kubernetes V1.6.4 分布式集群的部署及如何进行service负载均衡,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
最近几年,微服务一词经常被IT的技术界人士提及,简单介绍的话,微服务架构就是将原本单独部署运行的大型软件拆分为一个个可独立部署的又可互相联系的微小型服务。容器化技术软件docker的兴起,更将微服务推向了高潮。docker由单机走向集群是运算发展的必然过程,但随之而来的分布式容器治理是一个难点。而kubernetes就是为此而生,它是目前被一致看好的docker分布式系统的解决方案,而且其全面拥抱微服务,为微服务提供多实例副本的支撑,而且其内部Service内嵌了负载均衡,为其他资源提供了高可靠的服务。

kubernetes 由两种节点组成:
1,master节点,即主节点,用于跑kubernetes的核心组件等程序,是管理节点
2,node节点,即容器运行节点或者说是用于运算的节点,此外还会跑一些kubernetes的注册组件等服务,是从节点
硬件上面一般表现为一台master主机管理多台node主机
kubernetes包含了多种资源,例如:Pod,RC,Service,Ingress,以及上面一节提到的node节点等等。 这些资源是kubernetes内部的小单元,可以通过kubectl工具进行增删查改的操作,同时这些资源为最终的微服务运算提供了支撑。以下会对其中的几个资源进行简单介绍。
Pod是kubernetes最重要也是最基本的概念,也是kubernetes中能被创建,调度,管理的最小单元。其取名为Pod,通英文单词pod,即豌豆荚的意思,也非常形象地展示了该资源的结构和作用。
如下图所示:

Pod就像一个豌豆荚一样,里面装了一个一个container的小豆子。其中,pause container是每一个Pod都一定会包含的container,pause是作为Pod的根容器,也就是该pause container在Pod创建的时候是会默认自动创建的,无需用户显式创建,其用于判断Pod的活性以及记录Pod的IP,共享给本Pod中的其他container使用。
以下是一个Pod的yaml配置文件的例子:
apiVersion: v1
kind: Pod
metadata:
name: php-test
labels:
name: php-test
spec:
containers:
- name: php-test
image: 192.168.174.131:5000/php-base:1.0
ports:
- containerPort: 80
hostPort: 80副本控制器RC的英文全称是:Replication Controller。它其实是定义了一个期望值的场景,即要求某种Pod的副本的运行数量在任意的时候,都应该尽快尽量符合该期望值。所以,一般RC的配置文件里面包含了Pod的期望副本数量,筛选的Pod的Label Selector,以及创建Pod的image模板内容。 以下是一个简单的RC的yaml配置文件的例子:
apiVersion: v1
kind: ReplicationController
metadata:
name: loadbalancetest1
spec:
replicas: 3
selector:
app: loadbalancetest
template:
metadata:
labels:
app: loadbalancetest
spec:
containers:
- name: loadbalancetest
image: docker.io/webin/loadbalancetest:1.0
ports:
- containerPort: 8080
hostPort: 8087由于RC能自动创建期望值的Pod,所以一开始甚至可以跳过Pod的yaml配置文件的编写,直接编写RC来创建Pod。
Service是kubernetes中的核心资源之一,其实这里的Service就是相当于我们微服务架构中所指的微服务了。实际上前面的Pod和RC,都是为Service这一微服务而服务的。
以下是一个简单的Service的yaml配置文件的例子:
apiVersion: v1
kind: Service
metadata:
name: loadbalancetest
spec:
type: NodePort
ports:
- port: 8080
targetPort: 8080
nodePort: 30001
protocol: TCP
name: http
selector:
app: loadbalancetestPod,RC既然都为Service而服务,那么它们肯定有关系关联起来。是的,它们就是通过内置的标签来联系的。 如下图所示:

可以看出Pod,RC,Service通过一个叫Lable Selector的标签选择器关联到了一起。这里的Service实际上有3个Pod为它提供真正的服务。关于Label Selector以及Label,我们其实通过前面的yaml文件中也能看到:
selector:
app: loadbalancetest还有:
labels:
app: loadbalancetest以及
labels:
