иҝҷзҜҮж–Үз« дё»иҰҒдёәеӨ§е®¶еұ•зӨәдәҶвҖңHive SQLеҰӮдҪ•и°ғдјҳвҖқпјҢеҶ…е®№з®ҖиҖҢжҳ“жҮӮпјҢжқЎзҗҶжё…жҷ°пјҢеёҢжңӣиғҪеӨҹеё®еҠ©еӨ§е®¶и§ЈеҶіз–‘жғ‘пјҢдёӢйқўи®©е°Ҹзј–еёҰйўҶеӨ§е®¶дёҖиө·з ”究并еӯҰд№ дёҖдёӢвҖңHive SQLеҰӮдҪ•и°ғдјҳвҖқиҝҷзҜҮж–Үз« еҗ§гҖӮ
1гҖҒdistictеҺ»йҮҚж•ҲзҺҮжҜ”group byдҪҺпјҹ
д№ӢеүҚеӨ§е®¶еңЁзҪ‘дёҠжҖ»иғҪзңӢеҲ°hiveи°ғдјҳдёӯдёҖе®ҡжңүиҝҷд№ҲдёҖжқЎпјҢиҰҒйҒҝе…ҚдҪҝз”ЁdistinctеҺ»йҮҚпјҢд»Јжӣҝжі•жҳҜgroup byгҖӮдҪҶжҳҜ жҳҜдёҚжҳҜжүҖжңүзҡ„жғ…еҶөдёӢйғҪжҳҜеҰӮжӯӨе‘ўпјҹзңӢдёӢйқўиҝҷдёӘжЎҲдҫӢ
select count(1) from(
select s_age
from student_tb_orc
group by s_age
) b
иҝҷйҮҢдёәдәҶд»ҺеӯҰз”ҹиЎЁдёӯз»ҹи®Ўе№ҙйҫ„зҡ„жһҡдёҫеҖјдёӘж•°пјҢдҪҶжҳҜдёәд»Җд№ҲдёҚз”ЁдёӢйқўзҡ„иҝҷз§Қdistinctе‘ўпјҹ
select count(distinct s_age)
from student_tb_orc
жҲ‘们дёҖиҲ¬йғҪдјҡжғіж•°жҚ®йҮҸеӨ§дәҶ第дёҖз§ҚиғҪеӨҹйҒҝе…Қreduceз«Ҝзҡ„ж•°жҚ®еҖҫж–ңпјҢдҪҶдәӢе®һдёҠпјҢдёҚи®әж•°жҚ®йҮҸеӨ§е°ҸпјҢйғҪжҳҜдёӢйқўзҡ„з®ҖжҙҒSQLж•ҲзҺҮжӣҙй«ҳгҖӮ
гҖҢиҜҘдҪңиҖ…и·‘зҡ„з»“жһңдёә47s е’Ң 28sгҖӮгҖҚ
иҝҷжҳҜдёәд»Җд№Ҳе‘ўпјҹ
