esproc:
| A | |
| 1 | =now() |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt") |
| 3 | =A2.import@t() |
| 4 | =A3.derive(age(BIRTHDAY):Age,NAME+""+SURNAME:Fullname) |
| 5 | =interval@ms(A1,now()) |
A4:我们用T表示序表。T.derive()表示增加字段。这里用age(日期)计算出年龄,作为Age字段。用NAME,SURNAME得到Fullname。
A5:计算运算时间(interval:计算时间间隔。@ms表示以毫秒为单位)
python:
import time
import pandas as pd
import datetime
s = time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
today = datetime.datetime.today().year
data["Age"] = today-pd.to_datetime(data["BIRTHDAY"]).dt.year
data["Fullname"]=data["NAME"]+data["SURNAME"]
print(data)
e = time.time()
print(e-s)
计算出BIETHDAY字段的值(日期)距今天的年数,作为年龄字段。用NAME+SURNAME作为Fullname字段
结果
esproc:

python:

| 耗时 | |
| esproc | 0.008 |
| python | 0.020 |
esproc:
| A | |
| 1 | =now() |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt") |
| 3 | =A2.import@t() |
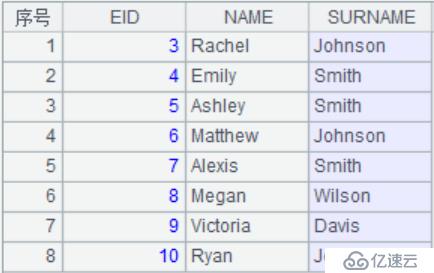
| 4 | =A3.new(#1,#2,#3).to(3:10) |
| 5 | =interval@ms(A1,now()) |
A4:T.new()表示新建序表。这里以第1,2,3个字段作为新表的字段。T.A,表示取出序列中包含的行号。
python:
import time
import pandas as pd
import datetime
s = time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
data = data.iloc[2:10,:3]
print(data)
e = time.time()
print(e-s)
使用df.iloc[]切片获得3~10条记录,前三个字段(dataframe的字段号和记录号都是从0开始计数的)。
结果:
esproc:
python:

| 耗时 | |
| esproc | 0.008 |
| python | 0.010 |
esproc:
| A | |
| 1 | =now() |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt") |
| 3 | =A2.import@t() |
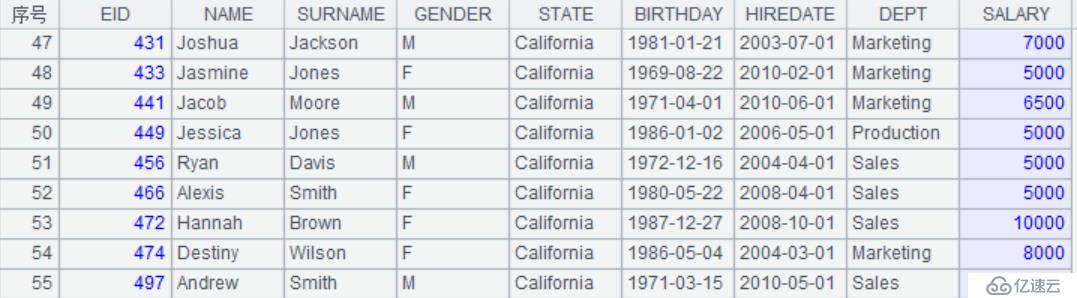
| 4 | =A3.select(STATE=="California") |
| 5 | =interval@ms(A1,now()) |
A4:T.select()筛选符合条件的记录。这里是筛选STATE=="California"为真的记录
python:
import time
import pandas as pd
import datetime
s = time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
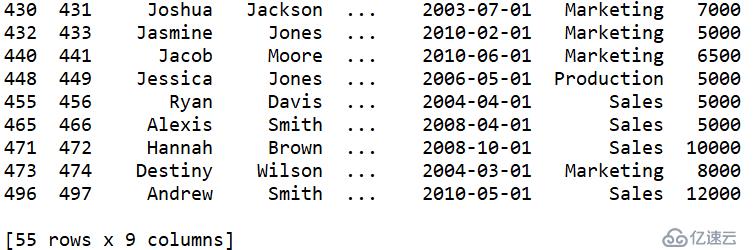
data = data[data['STATE']=="California"]
print(data)
e = time.time()
print(e-s)
取出data['STATE']=="California"的记录