name: php-test等等。其中,Pod定义好自己的Label标签,这个Label标签可以是任意的key:value形式的键值对。Label标签对于一个Pod可以定义多个。这样的Label就是为了让RC以及Service通过定义Label Selector去找到对应的Pod。这样就达到了RC控制Pod的副本,而这些副本又为Service真正提供服务。而Service也可以通过自己内部的负载均衡去调用副本中的Pod来提供最终的服务,返回给上一级调用者。
补充:Service的负载均衡是内嵌的通过Label Selector对应得到的多个Pod后的负载均衡。默认是轮询机制的负载均衡,另外还有一种是当客户端请求时会优先返回上一次给该客户端提供服务的Pod的机制的负载均衡。
但无论是默认的负载均衡还是其他,这些负载均衡都是针对Service的内置负载均衡。由于Service的创建,Kubernetes给予的是虚拟的ClusterIP,该IP只能是内部的Kubernetes资源能访问,例如Pod可以访问,但外部的系统或者客户端不能通过该IP访问到该服务,所以如果外部系统想跳过Service去访问Pod,则可以尝试自己去创建自己的硬件或者软件级的负载均衡。一般Pod的IP+端口可以对应上一个container。
既然Service需要Kubernetes内部资源才能访问,而Service难得自带了内嵌的负载均衡,我们又想访问Service让其提供服务,除了Pod外,有没有其他kubernetes资源可以先访问Service然后让其暴露服务给外界?答案是有的,其中一个就是基于Nginx的Ingress。
Ingress是Kubernetes v1.1后新增的,它能将不同的URL访问请求转发到后端不同的Service上,实现HTTP层的业务路由机制。 以下是一个简单的RC的yaml配置文件的例子:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: myingress
spec:
rules:
- host: myingress.com
http:
paths:
- path: /LoadBalanceTest
backend:
serviceName: loadbalancetest
servicePort: 8080这里简单地配置了一个路由转发机制,即通过访问 http://myingress.com/LoadBalanceTest 的URL地址,Ingress可以转发到loadbalancetest:8080的这一个Service上。
kubernetes分布式系统是由一组可执行程序或说组件组成,这些组件包括:
(1)kube-apiserver -- API服务组件,提供kubernetes系统内所有对象的增删查改等restful式的服务端接口。
(2)kube-Controller Manager,资源管控器,主要负责集群内的资源(如Pod,Node等)管理。
(3)kube-Scheduler,将pod调度到指定的node中的调度器。
(4)kubelet,管理和维护一台Node主机的所有容器,并将该主机注册为Node节点的进程。
(5)kube-proxy,网络服务代理组件。
本章节将以创建一个能在多台分布式主机运行的实例,来讲解kubernetes的分布式集群的搭建和部署。
本案例将准备4台主机(虚拟机),其中一台是作为master主机,另外三台作为node主机。那么首先我们来了解一下master主机和node主机分别需要安装的组件和工具:
(1)master机器--APIServer,kube-scheduler,kube-controller;辅助类的中间件有:etcd
(2)node机器--kubelet,kube-proxy ,docker;辅助类中间件有flannel
由于docker以及kubernetes相关的软件,需要运行在Linux类的系统中,所以本次的案例选用了CentOS7作为Master和Node主机的操作系统。
大致的分布式架构如下图所示:

(图:Master主机和Node主机的组件安装与集群示意图)
如果是一台机器内建立的多台虚拟机,可能不会存在跨主机跨虚拟机的互联互通问题。
但如果是局域网内的多台主机,或多台主机内再建立的虚拟机来模拟集群环境的时候,就可能需要进行一定的设置了。
一般局域网间建立集群,我们会遇到这样的问题:
(1)无线局域网中设置了客户端隔离(client isolation),导致局域网主机间不能互联互通。
(2)局域网中的主机设置了防火墙。
(3)虚拟机由于网络设置不合理,导致不能进行跨主机的虚拟机之间互联互通。
对于这些问题,网络上有比较好的解答,例如使用网线直接连接主机组网,虚拟机网络设置桥接模式访问等。
对于我们案例的测试,我们可以使用一台手机WLAN热点进行多主机的组网。这样可以绕开许多网络互联互通的问题。
参考上面的“Master主机和Node主机的组件安装与集群示意图”,我们按以下的大致步骤进行组网:
(1)设置Master主机和3台Node主机在同一网段中,例如在192.168.43.0/24中。
(2)设置Master主机和3台Node主机的网关为同一网关:192.168.43.1。
(3)对于Master和Node主机都进行关闭防火墙的操作。
我们可以先前往gitHub开源代码托管服务网站,download相关的软件:
(1)kubernetes:https://github.com/kubernetes/kubernetes
