基于谷歌街景多位数字识别技术的TensorFlow的车牌号识别系统是怎样的,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
过去几周我一直在涉足深度学习领域,尤其是卷积神经网络模型。最近,谷歌围绕街景多位数字识别技术发布了一篇不错的paper。该文章描述了一个用于提取街景门牌号的单个端到端神经网络系统。然后,作者阐述了基于同样的网络结构如何来突破谷歌验证码识别系统的准确率。 为了亲身体验神经网络的实现,我决定尝试设计一个可以解决类似问题的系统:车牌号自动识别系统。设计这样一个系统的原因有3点:
我应该能够参照谷歌那篇paper搭建一个同样的或者类似的网络架构:谷歌提供的那个网络架构在验证码识别上相当不错,那么讲道理的话,用它来识别车牌号应该也会很给力。拥有一个知名的网络架构将会大大地简化我学习CNNs的步骤。
我可以很容易地生成训练数据。训练神经网络存在一个很大的问题就是需要大量的标签样本。通常要训练好一个网络就需要几十万张标记过的图片。侥幸的是,由于UK车牌号相对一致,所以我可以合成训练数据。
好奇心。传统的车牌号自动识别系统依赖于自己编写算法来实现车牌定位,标准化,分割和字符识别等功能。照这样的话,实现这些系统的代码可能达到上千行。然而,我比较感兴趣的是,如何使用相对较少的代码和最少的专业领域知识来开发一个不错的系统。
开发该项目的环境要求有Python,Tensorflow,OpenCV和NumPy等软件。源代码在这里。
为了简化生成的训练图片,减少计算量,我决定该网络可操作的输入图片为128*64的灰度图。
选用128*64分辨率的图片作为输入,对于基于适当的资源和合理的时间训练来说足够小,对于车牌号读取来说也足够大。

为了在更大的图片中检测车牌号,采用了一个多尺度的滑窗来解决。

右边的图片是神经网络的输入图片,大小为128*64,而左边的图片则展示了在原始输入图片的上下文中的滑窗。
对于每个滑窗,网络都会输出:
输入图片中存在车牌的概率。(上边动画所显示的绿框)
每个位置上的字符的概率,比如针对7个可能位置中的每一个位置,网络都应该返回一个贯穿36个可能的字符的概率分布。(在这个项目中我假定车牌号恰好有7位字符,UK车牌号通常都这样)
考虑一个车牌存在当且仅当:
车牌完全包含在图片边界内。
车牌的宽度小于图片宽度的80%,且车牌的高度小于图片高度的87.5%。
车牌的宽度大于图片宽度的60%,或车牌的高度大于图片高度的60%。
为了检测这些号码,我们可以利用一个滑窗,每次滑动8个像素,而且在保证不丢失车牌的情况下提供一个缩放等级,缩放系数为$\sqrt{2}$,同时对于任何单个的车牌不会生成过量的匹配框。在后处理过程中会做一些复本(稍后解释)。
为了训练任何一个神经网络,必须提供一套拥有正确输出的训练数据。在这里表现为一套拥有期望输出的128*64大小的图片。这里给出一个本项目生成的训练数据的实例:

期望输出的第一部分表示网络应该输出的号码,第二部分表示网络应该输出的“存在”值。对于标记过的数据不存在的情况我在括号里作了解释。
生成图片的过程如下图所示:
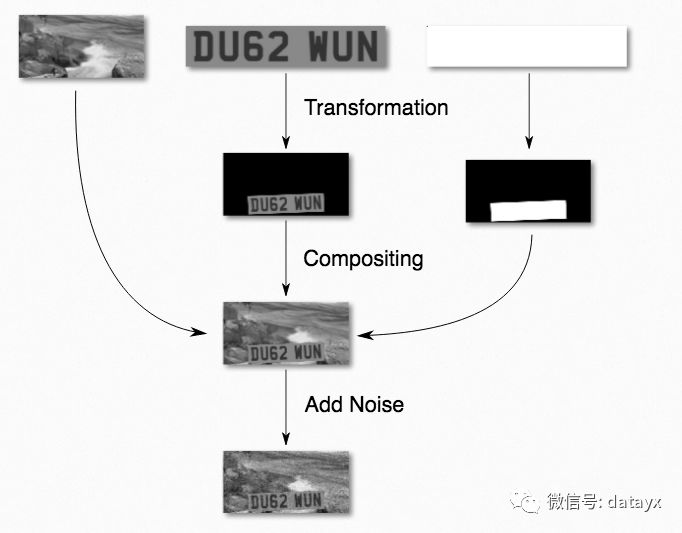
文本和车牌的颜色是随机选择的,但是文本颜色必须比车牌颜色更深一些。这是为了模拟真实场景的光线变化。最后再加入一些噪音,这样不仅能够解释真实传感器的噪音,而且能够避免过多依赖于锐化的轮廓边界而看到的将会是离焦的输入图片。
拥有背景是很重要的,这意味着网络必须学习分辨没有“欺骗”的车牌号边界:使用一个黑色背景为例,网络可能会基于非黑色来学习分辨车牌的位置,这会导致分不清楚真实图片里的小汽车。
背景图片来源于SUN database,
http://vision.cs.princeton.edu/projects/2010/SUN/
里面包含了超过10万张图片。重要的是大量的图片可以避免网络“记住”背景图片。
车牌变换采用了一种基于随机滚转、倾斜、偏转、平移以及缩放的仿射变换。每个参数允许的范围是车牌号可能被看到的所有情况的集合。比如,偏转比滚转允许变化更多(你更可能看到一辆汽车在拐弯而不是翻转到一边)。
生成图片的代码相对较短(大约300行)。可以从gen.py里读取。
使用的网络结构如下图所示:
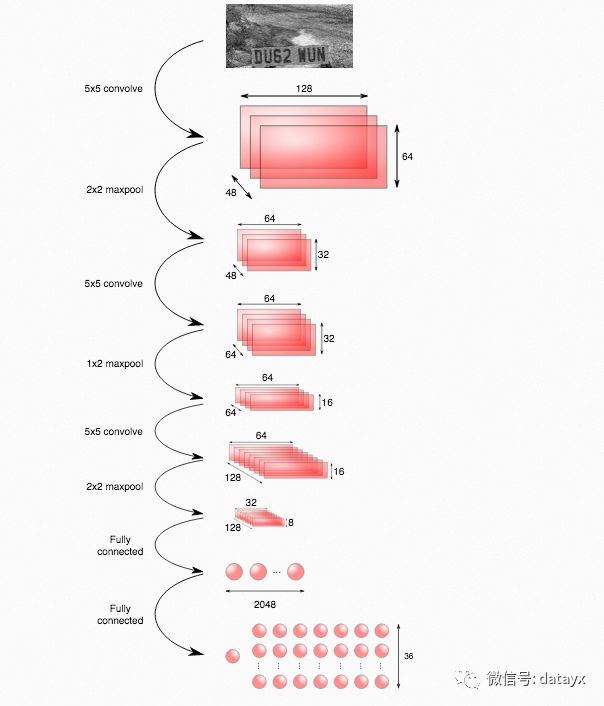
通过维基百科可以查看CNN模块的介绍。上面的网络结构实际上是基于Stark的这篇paper,关于这个结构它比谷歌的那篇paper给出了更多的细节。
https://vision.in.tum.de/_media/spezial/bib/stark-gcpr15.pdf
输出层有一个节点(左边)被用来作为车牌是否存在的指示器。剩下的节点用来编码一个特定车牌号的概率:图中的每一列与车牌号中的每一位号码一致,每一个节点给出与存在的字符相符合的概率。例如,位于第2列第3行的节点给出车牌号中第二个号码是字符c的概率。
除了输出层使用ReLU激活函数之外,所有层都采用深度神经网络的标准结构。指示存在的节点使用sigmoid激活函数,典型地用于二值输出。其他输出节点使用softmax贯穿字符(结果是每一列的概率之和为1),是模型化离散概率分布的标准方法。
定义网络结构的代码在model.py里。
根据标签和网络输出的交叉熵来定义损失函数。为了数值稳定性,利用softmax_cross_entropy_with_logits和sigmoid_cross_entropy_with_logits将最后一层的激活函数卷入交叉熵的计算。关于对交叉熵详细而直观的介绍可以参考Michael A. Nielsen的free online book中查看这一节。
使用一块nVidia GTX 970花费大约6小时来训练(train.py),通过CPU的一个后台进程来运行训练数据的生成。
事实上为了从输入图片中检测和识别车牌号,搭建了类似于上面的一个检测网络,并采用了多位置和多尺度的128*64滑窗,这在滑窗那一节有所描述。
检测网络和训练网络的不同点在于最后两层采用了卷积层而不是全连接层,这样可以使检测网络的输入图片大小不仅限于128*64。将一张完整的图片以一种特定尺寸扔进网络中,然后返回一张每个“像素”拥有一个存在/字符概率值的图片。因为相邻的滑窗会共享很多卷积特征,所以将这些特定图片卷进同一个网络可以避免多次计算同样的特征。
可视化输出的“存在”部分会返回如下所示的图片:

图上的边界框是网络检测存在车牌概率大于99%的区域。设置高阈值的原因是为了解释训练过程中引进的一个偏差:几乎过半的训练图片都包含一个车牌,然而真实场景中有车牌的图片很少见,所以如果设置阈值为50%的话,那么检测网络的假阳性就会偏高。
在检测网络输出之后,我们使用非极大值抑制(NMS)的方法来过滤掉冗余的边界框:

首先将重叠的矩形框分组,然后针对每一组输出:
所有边界框的交集。
找出组中车牌存在概率最高的边界框对应的车牌号。
下图所示文章最开始给出的那张车牌图片的检测结果:

哎呦,字符R被误检成了P。上图中车牌存在概率最大的滑窗如下图所示:

第一眼似乎以为这个对于检测器来说是小菜一碟,然而事实证明这是过拟合的问题。下图给出了生成训练图片时所用的车牌号中R的字体:

注意字符R腿的角度是如何不同于输入图片中字符R腿的角度。由于网络仅仅学习过上面的那种R字体,因此当遇到不同字体的R字符时就迷惑了。为了测试这种假设,我在GIMP中改进了图片,使得其更接近于训练时的字体:

改进之后,检测得到了正确的输出:

检测的源码在这里detect.py
我已经开源了一个拥有相对较短代码(大约800行)的系统,它不用导入任何特定领域的库以及不需要太多特定领域的知识,就能够实现车牌号自动识别。此外,我还通过在线合成图片的方法解决了上千张训练图片的需求问题(通常是在深度神经网络的情况下)。
另一方面,我的系统也存在一些缺点:
只适用于特定车牌号。尤其是,网络结构明确假定了输出只有7个字符。
只适用于特定字体。
速度太慢。该系统运行一张适当尺寸的图片要花费几秒钟。
为了解决第1个问题,谷歌团队将他们的网络结构的高层拆分成了多个子网络,每一个子网络用于假定输出号码中的不同号码位。还有一个并行的子网络来决定存在多少号码。我觉得这种方法可以应用到这儿,但是我没有在这个项目中实现。
关于第2点我在上面举过例子,由于字体的稍微不同而导致字符R的误检。如果尝试着检测US车牌号的话,误检将会更加严重,因为US车牌号字体类型更多。一个可能的解决方案就是使得训练数据有更多不同的字体类型可选择,尽管还不清楚需要多少字体类型才能成功。
第3点提到的速度慢的问题是扼杀许多应用的cancer:在一个相当强大的GPU上处理一张适当尺寸的输入图片就要花费几秒钟。我认为不引进一种级联式结构的检测网络就想避开这个问题是不太可能的,比如Haar级联,HOG检测器,或者一个更简单的神经网络。
我很有兴趣去尝试和其他机器学习方法的比较会怎样,特别是姿态回归看起来有希望,最后可能会附加一个最基本的分类阶段。如果使用了像scikit-learn这样的机器学习库,那么应该同样简单。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