- еӣ дёәеҺ»йҮҚзҡ„жҳҜs_ageеҲ—пјҢе®һйҷ…дёҠдёҡеҠЎеҗ«д№үиЎЁзӨәе№ҙйҫ„пјҢжһҡдёҫеҖјдёӘж•°йқһеёёжңүйҷҗпјҢеңЁMapйҳ¶ж®өдјҡеҜ№s_ageеҺ»йҮҚпјҢеӣ жӯӨжҜҸдёӘMapеҫ—еҲ°зҡ„s_ageжңүйҷҗпјҢжңҖеҗҺеҲ°иҫҫReduceйҳ¶ж®өзҡ„йқһеёёжңүйҷҗпјҢж №жң¬дёҚдјҡиҫҫеҲ°ж•°жҚ®еҖҫж–ңзҡ„йҮҸгҖӮ
- еҸҰеӨ–group byеңЁдёҚеҗҢзүҲжң¬й—ҙеҸҳеҠЁжҜ”иҫғеӨ§пјҢжңүзҡ„зүҲжң¬дјҡз”Ёжһ„е»әhashtableзҡ„еҪўејҸеҺ»йҮҚпјҢжңүзҡ„зүҲжң¬дјҡйҖҡиҝҮжҺ’еәҸзҡ„ж–№ејҸпјҢжҺ’еәҸжңҖдјҳж—¶й—ҙеӨҚжқӮеәҰж— жі•еҲ°O(1) гҖӮеҸҰеӨ–дёҠйқўеҶҷжі•иҪ¬еҢ–дёәдёӨдёӘд»»еҠЎпјҢдјҡж¶ҲиҖ—жӣҙеӨҡзҡ„зЈҒзӣҳзҪ‘з»ңI/Oиө„жәҗгҖӮ
- зӣ®еүҚHive 3з§Қж–°еўһдәҶcount(distinct) дјҳеҢ–пјҢйҖҡиҝҮй…ҚзҪ®
гҖҢhive.optimize.countdistinctгҖҚпјҢеҚідҪҝзңҹзҡ„еҮәзҺ°ж•°жҚ®еҖҫж–ңд№ҹеҸҜд»ҘиҮӘеҠЁдјҳеҢ–пјҢиҮӘеҠЁж”№еҸҳSQLжү§иЎҢзҡ„йҖ»иҫ‘гҖӮ
жүҖд»ҘпјҢгҖҢдёҠйқўз¬¬дёҖз§ҚSQLзҡ„еҶҷжі•жңүзӮ№иҝҮеәҰдјҳеҢ–гҖҚгҖӮи®©жҲ‘们继з»ӯзңӢдёҖдёӢ他们зҡ„жү§иЎҢжөҒзЁӢеӣҫпјҡ
第дёҖз§ҚSQLжү§иЎҢжөҒзЁӢеӣҫеҰӮдёӢпјҡ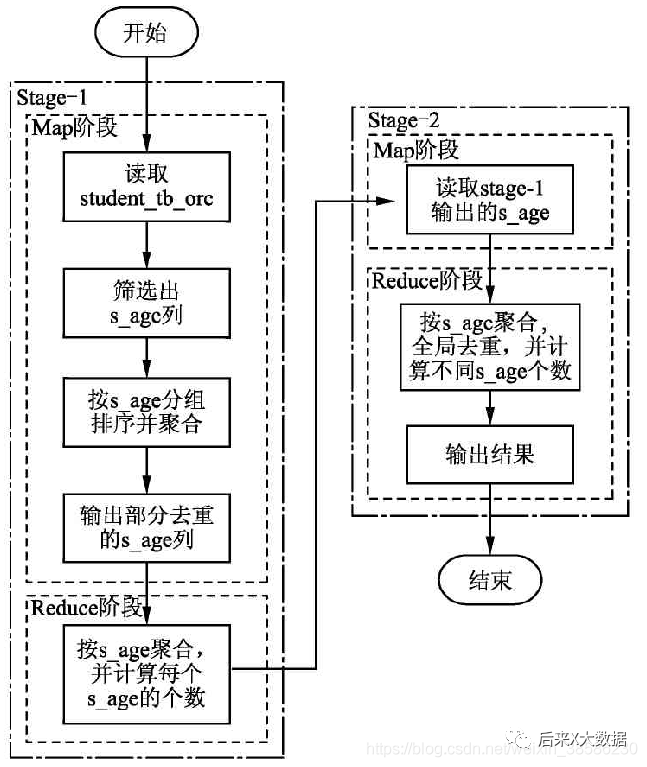 第дәҢз§ҚSQLзҡ„жү§иЎҢжөҒзЁӢеӣҫеҰӮдёӢпјҡ
第дәҢз§ҚSQLзҡ„жү§иЎҢжөҒзЁӢеӣҫеҰӮдёӢпјҡ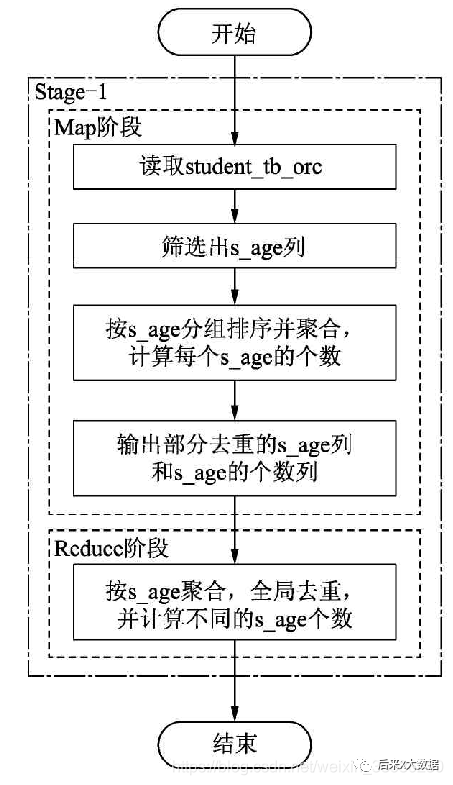 жүҖд»Ҙиҝҷ2дёӘSQLжү§иЎҢжөҒзЁӢзҡ„еҜ№жҜ”еӣҫеҰӮдёӢпјҡ
жүҖд»Ҙиҝҷ2дёӘSQLжү§иЎҢжөҒзЁӢзҡ„еҜ№жҜ”еӣҫеҰӮдёӢпјҡ