(2)etcd:https://github.com/coreos/etcd
(3)flannel:https://github.com/coreos/flannel
可以点击“release”一栏,进入到版本选择,然后download,建议选用较新的release版本。
使用 tar命令,进行软件包的解压。 参考命令:
tar -zxvf kubernetes.tar.gz tar -zxvf etcd-v3.2.0-rc.1-linux-amd64.tar.gz tar -zxvf flannel-v0.7.1-linux-amd64.tar.gz
由于新版本的kubernetes软件包,只包含基本的单机应用组件,如果需要部署成分布式集群的,还需要进行二次download操作。
进入kubernetes的目录下的Cluster文件夹,执行get-kube-binaries.sh 脚本,参考代码如下:
cd kubernetes/cluster/
./get-kube-binaries.sh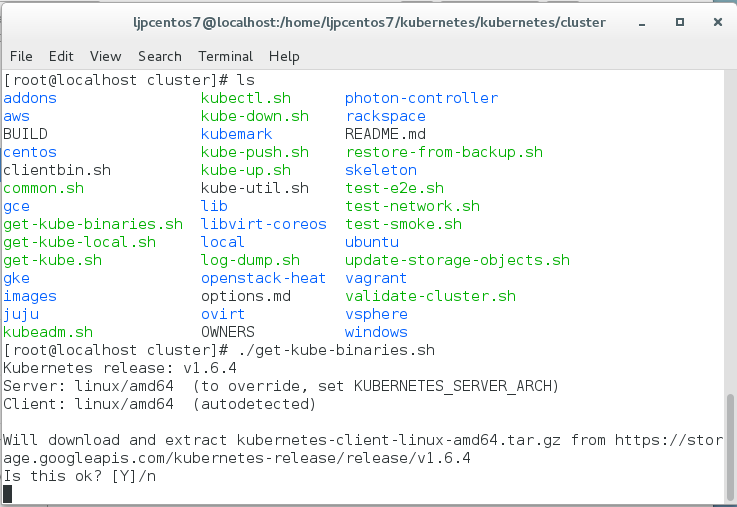
选择“Y”进行进一步的download,这里可能需要VPN辅助。
download完成后,会有新的两个文件出现:“kubernetes-server-linux-amd64.tar.gz”和“kubernetes-client-linux-amd64.tar.gz”。其中我们重点使用的是server的那一个软件包。
该软件包会download到kubernetes下的server文件夹内。我们对其进行解压,参考命令:
tar -zxvf kubernetes-server-linux-amd64.tar.gz
这样就可以得到一批新的kubernetes集群的组件。
我们进入解压后的文件夹查阅。参考代码:
cd kubernetes/server/bin/
ls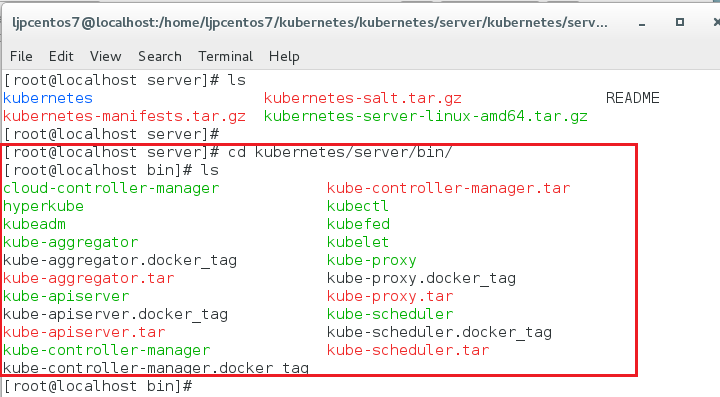
这样,一些kubernetes的核心组件都可以在这里找到了。
将这些组件复制到系统资源目录当中,方便执行,参考命令:
cp -rp hyperkube /usr/local/bin/
cp -rp kube-apiserver /usr/local/bin/
cp -rp kube-controller-manager /usr/local/bin/
cp -rp kubectl /usr/local/bin/
cp -rp kubelet /usr/local/bin/
cp -rp kube-proxy /usr/local/bin/
cp -rp kubernetes /usr/local/bin/
cp -rp kube-scheduler /usr/local/bin/类似的etcd也需要将执行文件放入系统资源中,参考命令:
cp -rp etcd* /usr/local/bin/接着,我们为master主机进行下面的操作。
-- 添加默认路由,参考命令:
route add default gw 192.168.43.1-- 去防火墙,参考命令:
systemctl stop firewalld.service
systemctl disable firewalld.service-- 启动etcd,指定监听的url地址和对外提供的客户端访问地址,参考命令:
etcd --listen-client-urls 'http://192.168.43.199:2379,http://127.0.0.1:2379' --advertise-client-urls 'http://192.168.43.199:2379,http://127.0.0.1:2379'-- 设置子网的键值,预留给Node主机,好让其使用flannel进行数据读取,参考命令:
etcdctl set /coreos.com/network/config '{"Network":"10.1.0.0/16"}'
(master主机运行etcd和设置成功截图)
-- 启动kubernetes 服务端,设置etcd的服务地址,绑定主机安全端口,设置Service集群虚拟IP段,参考代码:
kube-apiserver --etcd_servers=http://localhost:2379 --insecure-bind-address=0.0.0.0 --insecure-port=8080 --service-cluster-ip-range=10.254.0.0/24-- 启动controller manager,指定apiserver的地址,参考命令:
kube-controller-manager --logtostderr=true --master=http://192.168.43.199:8080-- 启动kubernetes scheduler,指定apiserver的地址,参考命令:
kube-scheduler --logtostderr=true --v=0 --master=http://192.168.43.199:8080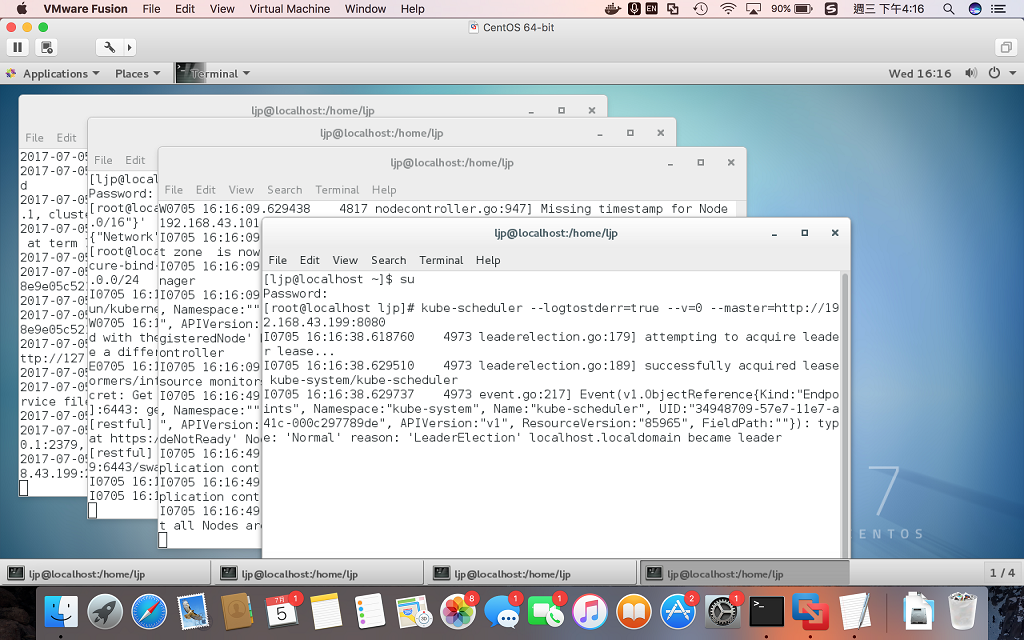
(kube-apiserver,kube-controller-manager,kube-scheduler成功启动截图)
