org\crazyit\cloud\ConsumerMain.java
public class ConsumerMain {
public static void main(String[] args) {
// 配置信息
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
// 必须指定消费者组
props.put("group.id", "test");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 订阅 my-topic 的消息
consumer.subscribe(Arrays.asList("my-topic"));
// 到服务器中读取记录
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println("key: " + record.key() + ", value: " + record.value());
}
}
}
}设置了配置的信息后,创建一个KafkaConsumer实例,通过该实例订阅“my-topic”的消息,最后使用KafkaConsumer的poll方法获取服务器消息并输出。运地代码清单8-4,再运行代码清单8-5,可以看到输出如下:
key: userName, value: Angus在编写消费者时,需要指定消费者组的id,关于消费者组,由于Spring Cloud Stream中也涉及这个概念,因此需要特别说明一下。
消费者会为自己添加一个消费者组的标识,每一条发布到Topic的记录,都会被交付给消费者组的一个消费者实例。如果多个消费者实例拥有相同的消费者组,那么这些记录将会分配到各个消费者实例上,以达到负载均衡的目的。如果所有的消费者都有不同的消费者组,那么每一条记录都会被广播到全部的消费者进行处理。如果理解不了这段文字,请见图8-9。
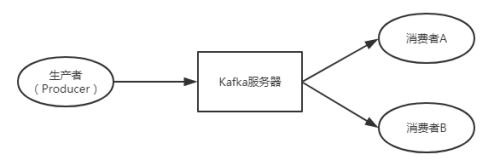
图8-9 消费者组
如图8-9,如果消费者A与消费者B属于同一个“消费者组”,那么当生产者发送一条消息过来时,仅会交给其中一个消费者处理;如果两个消费者不属于同一个消费者组,那么该消息都会发给他们(广播)进行处理。
看完上述内容,你们掌握Apache Kafka框架是怎样的呢的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/JavaLaw/blog/1588767



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