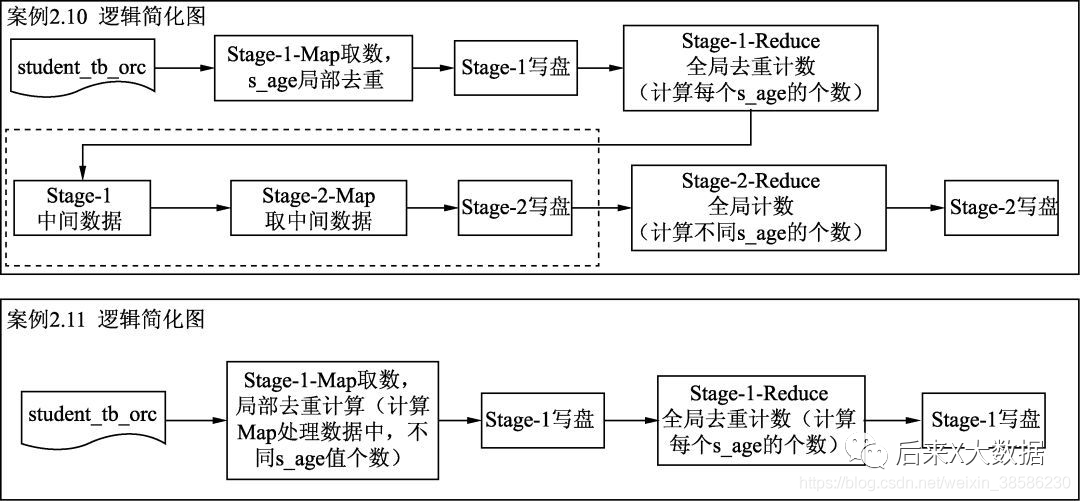 иҝҷдёӨдёӘSQLжү§иЎҢеҮәжқҘзҡ„ж—¶й—ҙе·®дё»иҰҒйӣҶдёӯеңЁж•°жҚ®дј иҫ“е’Ңдёӯй—ҙд»»еҠЎзҡ„еҲӣе»әдёӢпјҢе°ұжҳҜдёҠеӣҫзҡ„иҷҡзәҝжЎҶйғЁеҲҶпјҢеӣ жӯӨйҖҡиҝҮdistinctе…ій”®еӯ—жҜ”еӯҗжҹҘиҜўзҡ„ж–№ејҸж•ҲзҺҮжӣҙй«ҳгҖӮ
иҝҷдёӨдёӘSQLжү§иЎҢеҮәжқҘзҡ„ж—¶й—ҙе·®дё»иҰҒйӣҶдёӯеңЁж•°жҚ®дј иҫ“е’Ңдёӯй—ҙд»»еҠЎзҡ„еҲӣе»әдёӢпјҢе°ұжҳҜдёҠеӣҫзҡ„иҷҡзәҝжЎҶйғЁеҲҶпјҢеӣ жӯӨйҖҡиҝҮdistinctе…ій”®еӯ—жҜ”еӯҗжҹҘиҜўзҡ„ж–№ејҸж•ҲзҺҮжӣҙй«ҳгҖӮ
еҪ“然еҰӮжһңиҝҷйҮҢгҖҢйҮҮз”ЁSpark еј•ж“ҺпјҢе°ұзӣҙжҺҘзңҒеҺ»дәҶMap1иҗҪзӣҳе’ҢReduceеҶҚеҺ»иҜ»еҸ–дёӯй—ҙж•°жҚ®зҡ„ж—¶й—ҙгҖҚпјҢдәҢиҖ…зҡ„иҝҗиЎҢж—¶й—ҙе·®еҸҜиғҪжӣҙзҹӯгҖӮдҪҶжҳҜд»ҺSQLеҗҢзӯүеӨҚжқӮзЁӢеәҰдёӢпјҢз®ҖжҙҒжӣҙдјҳзҡ„и§’еәҰжқҘиҜҙпјҢиҝҳжҳҜdistinctжӣҙдјҳгҖӮ
гҖҢйӮЈд№Ҳд»Җд№Ҳжғ…еҶөдёӢ第дёҖз§ҚеҶҷжі•зҡ„SQLдјҡжҜ”第дәҢз§ҚеҶҷжі•зҡ„SQLж•ҲзҺҮжӣҙй«ҳе‘ўпјҹгҖҚ
еңЁжңүж•°жҚ®еҖҫж–ңзҡ„жғ…еҶөдёӢпјҢ第дёҖз§ҚеҶҷжі•зҡ„SQLж–№ејҸжӣҙдјҳгҖӮ
еҪ“ж•°жҚ®еӨ§еҲ°дёҖе®ҡзҡ„йҮҸзә§ж—¶пјҢ第дёҖз§ҚеҶҷжі•зҡ„SQLжңүдёӨдёӘдҪңдёҡпјҢеҸҜд»ҘжҠҠеӨ„зҗҶйҖ»иҫ‘еҲҶж•ЈеҲ°дёӨдёӘйҳ¶ж®өдёӯпјҢеҚіз¬¬дёҖдёӘйҳ¶ж®өе…ҲеӨ„зҗҶдёҖйғЁеҲҶж•°жҚ®пјҢзј©е°Ҹж•°жҚ®йҮҸпјҢ第дәҢдёӘйҳ¶ж®өеңЁе·Із»Ҹзј©е°Ҹзҡ„ж•°жҚ®йӣҶдёҠ继з»ӯеӨ„зҗҶгҖӮ
