本篇内容主要讲解“Linux日志对接Kibana如何进行配置与部署”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Linux日志对接Kibana如何进行配置与部署”吧!
在腾讯云帐号下,申请一台CVM(Linux操作系统)、一个ElasticSearch集群(后面简称ES),使用最简配置即可;申请的CVM和ES,必须在同一个VPC的同一个子网下。
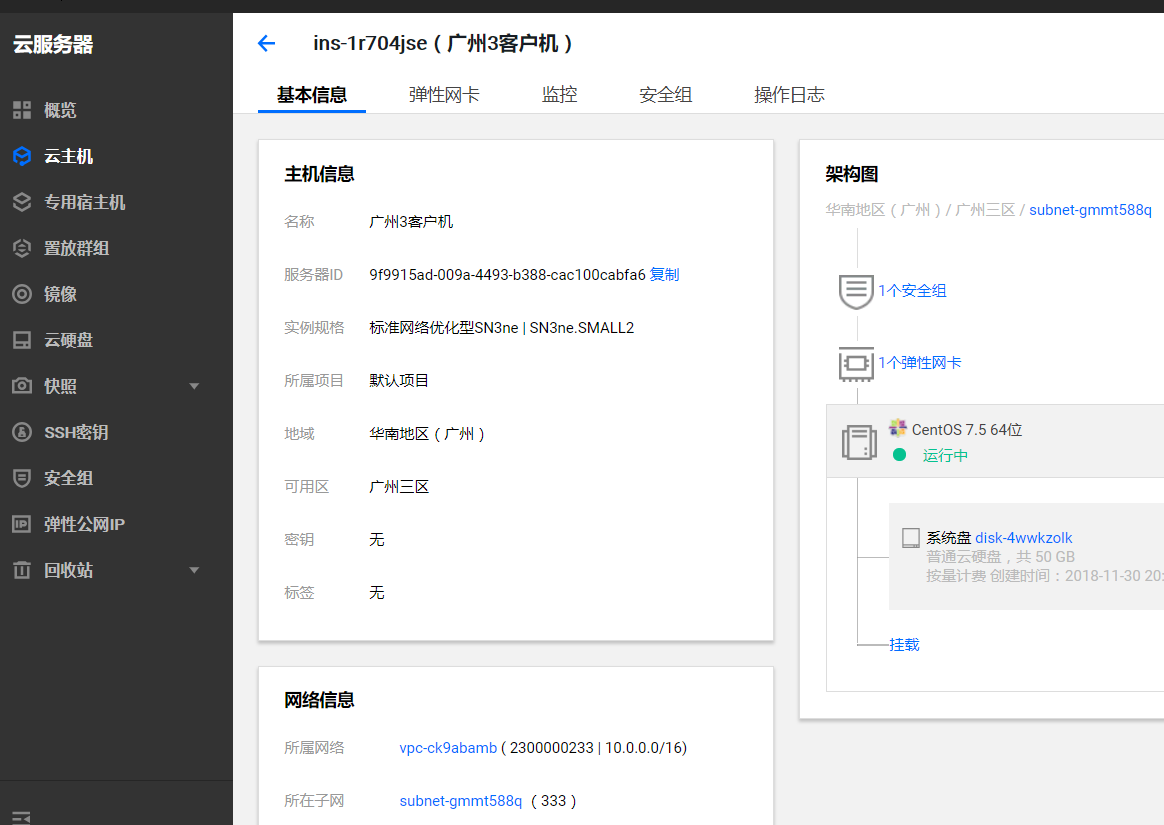 CVM详情信息
CVM详情信息
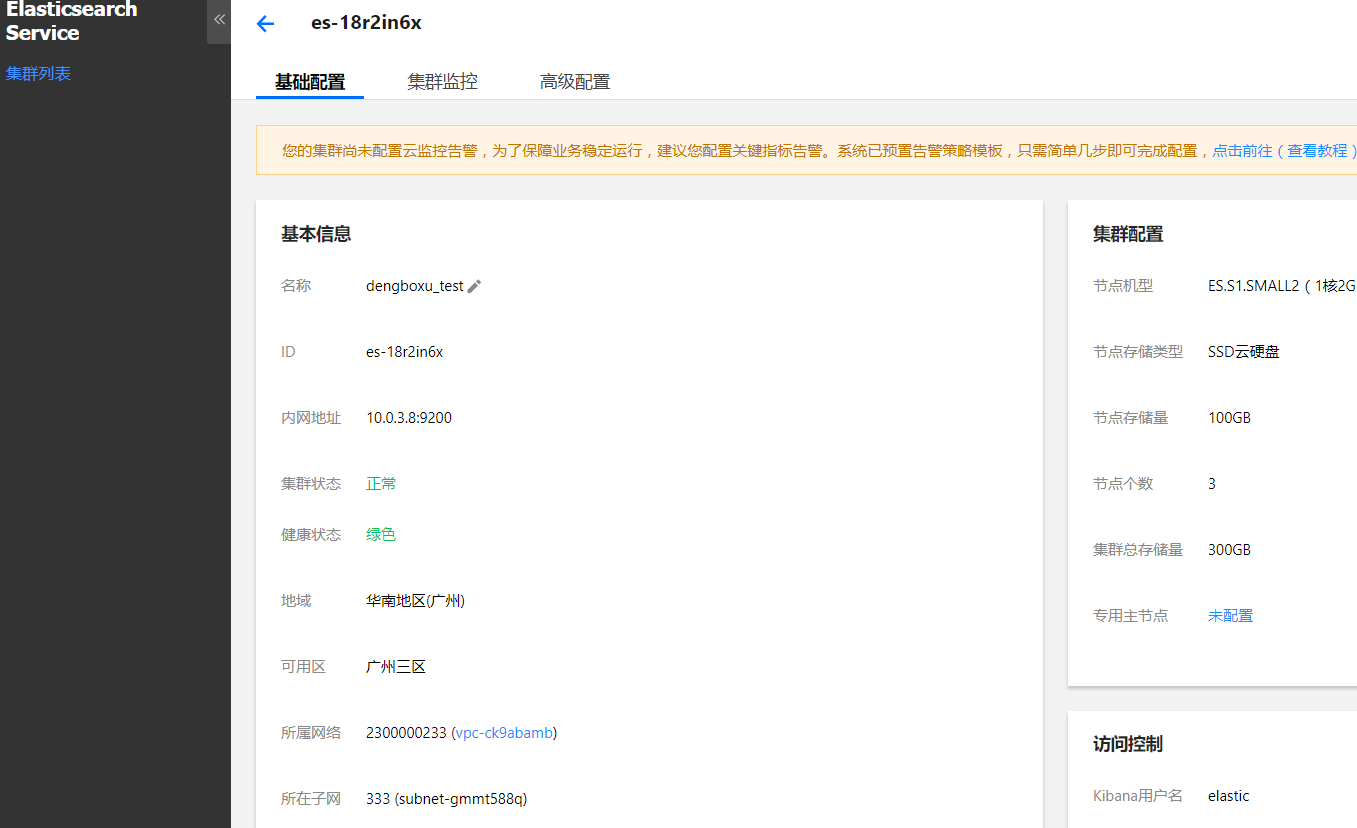 ElasticSearch详情信息
ElasticSearch详情信息
为了将Linux日志提取到ES中,我们需要使用Filebeat工具。Filebeat是一个日志文件托运工具,在你的服务器上安装客户端后,Filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读),并且转发这些信息到ElasticSearch或者logstarsh中存放。当你开启Filebeat程序的时候,它会启动一个或多个探测器(prospectors)去检测你指定的日志目录或文件,对于探测器找出的每一个日志文件,Filebeat启动收割进程(harvester),每一个收割进程读取一个日志文件的新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后Filebeat会发送集合的数据到你指定的地点。
官网简介:https://www.elastic.co/products/beats/filebeat
首先,登录待接管日志的CVM,在CVM上下载Filebeat工具:
[root@VM_3_7_centos ~]# cd /opt/
[root@VM_3_7_centos opt]# ll
total 4
drwxr-xr-x. 2 root root 4096 Sep 7 2017 rh
[root@VM_3_7_centos opt]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.2-x86_64.rpm
--2018-12-10 20:24:26-- https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.2-x86_64.rpm
Resolving artifacts.elastic.co (artifacts.elastic.co)... 107.21.202.15, 107.21.127.184, 54.225.214.74, ...
Connecting to artifacts.elastic.co (artifacts.elastic.co)|107.21.202.15|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 12697788 (12M) [binary/octet-stream]