若设置成功了,就可以再master主机进行kubectl的操作了,我们可以使用kubectl命令,进行相关kubernetes资源的操作,参考命令:
kubectl get nodes
可以看出,由于目前任意一台node主机都还没启动,所以这一时刻master主机查询nodes资源,并没有已经ready的node主机,可以供master主机使用。
node主机的环境搭建,首先需要先安装好docker,另外还需要将Master机器上的kubelet, kube-proxy,flannel给到每一个node节点机器上(如果确定版本一致的前提下,也可以重新download这些组件,而不用从Master主机复制)。
做好以上的准备工作后,我们就可以node主机的操作了。
复制相关文件到系统资源文件夹中,方便日后简化操作,参考代码:
cp -rp kubelet /usr/local/bin/
cp -rp kube-proxy /usr/local/bin/
cp -rp flanneld /usr/local/bin/
cp -rp mk-docker-opts.sh /usr/local/bin/-- 设置网关,参考命令:
route add default gw 192.168.43.1-- 去防火墙,参考命令:
systemctl stop firewalld.service
systemctl disable firewalld.service-- 启动docker后,立即关闭,这是为了让docker的网卡显示,然后关闭docker,等待flannel来设置docker的新网卡,参考命令:
service docker start
service docker stop-- 启动flannel,指定etcd的地址,以及说明使用的etcd前缀值,参考命令:
flanneld -etcd-endpoints=http://192.168.43.199:2379 -etcd-prefix=/coreos.com/network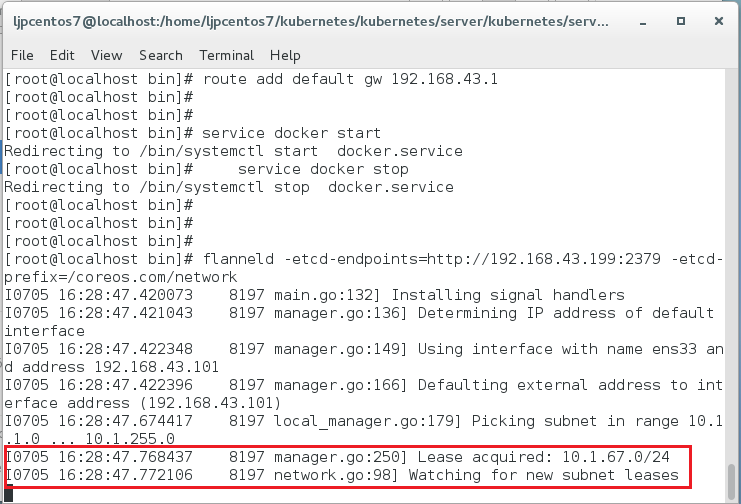
(成功设置了flannel的截图)
-- 重新规划docker的网络地址,参考命令:
mk-docker-opts.sh -i
source /run/flannel/subnet.env
ifconfig docker0 ${FLANNEL_SUBNET}-- 对于CentOS7 等默认安装的docker,还需要加入以下命令,新docker网卡才能起效,参考命令:
echo DOCKER_NETWORK_OPTIONS= --bip=${FLANNEL_SUBNET} > /etc/sysconfig/docker-network
systemctl daemon-reload-- 重启docker:
service docker restart
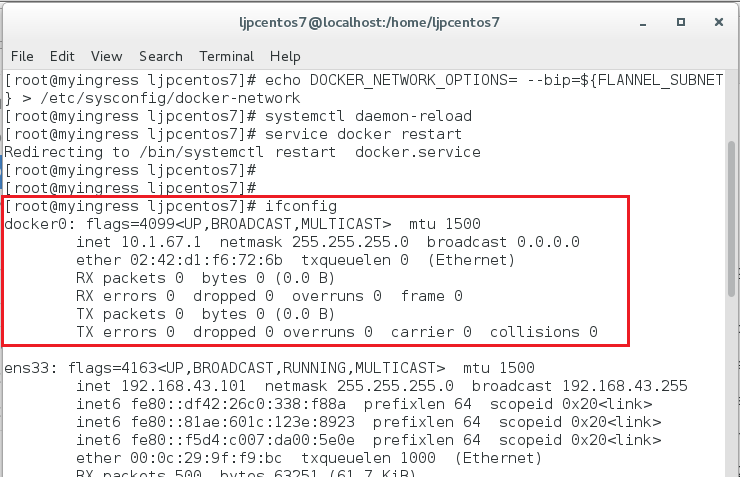 (成功设置docker的网络截图)
(成功设置docker的网络截图)
这样,docker就统一规划到flannel所指定的子网当中了。
-- 启动kubelet,指定apiserver地址,设置Node主机注册名,设置docker的启动驱动systemd,完成node注册,参考命令:
kubelet --api_servers=http://192.168.43.199:8080 --hostname-override=192.168.43.101 --cgroup-driver=systemd-- 启动kube-proxy,指定apiserver地址,参考命令:
kube-proxy --logtostderr=true --v=0 --master=http://192.168.43.199:8080
当我们三台node都成功设置好后,通过Master主机,就可以查询到nodes的状态了,参考命令:
kubectl get nodes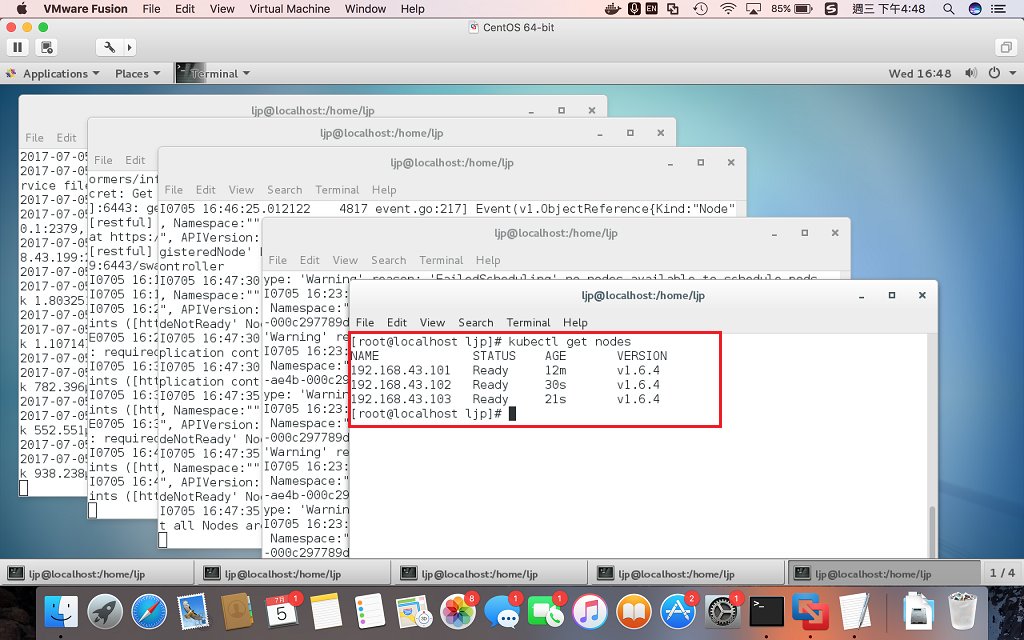 (master获取nodes状态截图)
(master获取nodes状态截图)
可以看到,我们设置的3台nodes都已经可以在Master主机查询到,并且状态为"Ready"。
当我们的kubernetes的分布式集群环境搭建好后,就可以开始创建相关的微服务Service了。
本章节当中的Service是一个建立在tomcat上的web应用,访问该Service的时候,会返回服务器的IP地址和Mac地址。
在本例中,该Service通过RC的设置,提供了3个Pod副本来提供真正的服务,所以每次访问该Service的时候,实际上是负载均衡到了后面的3个Pod中的其中一个来提供服务的。
这里,我们将建立一个包含3个Pod的RC,参考配置如下:
apiVersion: v1
kind: ReplicationController
metadata:
name: loadbalancetest1
spec:
replicas: 3
selector:
app: loadbalancetest
template:
metadata:
labels:
app: loadbalancetest
spec:
containers:
- name: loadbalancetest
image: docker.io/webin/loadbalancetest:1.0
ports:
- containerPort: 8080
hostPort: 8087这个配置的大致意思是:RC要求创建期望值数量为3的Pods,这些Pods是参考镜像“docker.io/webin/loadbalancetest:1.0”而创建的,并且带有标签“app: loadbalancetest”。同时RC通过selector也指定了集群中带有“app: loadbalancetest”标签的Pods,都归为它管理。
另外containerPort与hostPort,基本上等同于docker run -p 8087:8080 命令的作用,即指定好容器内和外的端口映射。但一般的,特别是要求大量副本的情况下,不建议设置hostPort,因为可能会导致Pod分配和转移的时候,分配到同一个node下导致端口冲突。
将上面的配置保存到一个文件后,就可以参考下面的命令将其运行起来:
kubectl create -f loadbalancetest-rc.yaml建立成功后,我们可以通过以下命令查阅rc,以及rc所创建的pods副本,参考命令如下:
kubectl get rc
kubectl get pods效果图如下:
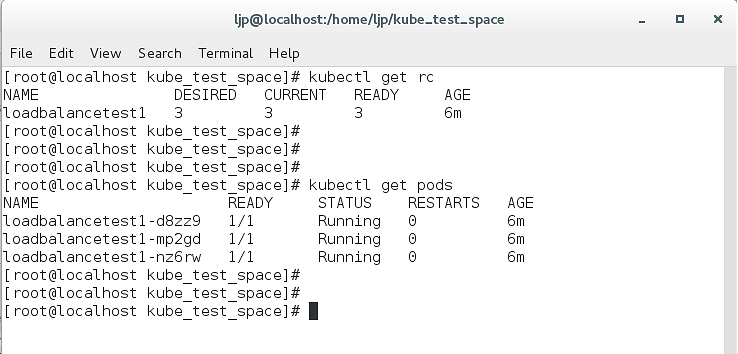
可以看到一个loadbalancetest的RC控制器的创建了三个Pod副本。
由于RC建立后,会立即创建Pod,所以我们可以直接跳过Pod的手动创建,直接进行Service的设置。
Service的参考配置如下:
piVersion: v1
kind: Service
metadata:
name: loadbalancetest
spec:
type: NodePort
ports:
- port: 8080
targetPort: 8080
nodePort: 30001
protocol: TCP
name: http
selector:
app: loadbalancetest这里的Service通过selector指定了特定的标签,意思是如果Pod中包含的标签与这里面的值相等,则视为是应该为该Service提供服务的Pod。
另外该配置文件出现了几个端口相关的配置:targetPort指出了Service要取Pod的container的服务端口,nodePort指Node主机可以通过该Port和Node主机的IP访问到container。而port参数则代表整个Service的端口。
将配置保存成文件,按下面的参考命令运行:
kubectl create -f loadbalancetest-svc.yaml成功建立好Service后,我们可以通过下面的命令查阅Service的信息:
kubectl get svc效果图如下:
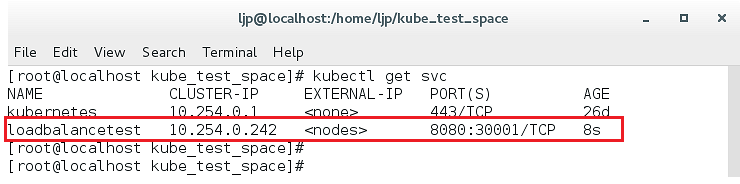
可以看到loadbalancetest的微服务Service已经建立好,并且被kubernetes分配了一个虚拟IP:10.254.0.242,以及把8080端口给到了这个Service,集群里面的资源包括Pod在内,都可以通过虚拟IP和端口进行对该服务的调用。另外的一个端口30001是创建Service的时候特地暴露出来,给外界访问的节点端口。可以通过nodeIP+nodePort的形式访问到一个Node上面的一个Service选中的Pod副本所提供的服务。
上一节的Service实际上是一个分布式容器云组成的一个微服务。
由于前面的RC设置了3个副本,而3个副本Pod都包含了Service的标签选择器所选择的标签“app: loadbalancetest”,所以之前RC建立的3个Pod都是为该Service而服务的。多副本的Service能让其更健壮,而且kubernetes的Service在多副本的情况下,还自带了负载均衡的效果,这也是微服务的一种体现。
我们可以通过下面的命令,更详细地查阅微服务Service的详细情况。 参考命令:
kubectl describe svc loadbalancetest效果图如下:
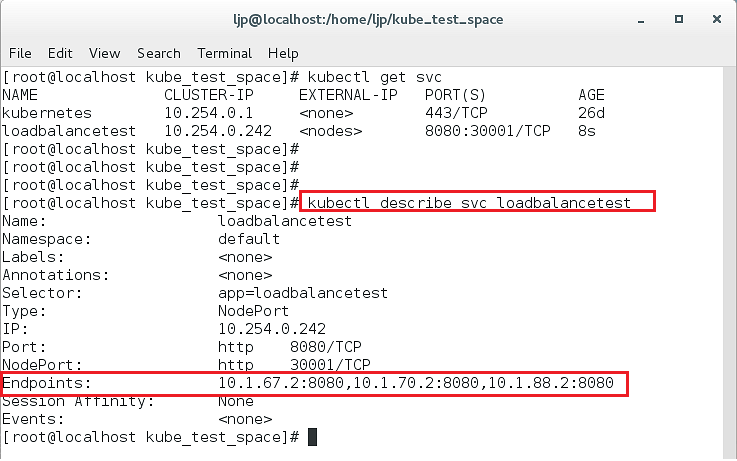
可以看出,一共有三个Endpoint: 10.1.67.2:8080,10.1.70.2:8080,10.1.88.2:8080
其实这些都是RC创建的三个Pod副本的IP地址和该服务的Container的8080端口组成的。
也就是实际上loadbalancetest这一个微服务Service,经过内置的负载均衡后最终是由这三个Pod来提供服务。
现在,我们可以先通过以下两种方式,尝试访问到为Service提供服务的container:
(1)通过node主机IP + nodePort,可以对外提供服务访问。


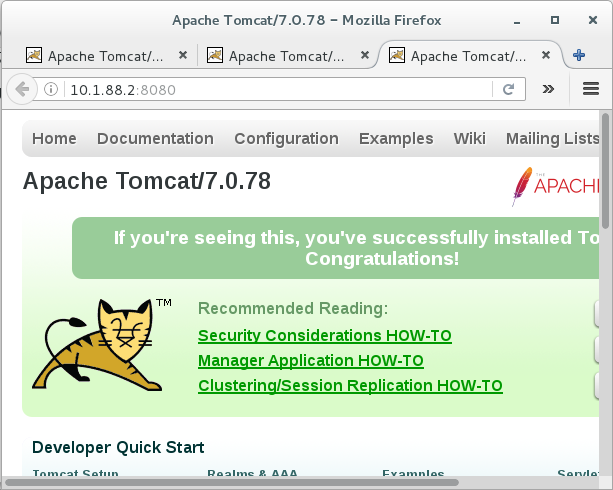
到目前为止,loadbalancetest的微服务Service已经建立好了,但由于Service属于Kubernetes内部资源,只能Kubernetes的内部才能访问,也就是外部是不能直接进行访问的,所以要测试该Service是否真的是负载均衡的,可以通过下一节的Nginx Ingress进行kubernetes资源的内外访问的代理。