иҖҢ第дәҢз§ҚеҶҷжі•зҡ„SQLпјҢз»ҸиҝҮMapйҳ¶ж®өеӨ„зҗҶзҡ„ж•°жҚ®иҝҳйқһеёёеӨҡж—¶пјҢжүҖжңүзҡ„ж•°жҚ®еҚҙйғҪйңҖиҰҒдәӨз»ҷдёҖдёӘReduceиҠӮзӮ№еҺ»еӨ„зҗҶпјҢе°ұеҘҪжҜ”еҚғеҶӣдёҮ马иҝҮзӢ¬жңЁжЎҘдёҖж ·пјҢдёҚд»…ж— жі•еҲ©з”ЁеҲ°еҲҶеёғејҸйӣҶзҫӨзҡ„дјҳеҠҝпјҢиҝҳиҰҒжөӘиҙ№еӨ§йҮҸж—¶й—ҙеңЁзӯүеҫ…пјҢиҖҢиҝҷдёӘзӯүеҫ…зҡ„ж—¶й—ҙиҝңжҜ”第дёҖз§ҚеҶҷжі•зҡ„SQLеӨҡдёӘMapReduceжүҖ延й•ҝзҡ„жөҒзЁӢеҜјиҮҙйўқеӨ–иҠұиҙ№зҡ„ж—¶й—ҙиҝҳеӨҡгҖӮ
гҖҢдҪҶжҳҜпјҢеҰӮеүҚйқўжүҖиҜҙпјҢеңЁHive 3.0дёӯеҚідҪҝйҒҮеҲ°ж•°жҚ®еҖҫж–ңпјҢ第дәҢз§ҚеҶҷжі•зҡ„SQLе°Ҷhive.optimize.countdistinctи®ҫзҪ®дёәtrueпјҢеҲҷж•ҙдёӘеҶҷжі•д№ҹиғҪиҫҫеҲ°з¬¬дёҖз§ҚеҶҷжі•зҡ„SQLзҡ„ж•ҲжһңгҖӮгҖҚ
жҲ‘е°қиҜ•еңЁиҮӘе·ұзҡ„йӣҶзҫӨдёҠи·‘еҗҢж ·зҡ„SQLпјҢз”ЁSpark еј•ж“ҺпјҢеҸҜиғҪеӣ дёәж•°жҚ®йҮҸе°Ҹзҡ„еҺҹеӣ пјҢзӣёе·®дёҚеӨ§пјҢйғҪжҳҜ4sе·ҰеҸігҖӮ
2гҖҒж”№еҶҷSQLе®һзҺ°union зҡ„дјҳеҢ–
йңҖжұӮпјҡд»ҺеӯҰз”ҹиЎЁдёӯжүҫеҲ°жҜҸдёӘе№ҙйҫ„ж®өжңҖжҷҡеҮәз”ҹе’ҢжңҖж—©еҮәз”ҹзҡ„дәәзҡ„з”ҹж—Ҙж—ҘжңҹпјҢеҶҷе…ҘдёҖдёӘиЎЁдёӯпјӣ
дәҺжҳҜSQLеҰӮдёӢпјҡ
INSERT into table student_stat partition(tp)
select
s_age,
min(s_birth) stat,
'min' tp
from student_tb_txt
group by s_age
union all
select
s_age,
max(s_birth) stat,
'max' tp
from student_tb_txt
