这期内容当中小编将会给大家带来有关TF-IDF如何提取文本特征词,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
01
—
TF-IDF主要做什么?
文本分类中大都用到TF-IDF技术,比如扔给我们1篇新浪网推送的消息,让机器判断下属于新闻类,还是财经类,还是体育类,还是娱乐类;再比如,今日头条推送的1篇消息,如何提取出里面的关键词汇,以此推荐给符合我们胃口的文章。
02
—
TF-IDF主要思想
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率 TF 高,并且在其他文章中很少出现(IDF值大),则认为此词或者短语具有很好的类别区分能力,适合用来分类。
03
—
TF-IDF全称叫什么?
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF意思是词频(Term Frequency),IDF意思是逆向文件频率(Inverse Document Frequency)。
04
—
为什么叫逆向文件频率?
TF-IDF中词频的描述TF,我们好理解,不就是一篇文章中一个词在我们的语料库中出现的次数吗,但是逆向文件频率,该怎么理解?
拿我们的母语来说,比如,“的”,“我们”,类似的这种词语,大家觉得会对我们判断这篇文章是体育类,还是娱乐类的文章作用大吗?尽管它们的TF很大,但是实质对我们的分类没有帮助,所以,此时自然要想到对TF加一个权重影响因子:IDF,逆向文件频率,比如,一篇文章中如果出现了 “贝叶斯”这个词语,那么,我们去语料库,发现现有的1亿个网页中,有500个网页,出现了这个贝叶斯分类,而“的”这个词,有1亿个都出现了,这个时候,我们希望“贝叶斯”比“的”IDF要大,即权重要大,IDF的计算公式最终的确实现了这个效果,这个在下文中我们可以看出来。
05
—
TF,IDF的数学公式
一篇网页中的总词语数是100个,而词语“贝叶斯”出现了3次,那么“贝叶斯”一词在该文件中的词频就是 3/100=0.03,
对应的数学公式:
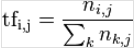
以上公式的字符含义,i是语料库中第i个单词,j是当前的这篇网页的编号。
分析语料库的1亿个网页时,发现有500个网页含有“贝叶斯”,所以贝叶斯这个词的IDF计算公式:
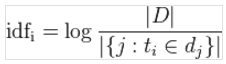
i依然是语料库中的第i个词(贝叶斯),D是语料库中所有的网页个数,分母的集合表示,贝叶斯出现在1亿个网页中的个数,如上所述为500个网页。最后,再取对数,可以得出贝叶斯的IDF比“的”的IDF大。
06
—
Get together
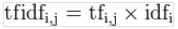
这个公式实现的效果:
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。
过滤掉常见的词语,比如“的”,“我们”,“吃”。
最终:提取了一篇文章中重要的词语。
上述就是小编为大家分享的TF-IDF如何提取文本特征词了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4585819/blog/4612649



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