本节将通过创建Ingress,使外界能通过URL地址访问到kubernetes微服务Service,验证Service的负载均衡。
default-http-backend是Nginx-ingress-controlloer的默认后端,该默认后端能检测Nginx的健康情况,以及当用户访问的url错误的时候,能返回404信息。参考的配置如下:
apiVersion: v1
kind: ReplicationController
metadata:
name: default-http-backend
spec:
replicas: 1
selector:
app: default-http-backend
template:
metadata:
labels:
app: default-http-backend
spec:
terminationGracePeriodSeconds: 60
containers:
- name: default-http-backend
# Any image is permissable as long as:
# 1. It serves a 404 page at /
# 2. It serves 200 on a /healthz endpoint
image: webin/defaultbackend:1.0
livenessProbe:
httpGet:
path: /healthz
port: 8080
scheme: HTTP
initialDelaySeconds: 30
timeoutSeconds: 10
ports:
- containerPort: 8080
hostPort: 8085
resources:
limits:
cpu: 10m
memory: 20Mi
requests:
cpu: 10m
memory: 20Mi将配置保存成文件,使用下面的参考命令运行:
kubectl create -f default-http-backend-rc.yaml默认后端的RC建立好了,我们再使用下面的简易命令将其创建成Service:
kubectl expose rc default-http-backend --port=80 --target-port=8080 --name=default-http-backend这个命令其实就相当于运行一个Service的yaml配置文件,创建Service。
效果图如下:

创建好后,我们可以在default-http-backend的Node主机上面直接通过的Podip/healthz或者serive的ip+port进行测试,如下图所示:
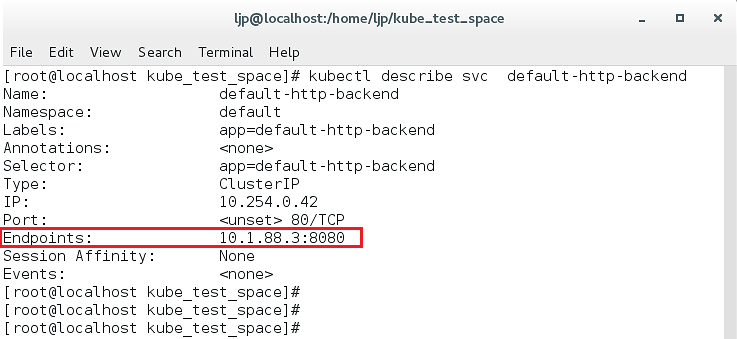

若能见到如上图返回的ok,则表示部署成功。
nginx-ingress-controller其实是一个Nginx,并且该Nginx带有Ingress的管理功能。参考配置如下:
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx-ingress-lb
labels:
name: nginx-ingress-lb
namespace: kube-system
spec:
replicas: 1
template:
metadata:
labels:
name: nginx-ingress-lb
spec:
terminationGracePeriodSeconds: 60
hostNetwork: true
containers:
- image: docker.io/webin/nginx-ingress-controller:0.8
name: nginx-ingress-lb
readinessProbe:
httpGet:
path: /healthz #定义ingress-controller自检的url 和端口
port: 80
scheme: HTTP
livenessProbe:
httpGet:
path: /healthz
port: 80
scheme: HTTP
initialDelaySeconds: 10
timeoutSeconds: 3
ports:
- containerPort: 80
hostPort: 80
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: KUBERNETES_MASTER
value: http://192.168.43.199:8080 #访问master 获取service信息
args:
- /nginx-ingress-controller
- --default-backend-service=default/default-http-backend保存成文件,然后使用下面的参考命令,把这个RC运行起来:
kubectl create -f nginx-ingress-rc.yaml这时候,我们可以查阅运行了nginx-ingress-controller的Pod详细情况,然后通过运行nginx-ingress-controller的那台Node机器,验证nginx-ingress-controller是否运行成功。
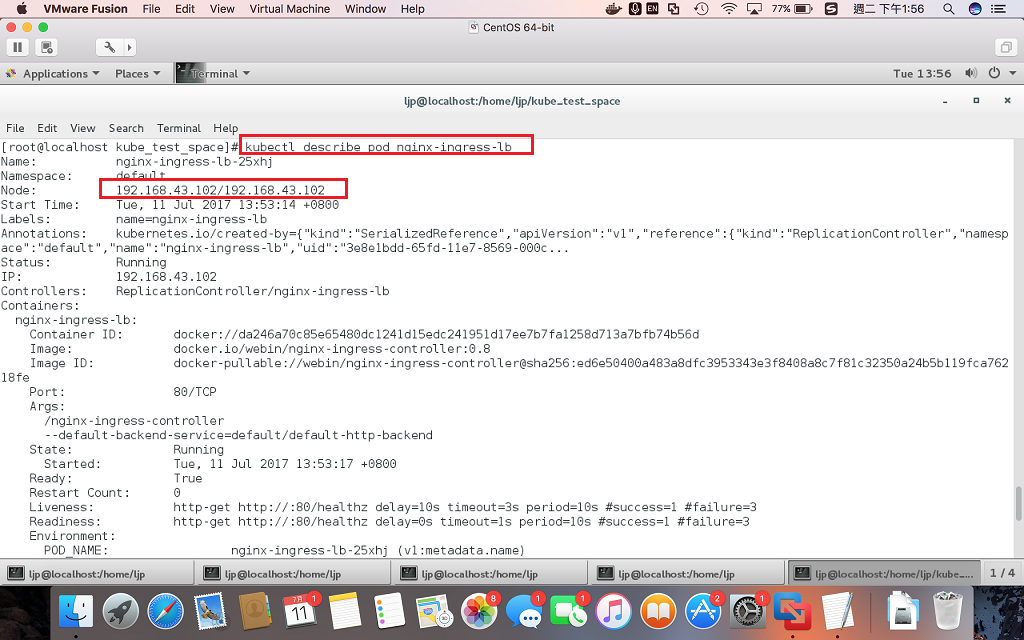
打开浏览器,输入该node的ip以及加上路径/healthz,如下图所示:
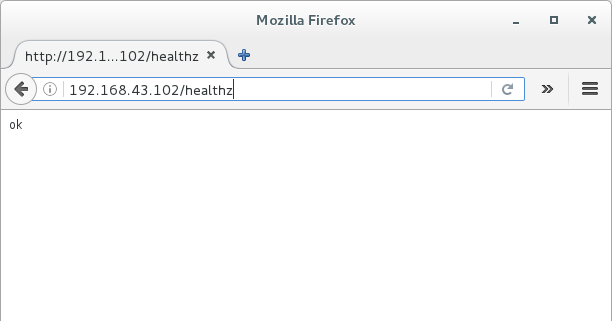
如果有返回ok则表示配置成功。
按下面的Ingress配置,创建url供外界访问,并且路由到一个Service上:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: myingress
spec:
rules:
- host: myingress.com
http:
paths:
- path: /LoadBalanceTest
backend:
serviceName: loadbalancetest
servicePort: 8080在要发起请求的机器中,去到/etc/hosts 文件新增内部的域名ip解析,把nginx-ingress-controller的nodeip与ingress的域名绑定:
192.168.43.102 myingress.com
其中192.168.43.102是指运行了nginx-ingress-controller的node机器的IP。
打开浏览器,发起访问,参考效果图如下:
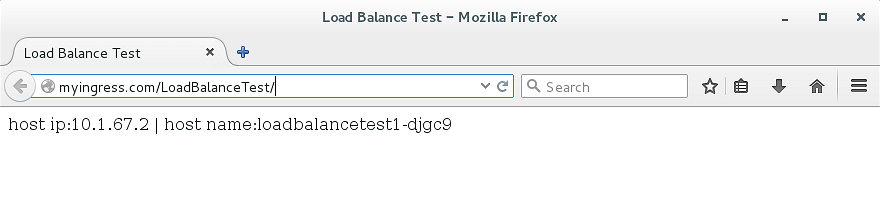

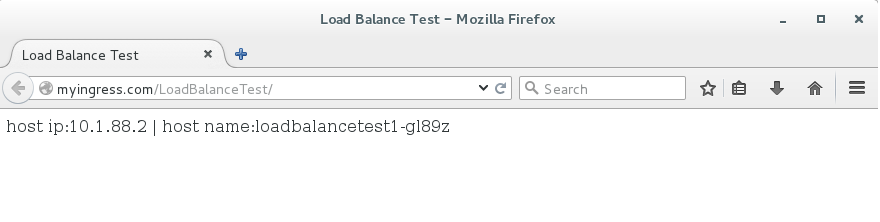
可以看出,对同一个URL地址发起的访问中,每次的访问返回的IP和主机名都与上一次的不同,而且是3个值循环地出现,这是因为这个URL对应的微服务Service是由3个Pod副本提供最终的运算的,这个也是Service内部负载均衡的体现。
前面几节中,我们完成了kubernetes分布式集群的搭建,以及运行了微服务Service,也通过了ingress验证了微服务Service的内置负载均衡。
在这个过程中,我们也使用了几个kubectl的命令,这些命令都是非常实用的,在这里我进行一个汇总:
kubectl的create命令,能创建pod,service,ingress等资源,一般使用这样的格式进行创建:
kubectl create -f 资源的yaml配置文件名如果有一些kubernetes资源不需要了,可以使用delete命令,一般的格式如下:
kubectl delete 资源类别 资源名称对于一些资源的配置更新,可以使用replace命令,一般格式如下:
kubectl replace -f 资源的yaml配置文件名
获取资源的信息,可以使用get,一般格式为:
kubectl get 资源类别 资源名称kubectl describe 资源类别 资源名称另外如果一些配置文件中,有写明命名空间的,则需要在查询的时候,加入--namespace参数。如果不加,默认查询和创建的都是default的命名空间下的资源。
对于CentOS7,在网络连接良好的情况下,使用一句命令,即可安装。参考命令如下:
yum -y install docker-io安装完成后,切换为root用户,然后启动docker即可。参考命令如下:
service docker start
docker的命令有十几种,但如果适当的分类,会非常容易记住。
一般刚安装的docker,本地是没有images可以运行的,所以需要到docker hub镜像登记中心(或者其他的非官方docker hub以及自建的docker hub中心)去获取。
首先,我们可以先进行images的拉取,参考命令:
docker pull hello-world
确保网络畅通的情况下,就能将该image “hello-world” download下来了。 一般的,docker pull 命令后面加 image地址,而images地址一般是“服务器/库/镜像名”这样的格式,上面的命令只写了镜像名hello-world,是因为省略服务器和库的情况下,docker会先自动去docker官方的docker hub登记中心中寻找,补充docker自己的服务器和库名,如下图所示:
如果你的镜像不是docker hub官方登记中心中的,就需要填写完整的路径。
同样的,既然有拉取,就会有对应的推送命令,即docker push 命令,但本小节不详细讲,这个将放入第三节的docker hub登记中心一并叙述。
docker中针对image的常用命令有:docker images 、docker rmi 、以及上一节的docker pull等。 查阅本地images,参考命令:
docker images
效果如下图所示:

这样就会列出当前该docker下所包含的本地images。
删除某个image, 参考命令:
docker rmi 1815c82652c0
或者
docker rmi hello-world:latest
效果图:
container是image的运行态。
docker中针对container的常用命令有:docker ps 、 docker run 、 docker rm 、 docker stop 、 docker kill等。 参考命令:
docker run hello-world

另外,我们还可以将一些container中运行的软件或进程,通过端口映射,如 -p 8080:80,将其80端口映射到外部的8080端口,暴露给外界,这样外界就能使用暴露的端口来访问container内部端口所对应的进程了。 以下是一个container运行的时候,将内部端口8080映射到外部端口8081的例子,参考代码:
docker run -p 8081:8080 docker.io/tomcat:V8
效果如下图所示:
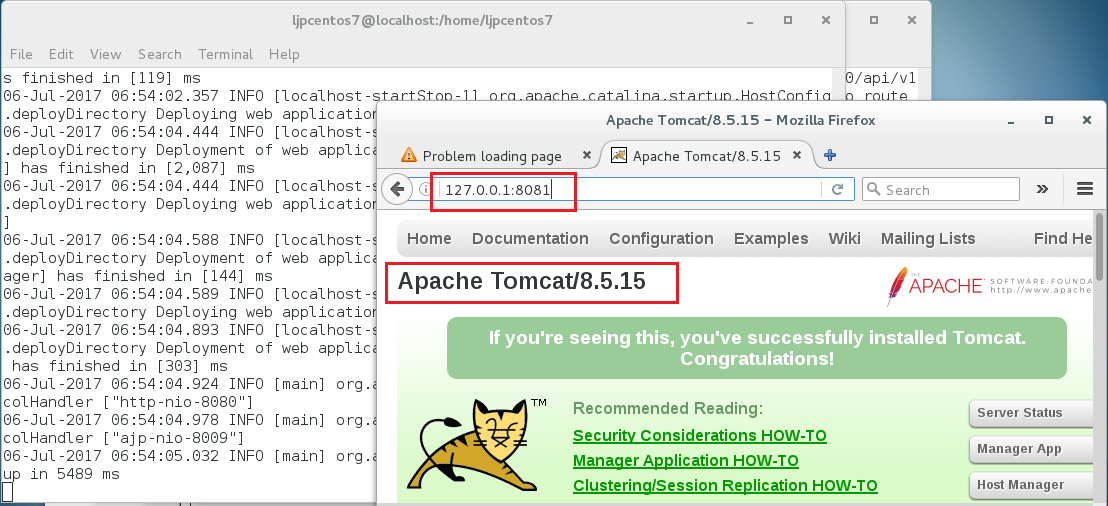
可以看到,运行完该docker命令后,在本机器内,可以通过127.0.0.1 + 8081端口,访问到tomcat,而这个tomcat,实际上是docker的一个container提供的服务,tomcat在这个container中(该container内部已经包含了一个linux系统的image),其实是通过8080端口对内提供服务的。 参数 -p 8081:8080做到了内外端口映射的作用。
另外,如果本地的docker images中,包含了centos或者ubuntu这样的镜像,还可以通过这样的命令,运行并进入container下的centos/ubuntu中:
docker run -i -t centos /bin/bash
这样就能进入到container中的centos系统了。
查阅目前docker中的container,例如列出所有的container,参考命令:
docker ps -a
删除一个container, 参考命令:
docker rm 81346941533c
此外还可以使用以下命令,进行全部的container删除:
docker rm $(docker ps -a -q)有时候,container正在运行甚至对外提供TCP长连接的时候,我们不能随便进行docker rm操作,这时,我们需要先进行docker stop或者docker kill命令后,才能成功地进行docker rm操作。
参考命令:
docker stop 81346941533c
docker kill 81346941533c其中 docker stop系优雅停止一个container,其会发一则信号给到container,让其在一定时间内做好准备后关闭,而docker kill系立即杀掉进程,即立即停止。
前面的章节简单介绍docker拉取和推送image的时候,提到了一下docker hub登记中心,该中心是用于存放docker images,并登记相关信息例如版本号、简要描述等等,方便以后image的迁移或升级,复用等。
docker hub的官网地址: https://hub.docker.com/

docker hub 除了docker自己的官方docker hub外,还有许多其他公司自建的docker hub,甚至还对外开放,例如目前国内市场上的:
灵雀云(https://hub.alauda.cn/)
时速云(https://hub.tenxcloud.com/)
阿里巴巴的阿里云hub中心(https://dev.aliyun.com/search.html)
等等。
一般的,我们如果自己创建了一个image,感觉日后会经常用到,则可以上传到相关的docker hub中。步骤为:
(1)提交container或者运行dockerfile,将其变为一个本地的image。
(2)登录docker hub官网或者其他镜像登记中心,前提是你已经在此docker hub中心注册了。
(3)将本地的要上传的image打上tag,最主要是记录好image名以及版本号。
(4)使用docker push 命令,将镜像上传到该docker hub。
参考命令:
docker commit 21d2f661627f mytest/hello-world #提交一个container,变为一个image快照。
docker login #登录到docker hub 官网;如果是其他的docker hub中心,后面需要加服务器地址。
docker tag 94000117f92e username/hello-world:v1.0 #为准备上传的image打标签。
docker push username/hello-world:1.0 #将该image上传。docker中创建image的方法,除了pull远端的image,以及将container commit成image外,还可以通过dockerfile来创建,这样的创建方法,能在自动化运维中,起到良好的体验。这里简单介绍一下通过dockerfile创建image的方法。
首先我们要在一个自己的测试路径下面,建立一个名为“dockerfile”的文件,该文件不需要后缀名。参考代码:
touch dockerfile将以下代码写入到该文件中:
FROM jenkins
USER root
RUN apt-get update \
&& apt-get install -y sudo \
&& rm -rf /var/lib/apt/lists/*
RUN echo "jenkins ALL=NOPASSWD: ALL">在当前目录下输入以下命令:
docker build -t myjenkins .
这时候,docker系统将会按照dockerfile的定义一步一步往下走。效果图如下:
完成后,就可以通过docker images 命令看到该image了。

看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/2600078/blog/1359379



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