group by s_age;
дҪҶжҳҜиҝҷдёӘSQLе…¶е®һжҳҜ5дёӘjobеҜ№еә”дәҶ4дёӘMRд»»еҠЎпјҢж•ҲзҺҮжҳҜжҜ”иҫғдҪҺзҡ„гҖӮ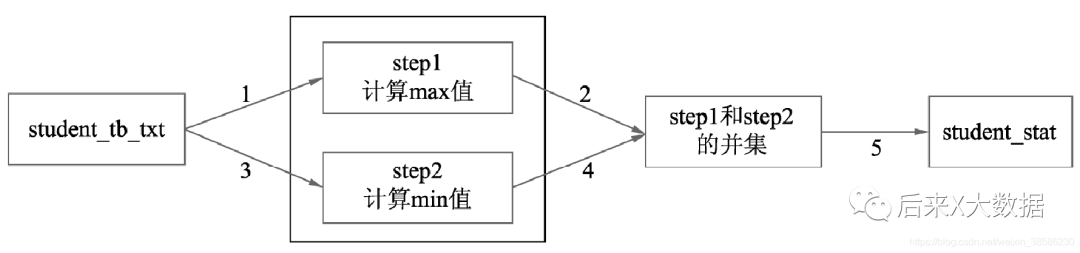 йӮЈжҖҺд№ҲдјҳеҢ–е‘ўпјҹйӮЈиғҪдёҚиғҪеҸӘиҜ»дёҖж¬ЎиЎЁпјҢе°ұиғҪйғҪи®Ўз®—еҮәжңҖе°ҸеҖје’ҢжңҖеӨ§еҖјпјҢ然еҗҺдҫқж¬ЎеҶҷе…ҘжңҖеҗҺзҡ„з»“жһңиЎЁпјҢдёҚйңҖиҰҒдёӯй—ҙ并йӣҶгҖӮзңӢеҰӮдёӢSQL
йӮЈжҖҺд№ҲдјҳеҢ–е‘ўпјҹйӮЈиғҪдёҚиғҪеҸӘиҜ»дёҖж¬ЎиЎЁпјҢе°ұиғҪйғҪи®Ўз®—еҮәжңҖе°ҸеҖје’ҢжңҖеӨ§еҖјпјҢ然еҗҺдҫқж¬ЎеҶҷе…ҘжңҖеҗҺзҡ„з»“жһңиЎЁпјҢдёҚйңҖиҰҒдёӯй—ҙ并йӣҶгҖӮзңӢеҰӮдёӢSQL
from student_tb_txt
INSERT into table student_stat partition(tp)
select s_age,min(s_birth) stat,'min' tp
group by s_age
insert into table student_stat partition(tp)
select s_age,max(s_birth) stat,'maxвҖҷ tp
group by s_age;
гҖҢиҝҷз§Қд№ҹеҸ«еҒҡmulti-table-insertиҜӯжі•пјҢеӨҡи·Ҝиҫ“еҮәгҖҚ еңЁеҰӮдёҠзҡ„SQLжү§иЎҢж—¶пјҢе…¶е®һд№ҹеҗҜеҠЁдәҶ1дёӘJob пјҢжүҖд»Ҙж•ҲзҺҮзҡ„жҸҗеҚҮиҝҳжҳҜйқһеёёжҳҫи‘—зҡ„гҖӮ
еңЁеҰӮдёҠзҡ„SQLжү§иЎҢж—¶пјҢе…¶е®һд№ҹеҗҜеҠЁдәҶ1дёӘJob пјҢжүҖд»Ҙж•ҲзҺҮзҡ„жҸҗеҚҮиҝҳжҳҜйқһеёёжҳҫи‘—зҡ„гҖӮ
д»ҘдёҠжҳҜвҖңHive SQLеҰӮдҪ•и°ғдјҳвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ





