这篇文章给大家分享的是有关Mapreduce shuffle的示例分析的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
Mapreduce shuffle详解
Mapreduce确保每个reducer的的输入都是按键排序的。系统执行排序的过程(即将map输出作为输入 传给reducer)成为shuffle。从多个方面来看shuffle是mapreduce的心脏,是奇迹发生的地方。
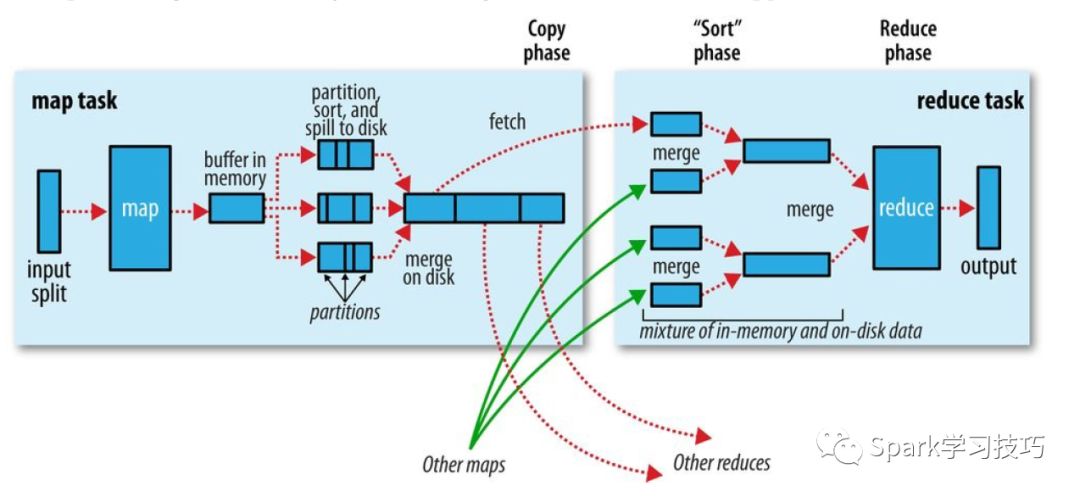
上图展示了,mapreduce的详细过程。
1 输入分片
对于数据的输入分片,要根据不同的存储格式有不同的介绍。对于,hdfs存储的文件,数据的分片就可分为两种,文件可切分(不压缩或者压缩格式bzip2)的按照一定大小进行分片有既定算法,默认是block的大小,具体算法不在这里细讲,前面hive调优的文章又说到,而且浪尖也会在后续的文章提到这个内容;

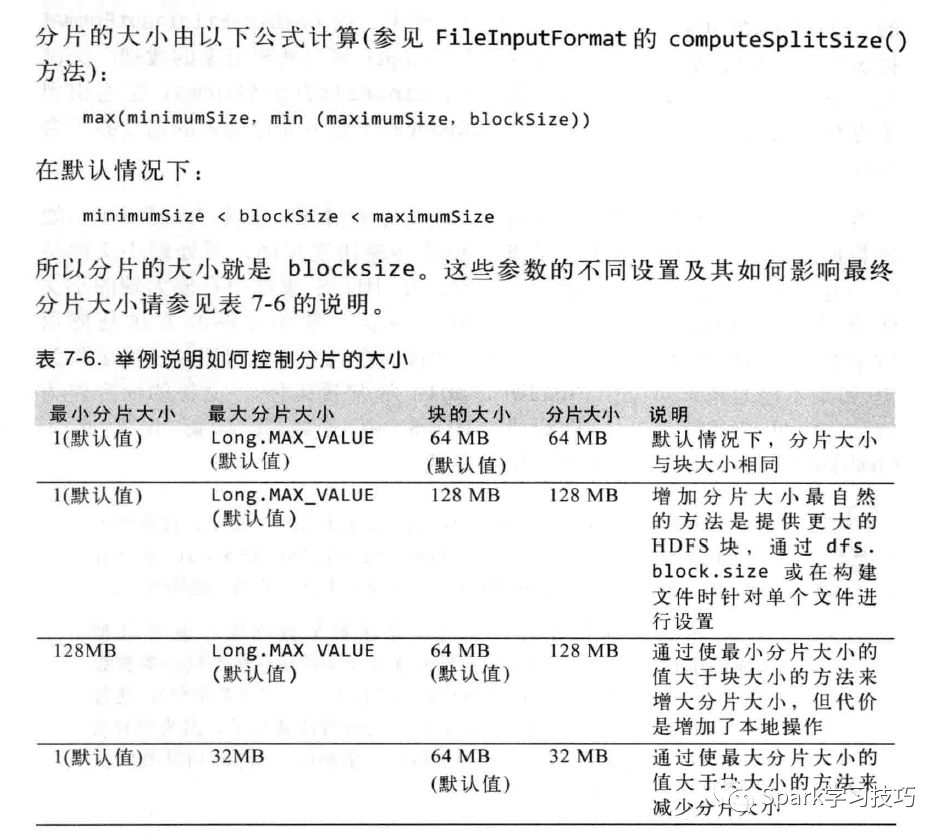
分片的时候计算公式计算过程举例
文件不可切分则一个文件一个分片。
2 Map端
从上图我们可以看到map端的处理过程。Map会读取输入分片数据。但是map函数开始产生输出时并不是简单的将数据写入磁盘。这个过程很复杂,他利用了缓冲的方式写到内存并出于效率的考虑进行排序。
每个map任务都是有一个环形缓冲区的用于存储任务的输出。在默认情况下,缓冲区的大小为100MB,辞职可以通过改变io.sort.mb来调整。一旦缓冲内容达到阈值(io.sort,spill,percent,默认是0.8),一个后台线程会将内容spill到磁盘。在spill到磁盘的过程中,map输出并不会停止往缓冲区写入数据,但如果在此期间缓冲区被写满,map会被阻塞知道写磁盘过程完成。
溢出写过程安装轮询方式将缓冲区的内容写到mapred.local.dir指定的作业特定子目录中的目录中。
写磁盘之前,线程首先根据数据最终要传的reducer把数据划分成相应的分区。在每个分区中后台线程按键进行内排序,如果有一个combiner,它就在排序后的输出上运行。运行combinner使得map输出结果更紧凑,因此可以减少写到磁盘的数据和传递给reducer的数据。
每次内存缓冲区达到溢出阈值,就会新建一个溢出文件(spill file),因此在map任务写完其最后一个输出记录之后,会有几个溢写文件。在任务完成之前,溢出文件被合并成一个已分区且已排序的输出文件。配置属性io.sort.factor控制着一次最多能合并多少流,默认是10。
如果至少存在3个溢出文件(通过min.num.spills.for.combine属性设置)时,则combiner就会在输出文件写到磁盘之前再次运行。前面曾说过,combiner可以在输入上反复运行,单不影响最终的结果。如果只有一两个溢出文件,那么对map输出的减少不值得调用combiner,就不会为map输出再次运行combiner。
在将压缩map输出写到磁盘的过程中对它进行压缩往往是个好主意,因为这样就会写磁盘的速度更快,更加节约时间,并且减少传给reducer的数据量。在默认情况下,输出是不压缩的,但是只要将mapred.compress.map.output设置为true,就可以启用这个功能。使用的压缩库由mapred.map.output.compression.codec指定。
Reducer是通过HTTP的方式得到输出文件的分区。在MRV2中使用netty进行数据传输,默认情况下netty的工作线程数是处理器数的2倍。MRV1中,默认值是40,由tracker.http.threads来在tasktracker端设定。
3 Reducer端
集群中往往一个mr任务会有若干map任务和reduce任务,map任务运行有快有慢,reduce不可能等到所有的map任务都运行结束再启动,因此只要有一个任务完成,reduce任务就开始复制器输出。复制线程的数量由mapred.reduce.parallel.copies属性来改变,默认是 5。
Reducer如何知道map输出的呢?对于MRv2 map运行结束之后直接就通知了appmaster,对于给定的job appmaster是知道map的输出和host之间的关系。在reduce端获取所有的map输出之前,Reduce端的线程会周期性的询问master 关于map的输出。Reduce并不会在获取到map输出之后就立即删除hosts,因为reduce有肯能运行失败。相反,是等待appmaster的删除消息来决定删除host。
Reduce对map输出的不同大小也有相应的调优处理。如果map输出相当小,会被复制到reduce任务JVM的内存(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,指定用于此用途的堆空间的百分比),否则,map输出会被复制到磁盘。一旦内存缓冲区达到阈值(由mapred.job.shuffle.merge.percent决定)或达到map的输出阈值(mapred.inmem.merge,threshold控制),则合并后溢出写到磁盘中。如果指定combiner,则在合并期间运行它已降低写入磁盘的数据量。
随着磁盘上副本的增多,后台线程会将它们合并为更大的,排序好的文件。这会为后面的合并节省一些时间。注意,为了合并,压缩的map输出(通过map任务)都必须在内存中解压缩。
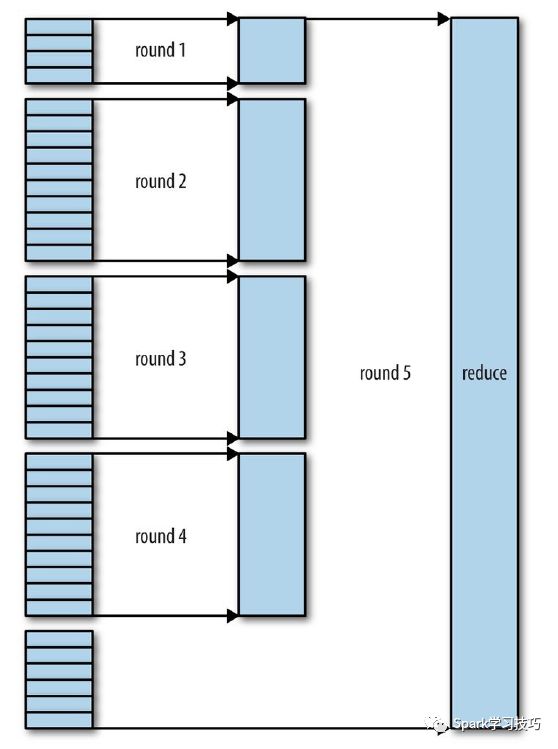
复制完所有的map输出后,reduce任务进入排序阶段(更加恰当的说法是合并阶段,因为排序是在map端进行的),这个阶段将合并map的输出,维持其顺序排序。这是循环进行的。比如,有50个map输出,而合并因子是10(默认值是10,由io.sort.factor属性设置,与map的合并类似),合并将进行5趟。每趟将10个文件合并成一个文件,因此最后有5个中间文件。
在最后阶段,即reduce阶段,直接把数据输入reduce函数,从而省略了一次磁盘往返行程,并没有将这5个文件合并成一个已排序的文件最为最后一趟。最后的合并可以来自内存和磁盘片段。
在reduce阶段,对已排序输出中的每个键调用reduce函数。此阶段的输出直接写到输出文件系统,一般为hdfs。
注意:
每趟合并的文件数实际上比上面例子中展示的有所不同的。目标是合并最小数据量的文件以便满足最后一趟的合并系数。因此,如果有40个文件,我们不会再四趟中每趟合并10个文件而得到4个文件。相反,第一趟只合并4个文件,随后的三塘合并10个文件。最后一趟中,4个已经合并的文件和剩余的6个文件合计是个文件进行合并。如下图所述:
注意这并没有改变合并的次数,它只是一个优化措施,目的是尽量减少写到磁盘的数据量,因为最后一趟总是直接合并到reduce。
感谢各位的阅读!关于“Mapreduce shuffle的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4590259/blog/4600913



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