结果:
esproc:
python:
| 耗时 | |
| esproc | 0.007 |
| python | 0.028 |
| A | |
| 1 | =now() |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt") |
| 3 | =A2.import@t() |
| 4 | =A3.min(SALARY) |
| 5 | =A3.max(SALARY) |
| 6 | =A3.avg(SALARY) |
| 7 | =A3.sum(SALARY) |
| 8 | =A3.(SALARY).median() |
| 9 | =A3.(float(SALARY)).variance() |
| 10 | =interval@ms(A1,now()) |
A4:T.min()计算字段最小值
A5:T.max()计算字段最大值
A6:T.avg()计算字段平均值
A7:T.sum()计算字段总和
A8:计算字段中位数。A.median(k:n)函数,参数全省略时,如果序列长度是奇数返回中间位置值;如果序列长度是偶数返回中间两个值的平均值。
A9:T.variance()计算字段方差。
python
s = time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
min = data["SALARY"].min()
max = data["SALARY"].max()
avg = data["SALARY"].mean()
sum = data["SALARY"].sum()
median = data["SALARY"].median()
var = data["SALARY"].var()
print(min,max,avg,sum,median,var)
e = time.time()
print(e-s)
df[字段名]表示取得字段。min(),max(),mean(),sum(),median(),var()分别计算最小值,最大值,平均数,总和,中位数,方差。
结果
| 常用计算 | esproc | python | 说明 |
| 最小值 | 3000 | 3000 | |
| 最大值 | 16000 | 16000 | |
| 平均值 | 7395 | 7395.0 | |
| 总和 | 3697500 | 3697500 | |
| 中位数 | 7000.0 | 7000.0 | |
| 方差 | 5324475 | 5335145.29 | 总体方差和样本方差的区别 |
| 耗时 | 0.004 | 0.007 |
esproc:
| A | |
| 1 | =now() |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt") |
| 3 | =A2.import@t() |
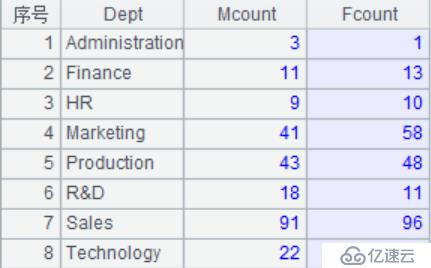
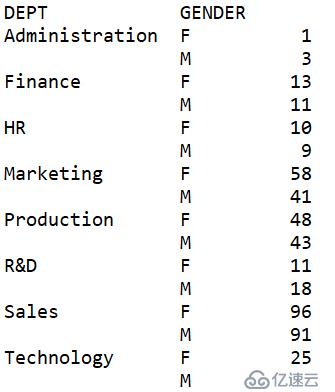
| 4 | =A3.groups(DEPT:Dept;count(GENDER=="M"):Mcount, count(GENDER=="F"):Fcount) |
| 5 | =interval@ms(A1,now()) |
A4:T.groups()表示以DEPT分组,计算GENDER==“M”或GENDER==“F”的值,得到各部门男女员工的数量。
python
s = time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
group = data.groupby(['DEPT','GENDER']).size()
print(group)
e = time.time()
print(e-s)
截取GENDER==‘M’或者GENDER==‘F’的切片以DEPT通过goupby()函数得到以DEPT的分组。最后用size()函数得到结果。
结果:
esproc:
python:
| 耗时 | |
| esproc | 0.004 |
| python | 0.008 |
esproc:
| A | |
| 1 | =now() |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt") |
