查看hive语句的执行流程:explain select ….from t_table …;
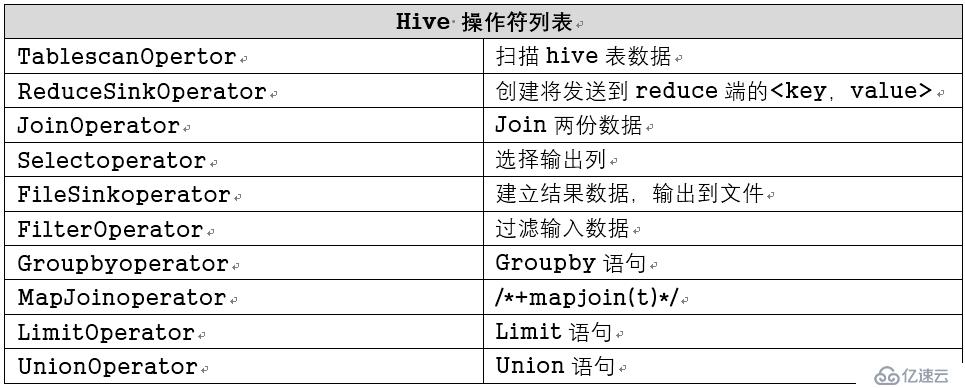
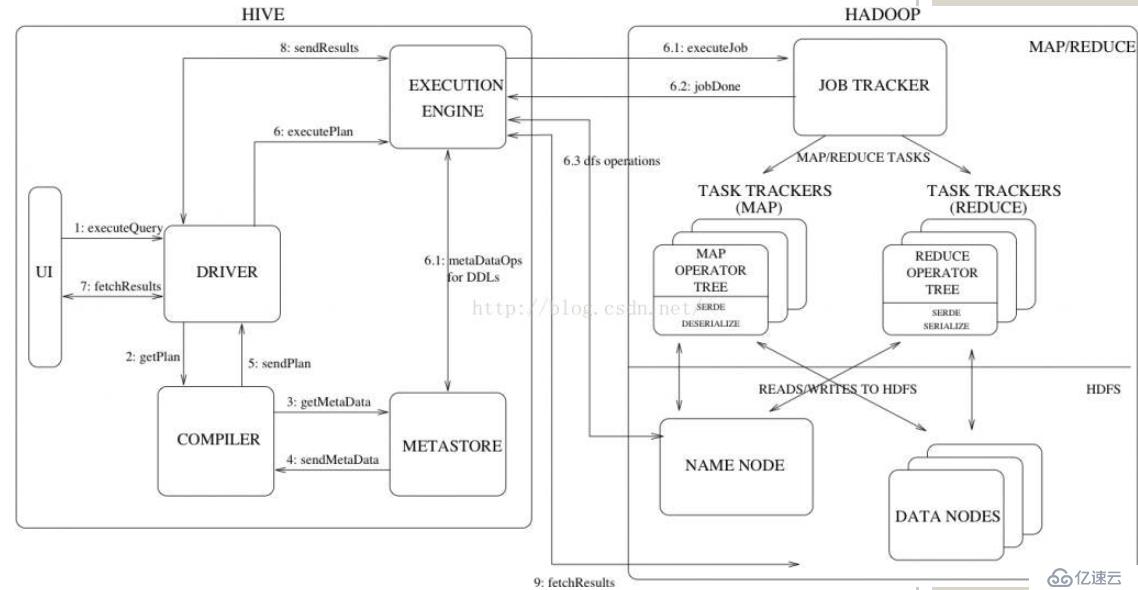
流程大致步骤为:
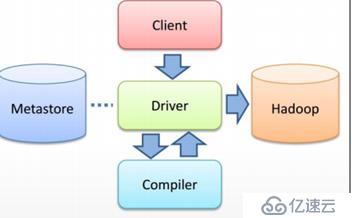
1. 用户提交查询等任务给Driver。
2. 编译器获得该用户的任务Plan。
3. 编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
4. 编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce), 最后选择最佳的策略。
5. 将最终的计划提交给Driver。
7. 获取执行的结果。
8. 取得并返回执行结果。
例:SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON pv.userid = u.userid;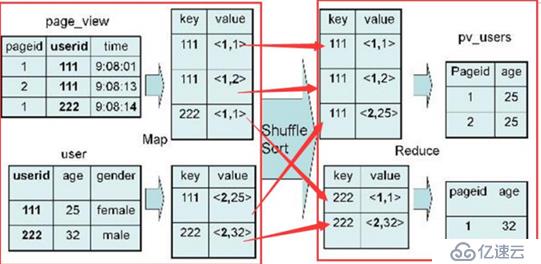
map 端:以 JOIN ON 条件中的列作为 Key,以page_view表中的需要字段,表标识作为value,最终通过key进行排序,也就是join字段进行排序。
shuffle端:根据 Key 的值进行 Hash,并将 Key/Value 对按照 Hash 值推 至不同对 Reduce 中
reduce 端:根据key进行分组,根据不同的表的标识,拿出不同的数据,进行拼接。
例:SELECT pageid, age, count(1) FROM pv_users GROUP BY pageid, age;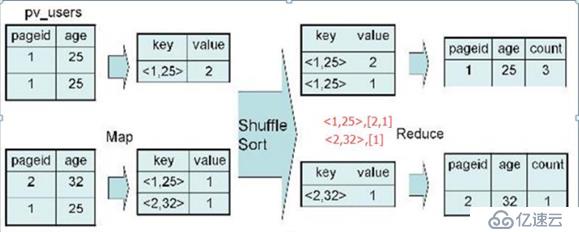
map 端:
key:以pageid, age作为key,并且在map输出端有combiner。
value :1次
reduce 端:对value进行求和
例:select distinct age from log;
map端:
key:age
value:null
reduce端:
一组只要一个输出context.write(key,null)。
例:select count(distinct userid) from weibo_temp;
即使设置了reduce个数为3个,最终也只会执行一个,因为,count()是全局,只能开启一个reducetask。
map端:
key:userid
value: null
reduce端:
一组只要一个,定义一个全局变量用于计数,在cleanup(Context context) 中输出context.write(key,count)
当然distinct+count是一个容易产生数据倾斜的做法,应该尽量避免,如果无法避免,那么就使用这种方法:
select count(1) from (select distinct userid from weibo_temp); 这样可以并行多个reduce task任务,从而解决单节点的压力过大。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



