这篇文章主要讲解了“hadoop分布式集群的搭建过程”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“hadoop分布式集群的搭建过程”吧!
[hadoop@hadoop01 home]$ put c:/hadoop-2.6.5-centos-6.7.tar.gz
[hadoop@hadoop01 home]$tar -zxvf hadoop-2.6.5-centos-6.7.tar.gz -C /home/hadoop/apps
[hadoop@hadoop01 home]$ cd /home/hadoop/apps/hadoop-2.6.5/hadoop/etc
这里需要修改6个配置文件:
hadoop-env.sh:
加入:export JAVA_HOME=/usr/java/jdk1.8.0_73
core-site.xml:
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoopdata</value>
</property>hdfs-site.xml:
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoopdata/name</value>
<description>为了保证元数据的安全一般配置多个不同目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoopdata/data</value>
<description>datanode 的数据存储目录</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>HDFS 的数据块的副本存储个数</description>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hadoop02:50090</value>
<description>secondarynamenode 运行节点的信息,和 namenode 不同节点</description>
</property>mapred-site.xml:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>yarn-site.xml:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop03</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>YARN 集群为 MapReduce 程序提供的 shuffle 服务</description>
</property>slaves:
hadoop01 hadoop02 hadoop03
[hadoop@hadoop01 etc]$scp -r hadoop-2.6.5 hadoop02:$PWD
[hadoop@hadoop01 etc]$scp -r hadoop-2.6.5 hadoop03:$PWD
[hadoop@hadoop01 etc]$sudo vim /etc/profile:
加入:
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.6.5/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[hadoop@hadoop01 etc]$source /etc/profile
[hadoop@hadoop01 etc]$hadoop namenode -format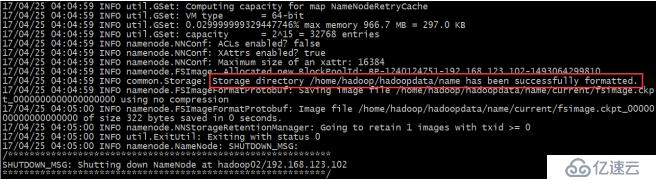
[hadoop@hadoop01 etc]$start-dfs.sh
[hadoop@hadoop01 etc]$sbin/start-yarn.sh
补充:
hdfs的web界面是: http://hadoop01:50070
yarn的web界面是: http://hadoop03:8088
查看集群的状态:hdfs dfsadmin -report
1、启动 namenode 或者 datenode
sbin/hadoop-daemon.sh start datanode
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start secondarynamenode
2、启动 yarn nodemanager
sbin/yarn-daemon.sh start nodemanager
sbin/yarn-daemon.sh start resourcemanager
感谢各位的阅读,以上就是“hadoop分布式集群的搭建过程”的内容了,经过本文的学习后,相信大家对hadoop分布式集群的搭建过程这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