Saving to: ‘filebeat-6.2.2-x86_64.rpm’
100%[=================================================================================================>] 12,697,788 160KB/s in 1m 41s
2018-12-10 20:26:08 (123 KB/s) - ‘filebeat-6.2.2-x86_64.rpm’ saved [12697788/12697788]然后,进行安装filebeat:
[root@VM_3_7_centos opt]# rpm -vi filebeat-6.2.2-x86_64.rpm
warning: filebeat-6.2.2-x86_64.rpm: Header V4 RSA/SHA512 Signature, key ID d88e42b4: NOKEY
Preparing packages...
filebeat-6.2.2-1.x86_64
[root@VM_3_7_centos opt]#至此,Filebeat安装完成。
进入Filebeat配置文件目录:/etc/filebeat/
[root@VM_3_7_centos opt]# cd /etc/filebeat/
[root@VM_3_7_centos filebeat]# ll
total 108
-rw-r--r-- 1 root root 44384 Feb 17 2018 fields.yml
-rw-r----- 1 root root 52193 Feb 17 2018 filebeat.reference.yml
-rw------- 1 root root 7264 Feb 17 2018 filebeat.yml
drwxr-xr-x 2 root root 4096 Dec 10 20:35 modules.d
[root@VM_3_7_centos filebeat]#其中,filebeat.yml就是我们需要修改的配置文件。建议修改配置前,先备份此文件。
然后,确认需要对接ElasticSearch的Linux的日志目录,我们以下图(/var/log/secure)为例。
 /var/log/secure日志文件
/var/log/secure日志文件
使用vim打开/etc/filebeat/filebeat.yml文件,修改其中的:
1)Filebeat prospectors类目中,enable默认为false,我们要改为true
2)paths,默认为/var/log/*.log,我们要改为待接管的日志路径:/var/log/secure
3)Outputs类目中,有ElasticSearchoutput配置,其中hosts默认为"localhost:9200",需要我们手工修改为上面申请的ES子网地址和端口,即**"10.0.3.8:9200"**。
修改好上述内容后,保存退出。
修改好的配置文件全文如下:
[root@VM_3_7_centos /]# vim /etc/filebeat/filebeat.yml
[root@VM_3_7_centos /]# cat /etc/filebeat/filebeat.yml
###################### Filebeat Configuration Example #########################
# This file is an example configuration file highlighting only the most common
# options. The filebeat.reference.yml file from the same directory contains all the
# supported options with more comments. You can use it as a reference.
#
# You can find the full configuration reference here:
# https://www.elastic.co/guide/en/beats/filebeat/index.html
# For more available modules and options, please see the filebeat.reference.yml sample
# configuration file.
#=========================== Filebeat prospectors =============================
filebeat.prospectors:
# Each - is a prospector. Most options can be set at the prospector level, so
# you can use different prospectors for various configurations.
# Below are the prospector specific configurations.
- type: log
# Change to true to enable this prospector configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/secure
#- c:\programdata\elasticsearch\logs\*
# Exclude lines. A list of regular expressions to match. It drops the lines that are
# matching any regular expression from the list.
#exclude_lines: ['^DBG']
# Include lines. A list of regular expressions to match. It exports the lines that are
# matching any regular expression from the list.
#include_lines: ['^ERR', '^WARN']
# Exclude files. A list of regular expressions to match. Filebeat drops the files that
# are matching any regular expression from the list. By default, no files are dropped.
#exclude_files: ['.gz$']
# Optional additional fields. These fields can be freely picked
# to add additional information to the crawled log files for filtering
#fields:
# level: debug
# review: 1
### Multiline options
# Mutiline can be used for log messages spanning multiple lines. This is common
# for Java Stack Traces or C-Line Continuation
# The regexp Pattern that has to be matched. The example pattern matches all lines starting with [
#multiline.pattern: ^\[
# Defines if the pattern set under pattern should be negated or not. Default is false.
#multiline.negate: false
# Match can be set to "after" or "before". It is used to define if lines should be append to a pattern
# that was (not) matched before or after or as long as a pattern is not matched based on negate.
# Note: After is the equivalent to previous and before is the equivalent to to next in Logstash
#multiline.match: after
#============================= Filebeat modules ===============================
filebeat.config.modules:
# Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: false
# Period on which files under path should be checked for changes
#reload.period: 10s
#==================== Elasticsearch template setting ==========================
setup.template.settings:
index.number_of_shards: 3
#index.codec: best_compression
#_source.enabled: false
#================================ General =====================================
# The name of the shipper that publishes the network data. It can be used to group
# all the transactions sent by a single shipper in the web interface.
#name:
# The tags of the shipper are included in their own field with each
# transaction published.
#tags: ["service-X", "web-tier"]
# Optional fields that you can specify to add additional information to the
# output.
#fields:
# env: staging
#============================== Dashboards =====================================
# These settings control loading the sample dashboards to the Kibana index. Loading
# the dashboards is disabled by default and can be enabled either by setting the
# options here, or by using the `-setup` CLI flag or the `setup` command.
#setup.dashboards.enabled: false
# The URL from where to download the dashboards archive. By default this URL
# has a value which is computed based on the Beat name and version. For released
# versions, this URL points to the dashboard archive on the artifacts.elastic.co
# website.
#setup.dashboards.url:
#============================== Kibana =====================================
# Starting with Beats version 6.0.0, the dashboards are loaded via the Kibana API.
# This requires a Kibana endpoint configuration.
setup.kibana:
# Kibana Host
# Scheme and port can be left out and will be set to the default (http and 5601)
# In case you specify and additional path, the scheme is required: http://localhost:5601/path
# IPv6 addresses should always be defined as: https://[2001:db8::1]:5601
#host: "localhost:5601"
#============================= Elastic Cloud ==================================
# These settings simplify using filebeat with the Elastic Cloud (https://cloud.elastic.co/).
# The cloud.id setting overwrites the `output.elasticsearch.hosts` and
# `setup.kibana.host` options.
# You can find the `cloud.id` in the Elastic Cloud web UI.
#cloud.id:
# The cloud.auth setting overwrites the `output.elasticsearch.username` and
# `output.elasticsearch.password` settings. The format is `<user>:<pass>`.
#cloud.auth:
#================================ Outputs =====================================
# Configure what output to use when sending the data collected by the beat.
#-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["10.0.3.8:9200"]
# Optional protocol and basic auth credentials.
#protocol: "https"
#username: "elastic"
#password: "changeme"
#----------------------------- Logstash output --------------------------------
#output.logstash:
# The Logstash hosts
#hosts: ["localhost:5044"]