| 3 | =A2.import@t() |
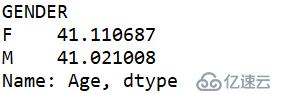
| 4 | =A3.groups(GENDER;avg(age(BIRTHDAY)):Age) |
| 5 | =interval@ms(A1,now()) |
A4:T.groups()用来分组,avg()计算平均值,age()根据日期计算时间间隔。
python
s = time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
data["Age"] = today-pd.to_datetime(data["BIRTHDAY"]).dt.year
avg_age = data.groupby('GENDER')['Age'].mean()
print(avg_age)
e = time.time()
print(e-s)
计算得到Age字段。然后用groupby()函数以GENDER分组,最后通过mean()函数得到平均值。
结果:
esproc:

python:
| 耗时 | |
| esproc | 0.005 |
| python | 0.008 |
esproc:
| A | |
| 1 | =now() |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt") |
| 3 | =A2.import@t() |
| 4 | =a=0,A3.max(a=if(SALARY>SALARY[-1],a+1,0)) |
| 5 | =interval@ms(A1,now()) |
A4:if(condition,x1,x2)表示如果条件成立,if语句的值为x1,否则值为x2,在这儿计算如果SALARY比前一个员工薪水高的话a=a+1。从而得到A3.(a),其中a随着if语句不断的变化。最后得到一个序列,max()函数得到最大值。
python
s = time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
a=0 ; m=0
for i in data['SALARY'].shift(0)>data['SALARY'].shift(1):
a=0 if i==False else a+1
m = a if m < a else m
print(m)
e = time.time()
print(e-s)
df.shift(0)表示当前记录,df.shift(n)表示前面第n条记录,data['SALARY'].shift(0)>data['SALARY'].shift(1) 得到pandas的series结构。循环如果为假(False)表示当前记录小于或等于上一条记录,把a置0,如果为真则加1。m的作用:当m<a时,把a赋值给m,否则m不变,最终得到a的最大值。
结果:
| 最大人数 | 耗时 | |
| esproc | 4 | 0.005 |
| python | 4 | 0.008 |
esproc:
| A | B | |
| 1 | =now() | |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE_nan.txt") | |
| 3 | =A2.import@t() | |
| 4 | for A3.fno() | >A3.sort(rand()).to(5+rand(6)).field(A4,null) |
| 5 | =interval@ms(A1,now()) |
A4:T.fno()得到序表的字段数量。
B4:T.field(f,x)将x序列中的成员依次赋值给A中第F个字段的字段值或者字符串参数F的值。F<0时从后往前排。F越界和不存时不执行
python:
s = time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
for i in data.columns:
for j in range(random.randint(5,10)):
data[i][random.randint(0,500)]=np.nan
print(data)
e = time.time()
print(e-s)
