本文小编为大家详细介绍“Kubernetes的Device Plugin设计是怎样的”,内容详细,步骤清晰,细节处理妥当,希望这篇“Kubernetes的Device Plugin设计是怎样的”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
最近在调研Kubernetes的GPU调度和运行机制,发现传统的alpha.kubernetes.io/nvidia-gpu即将在1.11版本中下线,和GPU相关的调度和部署的代码将彻底从主干代码中移除。
取而代之的是通过Extended Resource+Device Plugin两个Kubernetes的内置模块,外加由设备提供商实现的相应Device Plugin, 完成从设备的集群级别调度至工作节点,到设备与容器的实际绑定。
首先思考的第一个问题是为什么进入alpha.kubernetes.io/nvidia-gpu主干一年之久的GPU功能彻底移除?
OutOfTree是Kubernetes一个很好的理念,之前的Cloud Provider的重构也是类似的工作。对于Kubernetes来说,不做瑞士军刀,专注于自身核心和通用能力,而将像GPU,InfiniBand,FPGA和公共云能力的工作完全交给社区和领域专家。这样一方面可以降低软件自身使用的复杂度,减小稳定性风险,另外OutOfTree分开迭代也能够更灵活实现的功能升级。
而开放的软件架构设计和标准也调动了社区参与的积极性,而活跃的社区其实是Kubernetes打赢容器调度框架之战的核心法宝。
先来简要介绍一下kubernetes这两个模块:
Extended Resource: 一种自定义资源扩展的方式,将资源的名称和总数量上报给API server,而Scheduler则根据使用该资源pod的创建和删除,做资源可用量的加减法,进而在调度时刻判断是否有满足资源条件的节点。目前这里的Extended Resource的增加和减少单元必须是整数,比如你可以分配1个GPU,但是不能分配0.5个GPU。该功能由于只是替代了Opaque integer resources,做了些更名的工作,所以在1.8已经是稳定的状态了。但是当integer这个关键词被移除,也引发我们的想象,未来会不会有0.5存在的可能性?
Device Plugin:通过提供通用设备插件机制和标准的设备API接口。这样设备厂商只需要实现相应的API接口,无需修改Kubelet主干代码,就可以实现支持GPU、FPGA、高性能 NIC、InfiniBand 等各种设备的扩展。该能力在Kubernetes 1.8和1.9版本处于Alpha版本,在1.10会进入Beta版本。
应该说这个功能目前还比较新,需要通过feature gate打开, 即配置 --feature-gates=DevicePlugins=true
实际上Device plugins实际上是简单的grpc server,需要实现以下两个方法 ListAndWatch和Allocate,并监听在/var/lib/kubelet/device-plugins/目录下的Unix Socket,比如/var/lib/kubelet/device-plugins/nvidia.sock
service DevicePlugin {
// returns a stream of []Device
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
}其中:
ListAndWatch: Kubelet会调用该API做设备发现和状态更新(比如设备变得不健康)
Allocate: 当Kubelet创建要使用该设备的容器时, Kubelet会调用该API执行设备相应的操作并且通知Kubelet初始化容器所需的device,volume和环境变量的配置。
插件启动时,以grpc的形式通过/var/lib/kubelet/device-plugins/kubelet.sock向Kubelet注册,同时提供插件的监听Unix Socket,API版本号和设备名称(比如nvidia.com/gpu)。Kubelet将会把这些设备暴露到Node状态中,以Extended Resource的要求发送到API server中,后续Scheduler会根据这些信息进行调度。
插件启动后,Kubelet会建立一个到插件的listAndWatch长连接,当插件检测到某个设备不健康的时候,就会主动通知Kubelet。此时如果这个设备处于空闲状态,Kubelet就会将其挪出可分配列表;如果该设备已经被某个pod使用,Kubelet就会将该Pod杀掉
插件启动后可以利用Kubelet的socket持续检查Kubelet的状态,如果Kubelet重启,插件也会相应的重启,并且重新向Kubelet注册自己
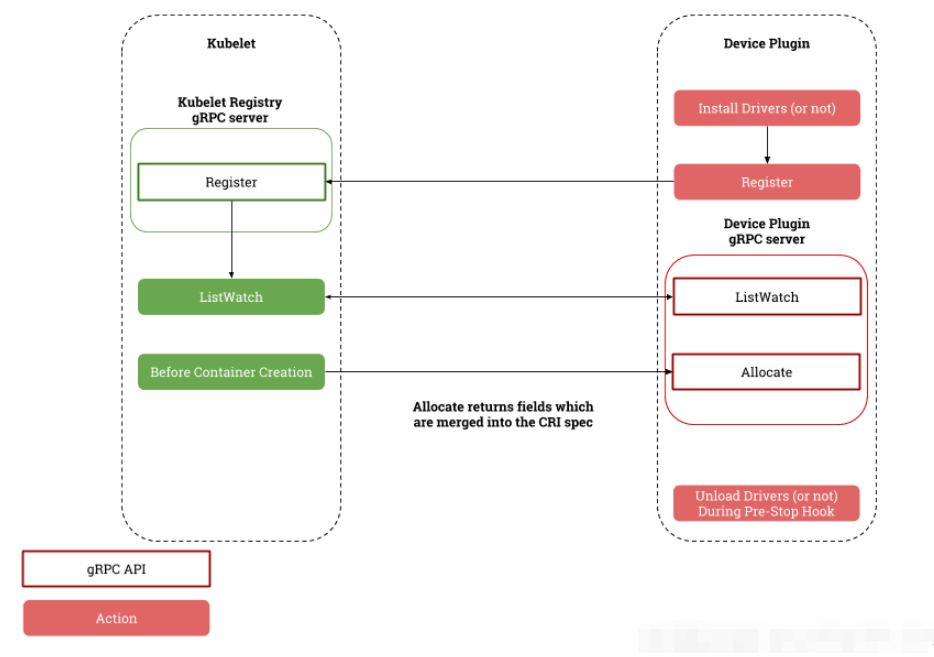
一般可以支持daemonset和非容器化的部署,目前官方推荐使用deamonset部署。
NVIDIA 提供了一个基于 Device Plugins 接口的 GPU 设备插件NVIDIA/k8s-device-plugin, 从用户角度变得更加简单了。比起传统的alpha.kubernetes.io/nvidia-gpu, 不再需要使用volumes指定CUDA需要使用的库。
apiVersion: apps/v1
kind: Deployment
metadata:
name: tf-notebook
labels:
app: tf-notebook
spec:
template: # define the pods specifications
metadata:
labels:
app: tf-notebook
spec:
containers:
- name: tf-notebook
image: tensorflow/tensorflow:1.4.1-gpu-py3
resources:
limits:
nvidia.com/gpu: 1GCP也提供了一个GPU设备插件实现,但是只支持运行在Google Container Engine的平台上,可以通过container-engine-accelerators了解
网卡造商Solarflare也实现了自己的设备插件sfc-device-plugin, 可以通过demo体验用户感受。
读到这里,这篇“Kubernetes的Device Plugin设计是怎样的”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/yunqi/blog/1633432



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