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
#================================ Logging =====================================
# Sets log level. The default log level is info.
# Available log levels are: error, warning, info, debug
#logging.level: debug
# At debug level, you can selectively enable logging only for some components.
# To enable all selectors use ["*"]. Examples of other selectors are "beat",
# "publish", "service".
#logging.selectors: ["*"]
#============================== Xpack Monitoring ===============================
# filebeat can export internal metrics to a central Elasticsearch monitoring
# cluster. This requires xpack monitoring to be enabled in Elasticsearch. The
# reporting is disabled by default.
# Set to true to enable the monitoring reporter.
#xpack.monitoring.enabled: false
# Uncomment to send the metrics to Elasticsearch. Most settings from the
# Elasticsearch output are accepted here as well. Any setting that is not set is
# automatically inherited from the Elasticsearch output configuration, so if you
# have the Elasticsearch output configured, you can simply uncomment the
# following line.
#xpack.monitoring.elasticsearch:
[root@VM_3_7_centos /]#执行下列命令启动filebeat
[root@VM_3_7_centos /]# sudo /etc/init.d/filebeat start
Starting filebeat (via systemctl): [ OK ]
[root@VM_3_7_centos /]#进入ElasticSearch对应的Kibana管理页,如下图。
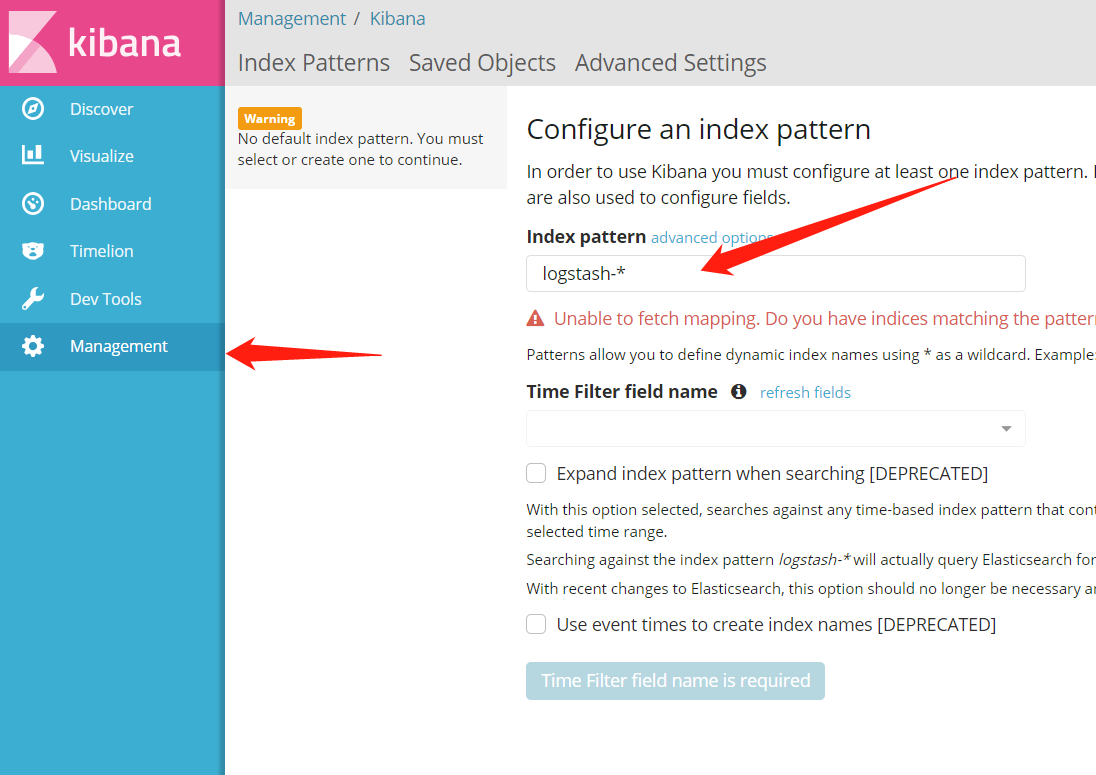 首次访问Kibana默认会显示管理页
首次访问Kibana默认会显示管理页