循环所有的字段,随机循环5~10次,将字段的某个随机值设置成np.nan
结果:
| 耗时 | |
| esproc | 0.008 |
| python | 0.710 |
esproc:
| A | |
| 1 | =now() |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE_nan.txt") |
| 3 | =A2.import@t() |
| 4 | =A3.select(!~.array().pos(null)) |
| 5 | =interval@ms(A1,now()) |
A4:筛选null所在位置为空的记录,即不包含null的记录。用r表示记录,r.array()表示把r中的字段值返回成序列。A.pos()获得序列成员序号。
python:
s = time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE_nan.txt",sep="\t")
data = data.dropna()
print(data)
e = time.time()
print(e-s)
使用dropna()函数得到不包含np.nan的记录
结果:


| 耗时 | |
| esproc | 0.003 |
| python | 0.033 |
esproc:
| A | B | |
| 1 | =now() | |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE_nan.txt") | |
| 3 | =A2.import@t() | |
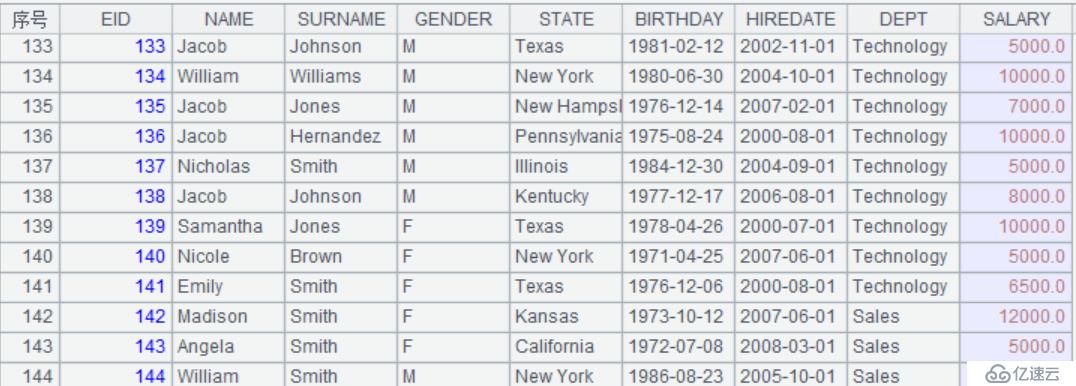
| 4 | >A3.field("EID",to(A3.len())) | |
| 5 | for 2,A3.fno() | =A3.select(!~.field(A5) ) |
| 6 | =A3\B5 | |
| 7 | >B5.run(~.field(A5,B6(rand(B6.len())+1).field(A5))) | |
| 8 | =interval@ms(A1,now()) |
A4:T.field(F,A) 将A序列中的成员依次赋值给T中第F个字段的字段值或者字符串参数F的值。
B5:筛选字段为null的记录
B6:差集,得到不为null的记录
B7:这里需要特别注意一下field()函数,r.field(F)取得记录的第F个字段的字段值或者字符串参数F的值。r.field(F,X) 修改记录r中第F个字段的字段值或者字符串参数F的值为x。A3.select(#${A5}==null)取出A3中某个字段为null的记录序列,用run()函数循环修改该序列中的每条记录。
python:
s = time.time()
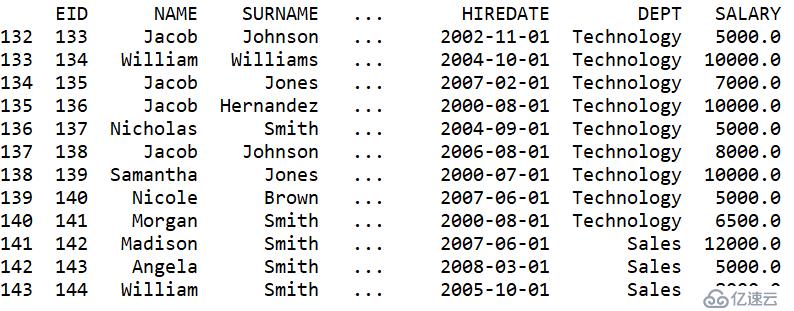
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE_nan.txt",sep="\t")
data['EID']=pd.Series([i for i in range(1,len(data)+1)])
for col in data.columns:
nonan_list = list(data[col][~pd.isna(data[col])])
fill_list = [nonan_list[random.randint(0,len(nonan_list))] for i in range(len(data[col][pd.isna(data[col])]))]
data[col][pd.isna(data[col])]=fill_list
e = time.time()
print(e-s)
将字段名为EID的值修改为递增的序列。这里用pd.Series()生成。
循环所有字段。df[col][pd.isna(df)]得到df中包含nan的值。~表示非。nonan_list表示当前列不包含nan的所有值组成的list。fill_list表示随机生成的要填充nan的值的list。
将fill_list中的值赋值给包含nan的记录。
结果:
esproc:
python
| 耗时 | |
| esproc | 0.008 |
| python | 0.144 |
esproc:
| A | B | |
| 1 | =now() | |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE_nan.txt") | |
| 3 | =A2.import@t() | |
| 4 | >A3.field("EID",to(1,A3.len())) | |
| 5 | for 2,A3.fno()-1 | =A3.group(!~.field(A5)) |
| 6 | =B5(1).(~.field(A5)) | |
| 7 | >B5(2).run(~.field(A5,B6(rand(B6.len())+1))) | |
| 8 | =A3.avg(SALARY) | |
| 9 | =A3.select(!SALARY).run(~.field("SALARY",A8)) | |
| 10 | =interval@ms(A1,now()) |
上例中,B5,B6的运算会导致把序列遍历两遍,这里进行了改进
B5:A.group(xi) 将序列/排列按照一个或多个字段/表达式进行等值分组,结果为组集构成的序列。这里是将序表分成两组,第一组为该字段不包含null的,第二组为包含null的。
B6:取得该字段去重后的字段值
B7:这里需要特别注意一下field()函数,r.field(F)取得记录的第F个字段的字段值或者字符串参数F的值。r.field(F,X) 修改记录r中第F个字段的字段值或者字符串参数F的值为x。r.run(xi,…),针对记录r计算表达式x,最后返回记录r。此函数通常用于修改r的字段值
B9:和B7的原理一样,利用field()函数修改SALARY的字段值为A8中计算出来的平均值。
python:
s = time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE_nan.txt",sep="\t")
data['EID']=pd.Series([i for i in range(1,len(data)+1)])
for col in list(data.columns)[1:-1]:
nonan_list = list(data[col][~pd.isna(data[col])])
fill_list = [nonan_list[random.randint(0,len(nonan_list))] for i in range(len(data[col][pd.isna(data[col])]))]
data[col][pd.isna(data[col])]=fill_list
data['SALARY'].fillna(data['SALARY'].mean(),inplace=True)
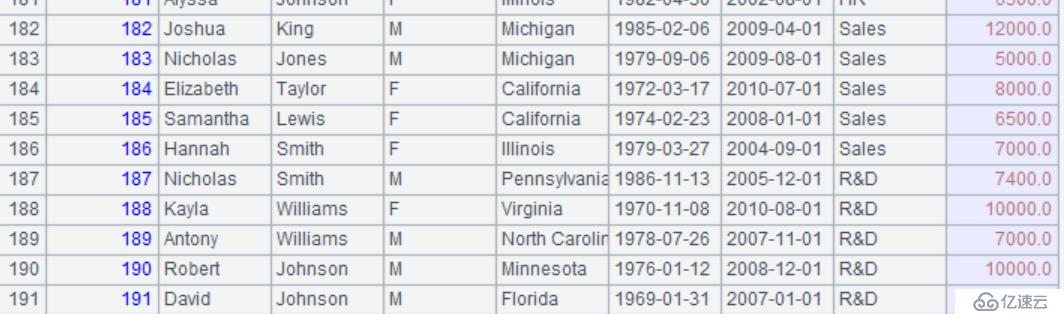
print(data.loc[180:190])
print(e-s)
将字段名为EID的值修改为递增的序列。这里用pd.Series()生成。
循环所有字段第一到倒数第二个字段。df[col][pd.isna(df)]得到df中包含nan的值。~表示非。nonan_list表示当前列不包含nan的所有值组成的list。fill_list表示随机生成的要填充nan的值的list。
将fill_list中的值赋值给包含nan的记录。
df.fillna(df[s].mean())表示用字段s的平均值填充缺失值。
结果:
esproc:
python
| 耗时 | |
| esproc | 0.006 |
| python | 0.165 |
小结:本节我们用11个例子对数据进行简单的计算,esproc和python都用到了比较多的函数,还用到了一些相对复杂的组合应用,这就不得不说esproc现阶段的一个缺点了,查阅资料和使用案例相对于python太少了,原因就是使用者太少。但是在描述效率和执行效率方面,esproc的优势太明显了,因此我们要多使用esproc提高工作效率,同时也可以完善esproc的缺点。esproc中的函数功能很强大,需要不断的使用,来充分理解函数的用法,达到熟能生巧最终精通的地步。
EMPLOYEE.txt
EMPLOYEE_nan.txt
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