首次登陆,会默认进入Management页面,我们需要将Index pattern内容修改为:filebeat-*,然后页面会自动填充**Time Filter field name,**不需手动设置,直接点击Create即可。点击Create后,页面需要一定时间来加载配置和数据,请稍等。如下图:
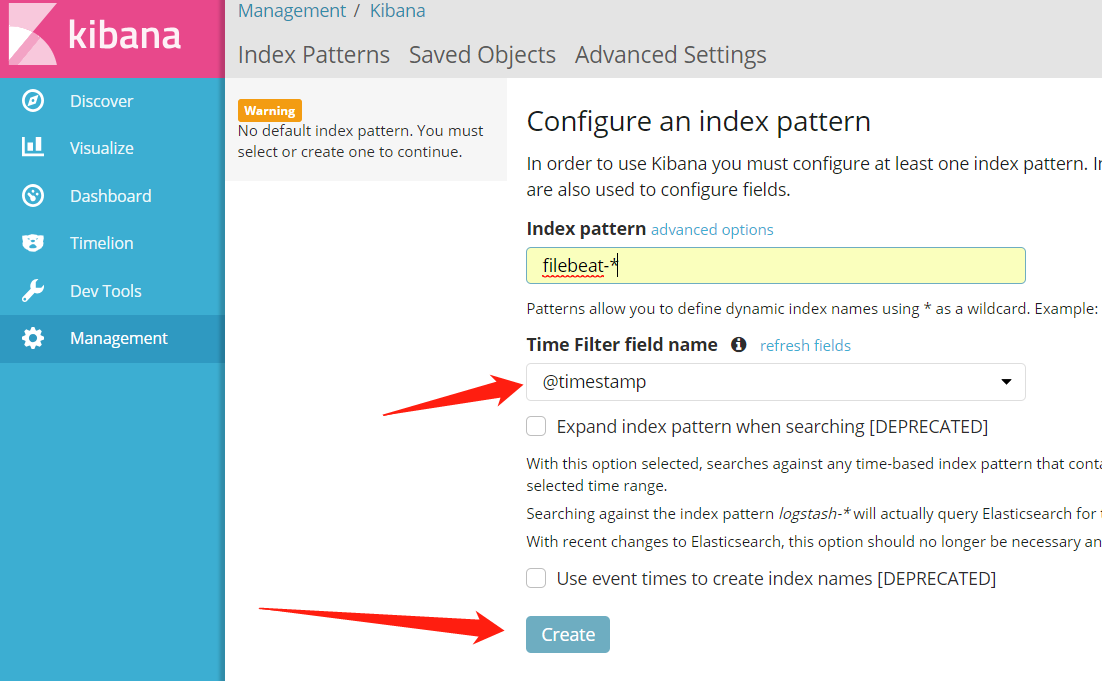 将Index pattern内容修改为:filebeat-*,然后点击Create
将Index pattern内容修改为:filebeat-*,然后点击Create
至此,CVM上,/var/log/secure日志文件,已对接到ElasticSearch中,历史日志可以通过Kibana进行查询,最新产生的日志也会实时同步到Kibana中。
日志接管已完成配置,如何使用呢?
如下图:
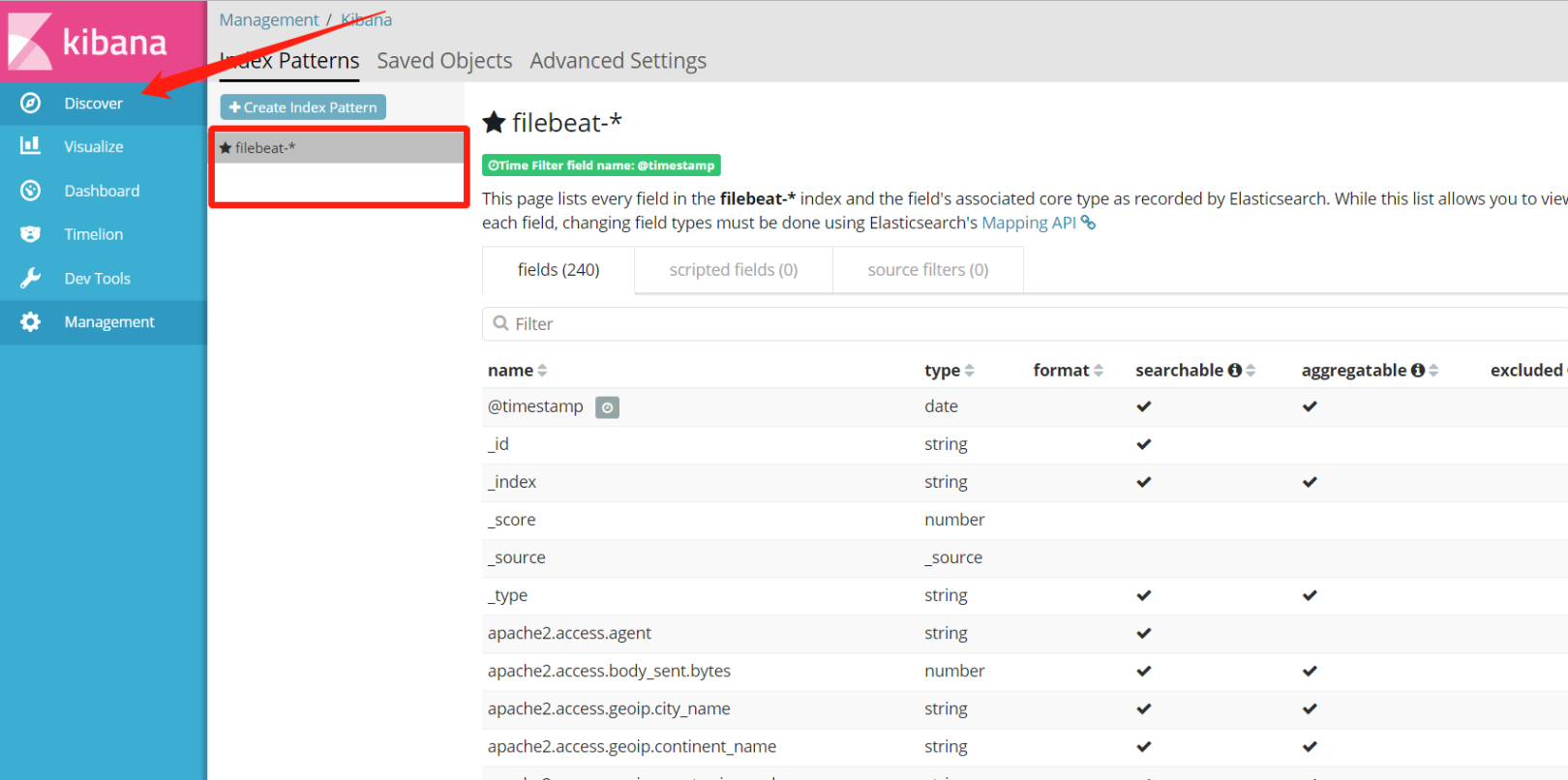 在Index Patterns中可以看到我们配置过的filebeat-*
在Index Patterns中可以看到我们配置过的filebeat-*
点击Discover,即可看到secure中的所有日志,页面上方的搜索框中输入关键字,即可完成日志的检索。如下图(点击图片,可查看高清大图):
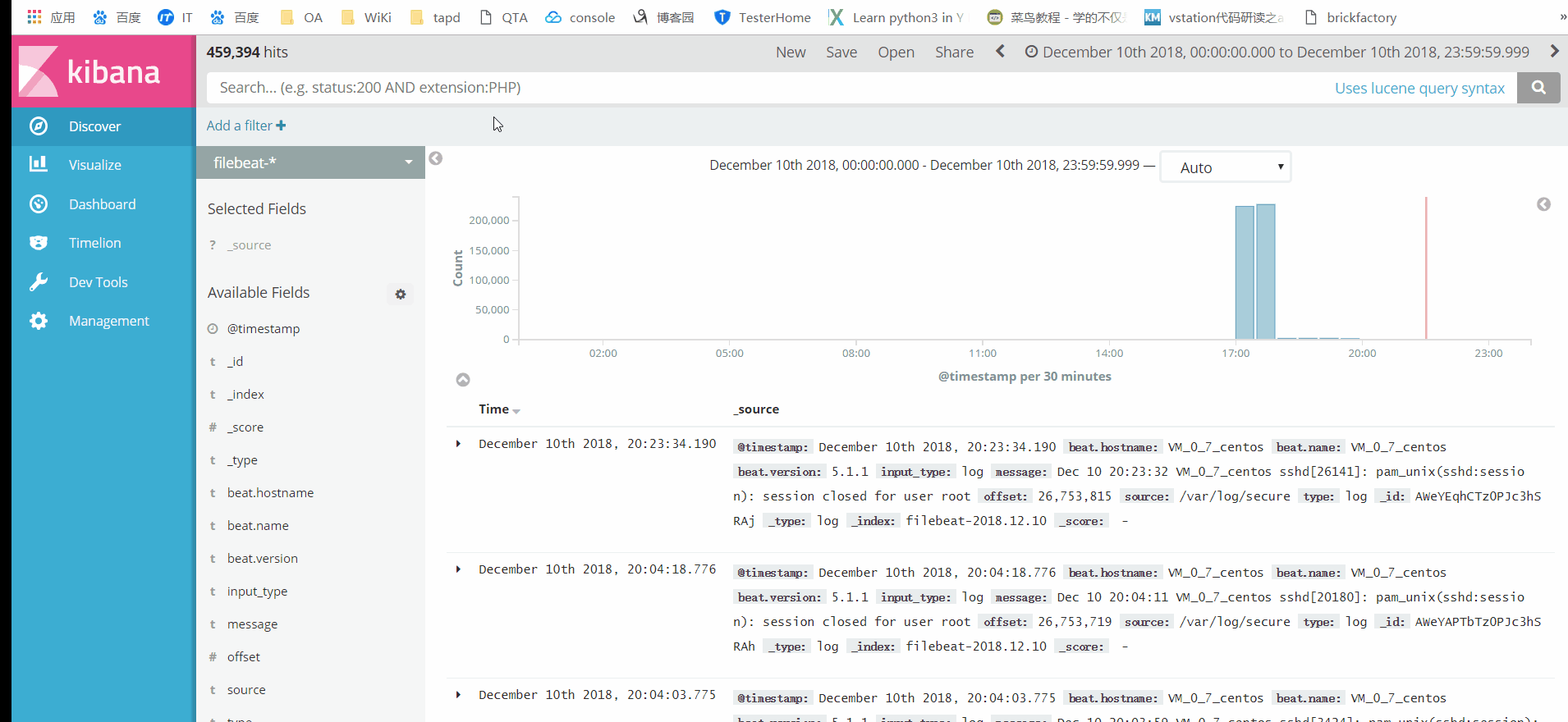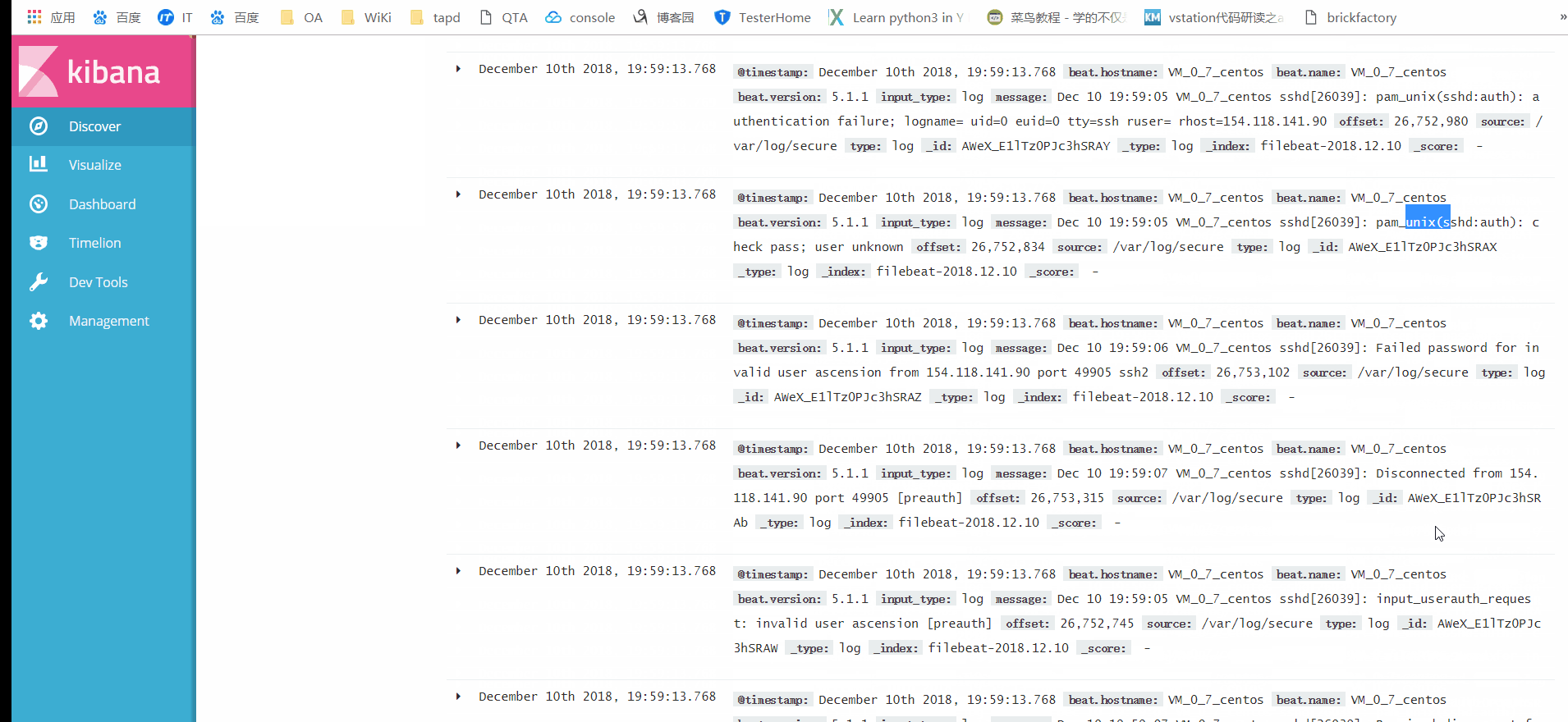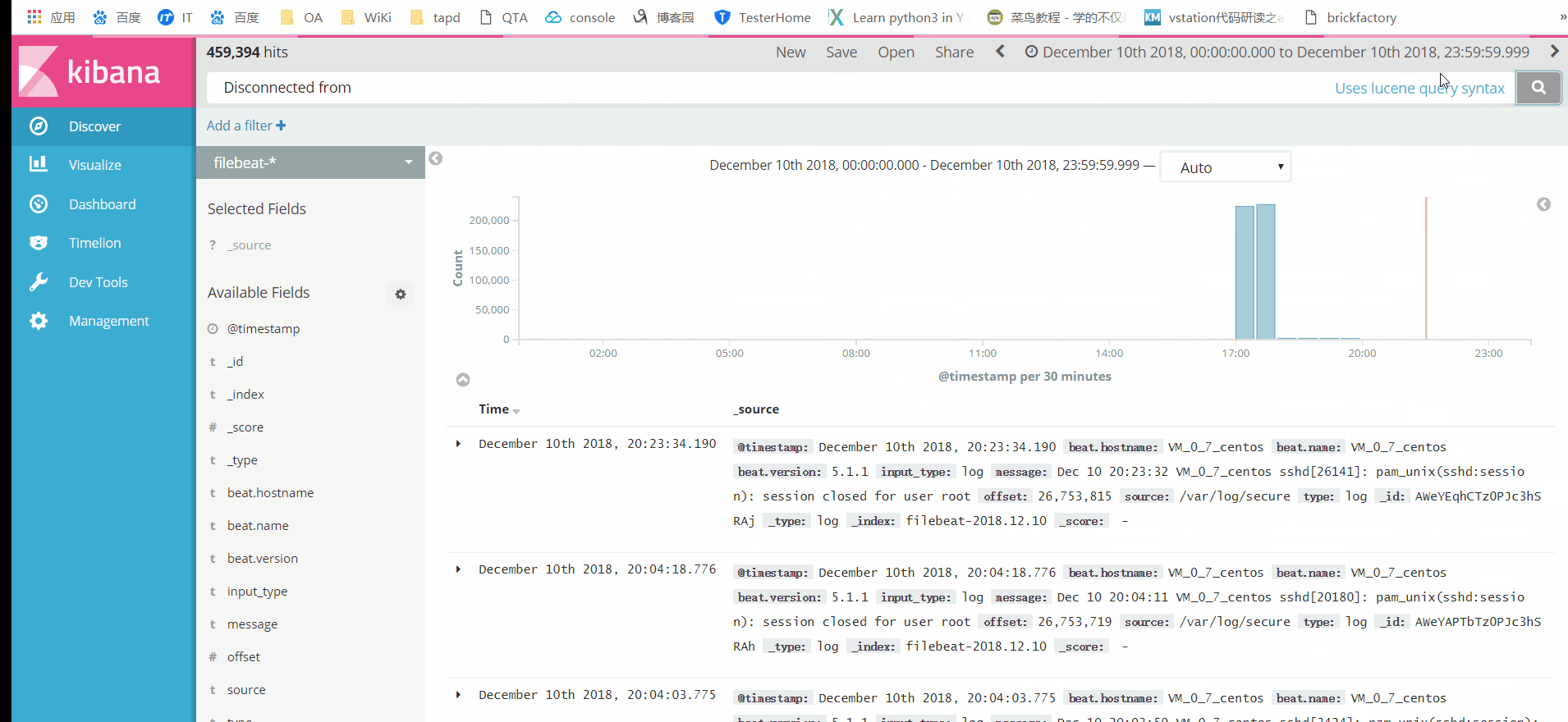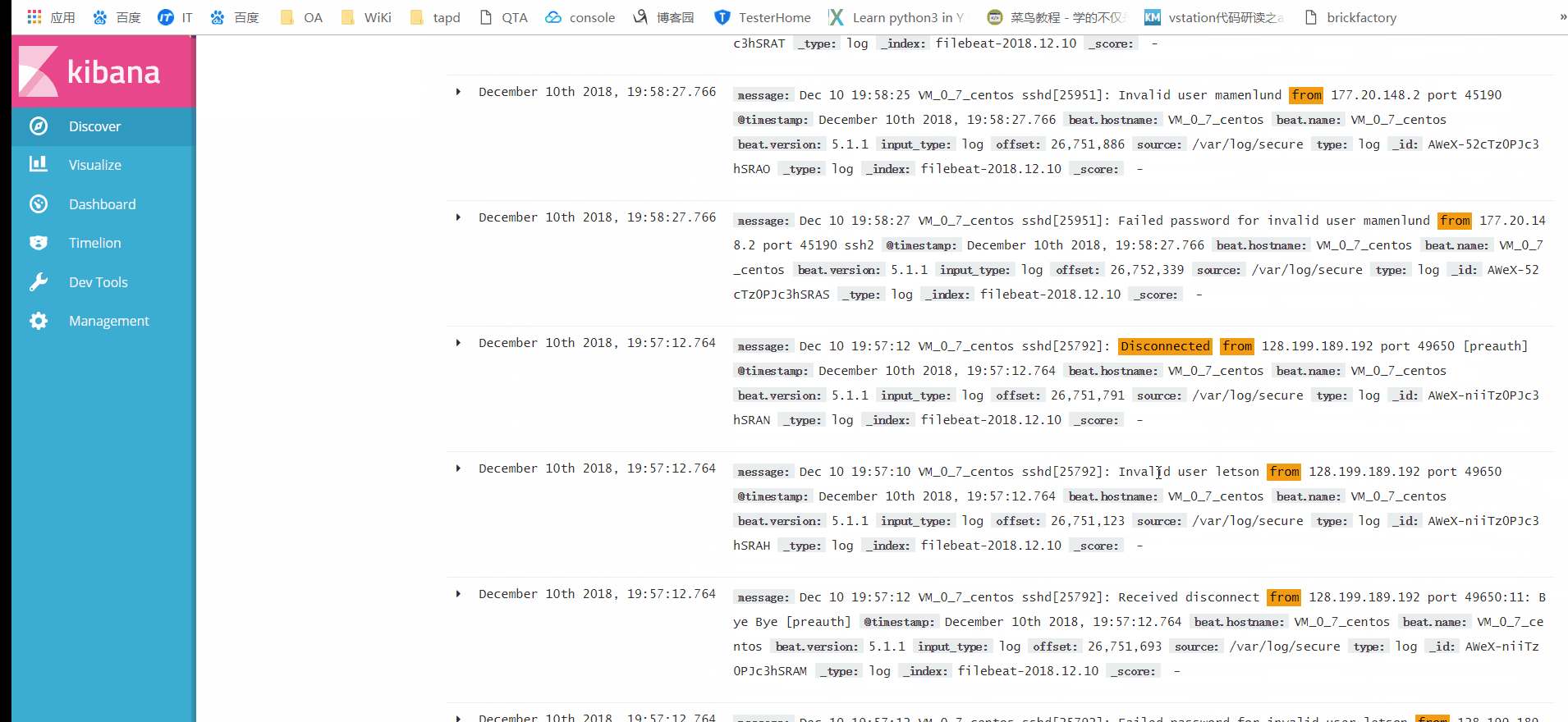 使用Kibana进行日志检索
使用Kibana进行日志检索
实际上,检索只是Kibana提供的诸多功能之一,还有其他功能如可视化、分词检索等,还有待后续研究。
到此,相信大家对“Linux日志对接Kibana如何进行配置与部署”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/qcloudcommunity/blog/2988448



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



